Attention-Driven Reasoning: Unlocking the Potential of Large Language Models
2403.14932
0
0
Abstract
Large Language Models (LLMs) are pivotal in advancing natural language processing but often struggle with complex reasoning tasks due to inefficient attention distributions. In this paper, we explore the effect of increased computed tokens on LLM performance and introduce a novel method for extending computed tokens in the Chain-of-Thought (CoT) process, utilizing attention mechanism optimization. By fine-tuning an LLM on a domain-specific, highly structured dataset, we analyze attention patterns across layers, identifying inefficiencies caused by non-semantic tokens with outlier high attention scores. To address this, we propose an algorithm that emulates early layer attention patterns across downstream layers to re-balance skewed attention distributions and enhance knowledge abstraction. Our findings demonstrate that our approach not only facilitates a deeper understanding of the internal dynamics of LLMs but also significantly improves their reasoning capabilities, particularly in non-STEM domains. Our study lays the groundwork for further innovations in LLM design, aiming to create more powerful, versatile, and responsible models capable of tackling a broad range of real-world applications.
Create account to get full access
Overview
- This paper explores a novel approach called "Attention-Driven Reasoning" that aims to unlock the potential of large language models (LLMs) for more effective and interpretable reasoning.
- The key idea is to leverage the attention mechanism in LLMs to guide the model's reasoning process, leading to improved performance on complex reasoning tasks.
- The researchers propose a structured data alignment technique to mitigate the inherent complexity of LLMs and enhance their reasoning capabilities.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown remarkable abilities in various language tasks, but their reasoning capabilities can often be opaque and difficult to control. This paper presents a novel approach called "Attention-Driven Reasoning" that aims to make LLMs more effective and understandable when it comes to complex reasoning tasks.
The core idea is to use the attention mechanism within the LLM - the way the model focuses on different parts of its input when generating output - to guide the model's reasoning process. By aligning the model's attention with structured data, the researchers believe they can help the LLM reason in a more interpretable and effective way.
The paper outlines a technique called "structured data alignment" that helps mitigate the inherent complexity of LLMs and enhances their reasoning abilities. This could lead to LLMs that are better able to tackle tasks requiring deep logical reasoning, while also making their inner workings more transparent to researchers and users.
The potential implications of this research include link to "Beyond Accuracy: Evaluating Reasoning Behavior in Large Language Models" and link to "Can Small Language Models Help Large Language" - improvements in the reasoning capabilities and interpretability of LLMs, which could have far-reaching impacts in areas like link to "Enhancing General Agent Capabilities with Low-Parameter LLMs", link to "Enhance Reasoning in Large Language Models for the Game Werewolf", and link to "Large Language Models for Mathematical Reasoning: Progresses and Challenges".
Technical Explanation
The paper proposes a novel approach called "Attention-Driven Reasoning" to enhance the reasoning capabilities of large language models (LLMs). The key innovation is the use of the attention mechanism within the LLM to guide the model's reasoning process.
Specifically, the researchers introduce a "structured data alignment" technique that aims to mitigate the inherent complexity of LLMs. By aligning the model's attention with structured data, such as knowledge graphs or logical rules, the approach helps the LLM reason in a more interpretable and effective way.
The paper discusses the experimental design and architecture of the proposed system. The authors evaluate their approach on a range of complex reasoning tasks and demonstrate significant improvements in performance compared to standard LLM baselines.
The key insights from the technical analysis include the potential of attention-driven reasoning to enhance the interpretability and reasoning capabilities of LLMs, as well as the effectiveness of the structured data alignment technique in guiding the model's reasoning process.
Critical Analysis
The paper presents a promising approach to improving the reasoning capabilities of large language models, but it also raises some important caveats and areas for further research.
One potential limitation is the reliance on structured data alignment, which may not always be readily available or easy to construct, especially for more open-ended reasoning tasks. The paper acknowledges this challenge and suggests further work on techniques to automatically extract or infer the necessary structured data from text.
Additionally, while the experiments demonstrate improvements in reasoning performance, the paper does not provide a comprehensive analysis of the model's behavior and the extent to which the attention-driven approach truly enhances interpretability. Further research is needed to better understand the inner workings of the model and the factors that contribute to its reasoning capabilities.
Another area for further exploration is the generalization of the approach to a wider range of reasoning tasks and domains. The paper focuses primarily on a limited set of benchmarks, and it would be valuable to assess the scalability and robustness of the attention-driven reasoning approach in more diverse and challenging scenarios.
Despite these caveats, the paper presents a compelling and innovative direction for improving the reasoning capabilities of large language models, which could have significant implications for various applications that require advanced logical reasoning and interpretability.
