Anchor-based Large Language Models
2402.07616
0
0
💬
Abstract
Large language models (LLMs) predominantly employ decoder-only transformer architectures, necessitating the retention of keys/values information for historical tokens to provide contextual information and avoid redundant computation. However, the substantial size and parameter volume of these LLMs require massive GPU memory. This memory demand increases with the length of the input text, leading to an urgent need for more efficient methods of information storage and processing. This study introduces Anchor-based LLMs (AnLLMs), which utilize an innovative anchor-based self-attention network (AnSAN) and also an anchor-based inference strategy. This approach enables LLMs to compress sequence information into an anchor token, reducing the keys/values cache and enhancing inference efficiency. Experiments on question-answering benchmarks reveal that AnLLMs maintain similar accuracy levels while achieving up to 99% keys/values cache reduction and up to 3.5 times faster inference. Despite a minor compromise in accuracy, the substantial enhancements of AnLLMs employing the AnSAN technique in resource utilization and computational efficiency underscore their potential for practical LLM applications.
Create account to get full access
Overview
- Large language models (LLMs) use a type of architecture called decoder-only transformers, which require storing information from previous tokens to provide context and avoid redundant computations.
- However, the large size and high parameter count of these LLMs leads to massive GPU memory demands, especially as the input text length increases.
- This paper introduces Anchor-based LLMs (AnLLMs), which utilize an innovative anchor-based self-attention network (AnSAN) and anchor-based inference strategy to compress sequence information and reduce the keys/values cache, enhancing inference efficiency.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models use a particular architecture called a "decoder-only transformer," which means they process text one word at a time, while remembering information from previous words to provide context.
However, the massive size and complexity of LLMs require a lot of computer memory, especially as the input text gets longer. This memory demand limits the practical applications of these models.
To address this issue, the researchers in this study developed a new type of LLM called an "Anchor-based LLM" (AnLLM). AnLLMs use a novel "anchor-based self-attention network" (AnSAN) and an "anchor-based inference strategy" to compress the information needed from previous words, reducing the memory requirements.
Through experiments, the researchers found that AnLLMs can maintain similar accuracy to traditional LLMs while using up to 99% less memory and running up to 3.5 times faster. This significant improvement in efficiency and resource utilization could make LLMs more practical for real-world applications, such as efficient economic large language model inference or attention-driven reasoning to unlock the potential of large language models.
Technical Explanation
The key innovation in this paper is the introduction of Anchor-based LLMs (AnLLMs), which leverage an anchor-based self-attention network (AnSAN) and anchor-based inference strategy to address the memory and computational challenges of traditional LLMs.
The AnSAN module compresses the sequence information into an "anchor token," which serves as a compact representation of the contextual history. This allows the model to significantly reduce the size of the keys/values cache required for self-attention, leading to substantial memory savings.
The anchor-based inference strategy further enhances efficiency by only updating the anchor token during inference, rather than the entire sequence. This avoids the need to recompute the keys/values for all previous tokens, resulting in faster inference times.
The researchers evaluated AnLLMs on popular question-answering benchmarks and found that they maintained similar accuracy levels to traditional LLMs, while achieving up to 99% reduction in keys/values cache size and up to 3.5 times faster inference. This demonstrates the potential of anchor-based techniques for efficient and effective large language model inference.
Critical Analysis
The paper presents a promising approach to addressing the memory and computational challenges of large language models. The anchor-based techniques introduced, such as the AnSAN and anchor-based inference, appear to be effective in reducing the resource demands of LLMs without significantly compromising their performance.
However, the paper does mention a minor compromise in accuracy for the AnLLM models. While the trade-off between efficiency and accuracy is reasonable, it would be valuable to further explore methods to minimize this accuracy degradation, perhaps through adaptive techniques for lossless acceleration of large language models.
Additionally, the paper focuses on question-answering tasks, and it would be beneficial to assess the performance of AnLLMs on a broader range of language tasks, including multimodal applications where visual anchors can be strong information aggregators. This would provide a more comprehensive understanding of the capabilities and limitations of the proposed approach.
Conclusion
The Anchor-based LLM (AnLLM) introduced in this paper represents a significant advancement in addressing the memory and computational challenges of large language models. By leveraging innovative anchor-based techniques, such as the AnSAN and anchor-based inference, AnLLMs demonstrate the ability to maintain similar accuracy while achieving substantial reductions in memory usage and inference time.
This efficiency improvement could enable the practical deployment of LLMs in a wider range of applications, from efficient economic large language model inference to attention-driven reasoning to unlock the potential of large language models. The findings in this paper highlight the ongoing progress in developing more efficient and effective large language model architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis
0
0
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. Window attention, where only the most recent KVs are cached, is a natural approach -- but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a sink even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence lengths without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup. Code and datasets are provided at https://github.com/mit-han-lab/streaming-llm.
4/9/2024
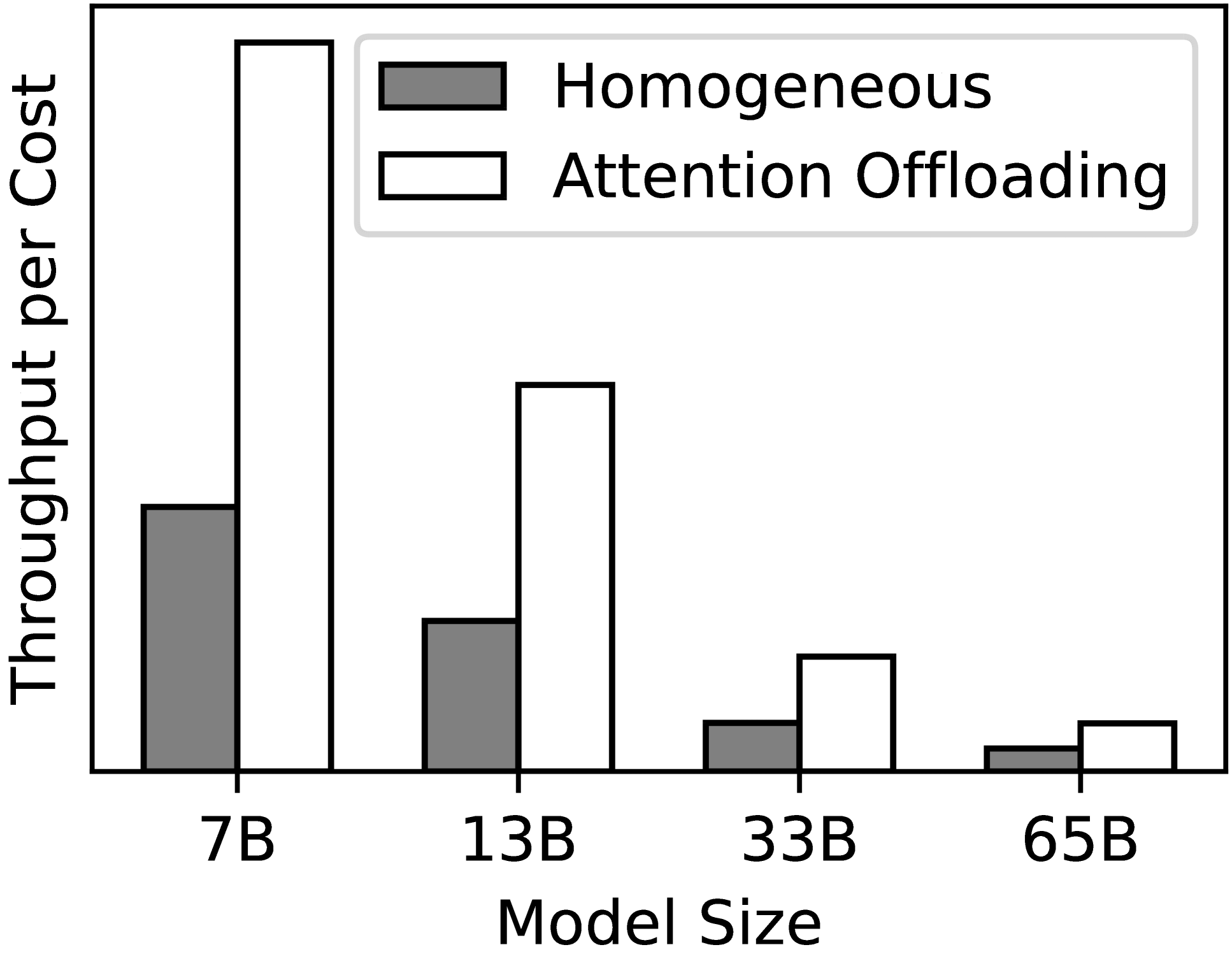
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024
Attention-Driven Reasoning: Unlocking the Potential of Large Language Models
Bingli Liao, Danilo Vasconcellos Vargas
0
0
Large Language Models (LLMs) are pivotal in advancing natural language processing but often struggle with complex reasoning tasks due to inefficient attention distributions. In this paper, we explore the effect of increased computed tokens on LLM performance and introduce a novel method for extending computed tokens in the Chain-of-Thought (CoT) process, utilizing attention mechanism optimization. By fine-tuning an LLM on a domain-specific, highly structured dataset, we analyze attention patterns across layers, identifying inefficiencies caused by non-semantic tokens with outlier high attention scores. To address this, we propose an algorithm that emulates early layer attention patterns across downstream layers to re-balance skewed attention distributions and enhance knowledge abstraction. Our findings demonstrate that our approach not only facilitates a deeper understanding of the internal dynamics of LLMs but also significantly improves their reasoning capabilities, particularly in non-STEM domains. Our study lays the groundwork for further innovations in LLM design, aiming to create more powerful, versatile, and responsible models capable of tackling a broad range of real-world applications.
6/26/2024

When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
Haoran You (Celine), Yichao Fu (Celine), Zheng Wang (Celine), Amir Yazdanbakhsh (Celine), Yingyan (Celine), Lin
0
0
Autoregressive Large Language Models (LLMs) have achieved impressive performance in language tasks but face two significant bottlenecks: (1) quadratic complexity in the attention module as the number of tokens increases, and (2) limited efficiency due to the sequential processing nature of autoregressive LLMs during generation. While linear attention and speculative decoding offer potential solutions, their applicability and synergistic potential for enhancing autoregressive LLMs remain uncertain. We conduct the first comprehensive study on the efficacy of existing linear attention methods for autoregressive LLMs, integrating them with speculative decoding. We introduce an augmentation technique for linear attention that ensures compatibility with speculative decoding, enabling more efficient training and serving of LLMs. Extensive experiments and ablation studies involving seven existing linear attention models and five encoder/decoder-based LLMs consistently validate the effectiveness of our augmented linearized LLMs. Notably, our approach achieves up to a 6.67 reduction in perplexity on the LLaMA model and up to a 2$times$ speedup during generation compared to prior linear attention methods. Codes and models are available at https://github.com/GATECH-EIC/Linearized-LLM.
6/12/2024