Conclusion
This paper introduces a novel "Attention-Driven Reasoning" approach that aims to unlock the potential of large language models (LLMs) for more effective and interpretable reasoning. By leveraging the attention mechanism within LLMs and aligning it with structured data, the researchers demonstrate improved performance on complex reasoning tasks.
The key contributions of this work include the structured data alignment technique to mitigate the inherent complexity of LLMs, as well as the potential for attention-driven reasoning to enhance the interpretability and reasoning capabilities of these powerful language models.
While the paper presents promising results, it also highlights areas for further research, such as the scalability of the approach, the need for more comprehensive interpretability analysis, and the exploration of a wider range of reasoning tasks and domains.
Overall, this research represents an important step towards developing LLMs that can engage in more transparent and effective reasoning, with far-reaching implications for various applications that rely on advanced logical reasoning and decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024
A Peek into Token Bias: Large Language Models Are Not Yet Genuine Reasoners
Bowen Jiang, Yangxinyu Xie, Zhuoqun Hao, Xiaomeng Wang, Tanwi Mallick, Weijie J. Su, Camillo J. Taylor, Dan Roth
0
0
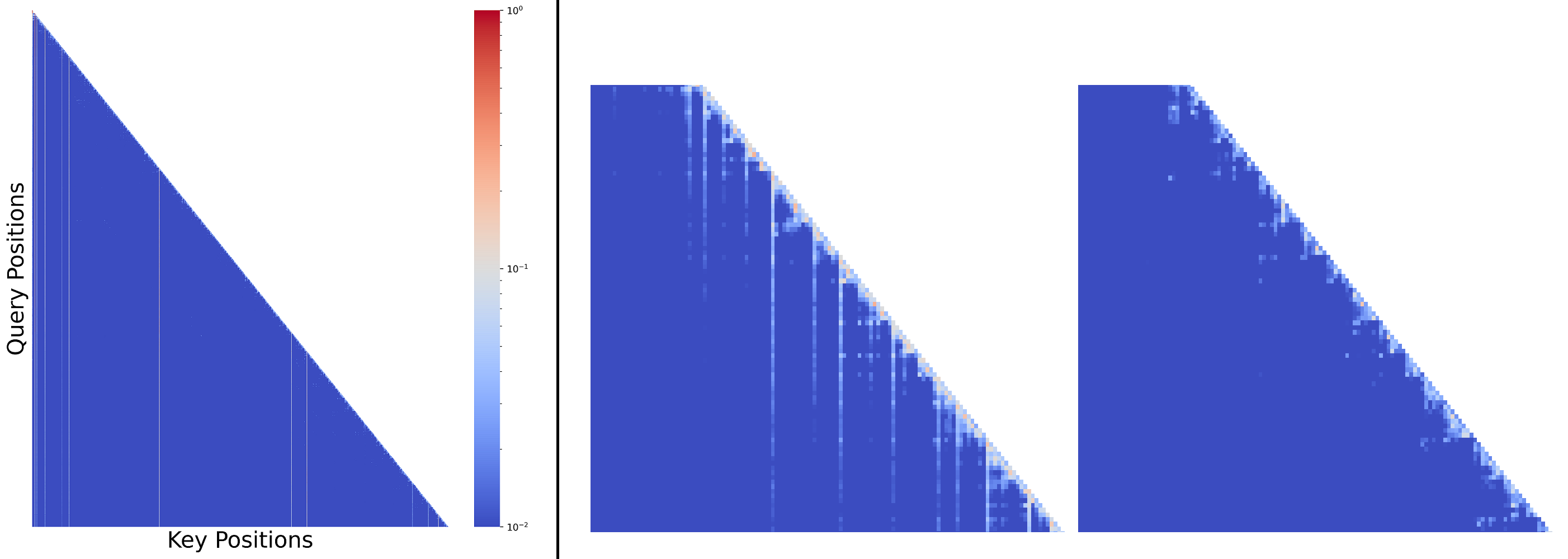
This study introduces a hypothesis-testing framework to assess whether large language models (LLMs) possess genuine reasoning abilities or primarily depend on token bias. We go beyond evaluating LLMs on accuracy; rather, we aim to investigate their token bias in solving logical reasoning tasks. Specifically, we develop carefully controlled synthetic datasets, featuring conjunction fallacy and syllogistic problems. Our framework outlines a list of hypotheses where token biases are readily identifiable, with all null hypotheses assuming genuine reasoning capabilities of LLMs. The findings in this study suggest, with statistical guarantee, that most LLMs still struggle with logical reasoning. While they may perform well on classic problems, their success largely depends on recognizing superficial patterns with strong token bias, thereby raising concerns about their actual reasoning and generalization abilities.
6/18/2024
Probabilistic Reasoning in Generative Large Language Models
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
0
0
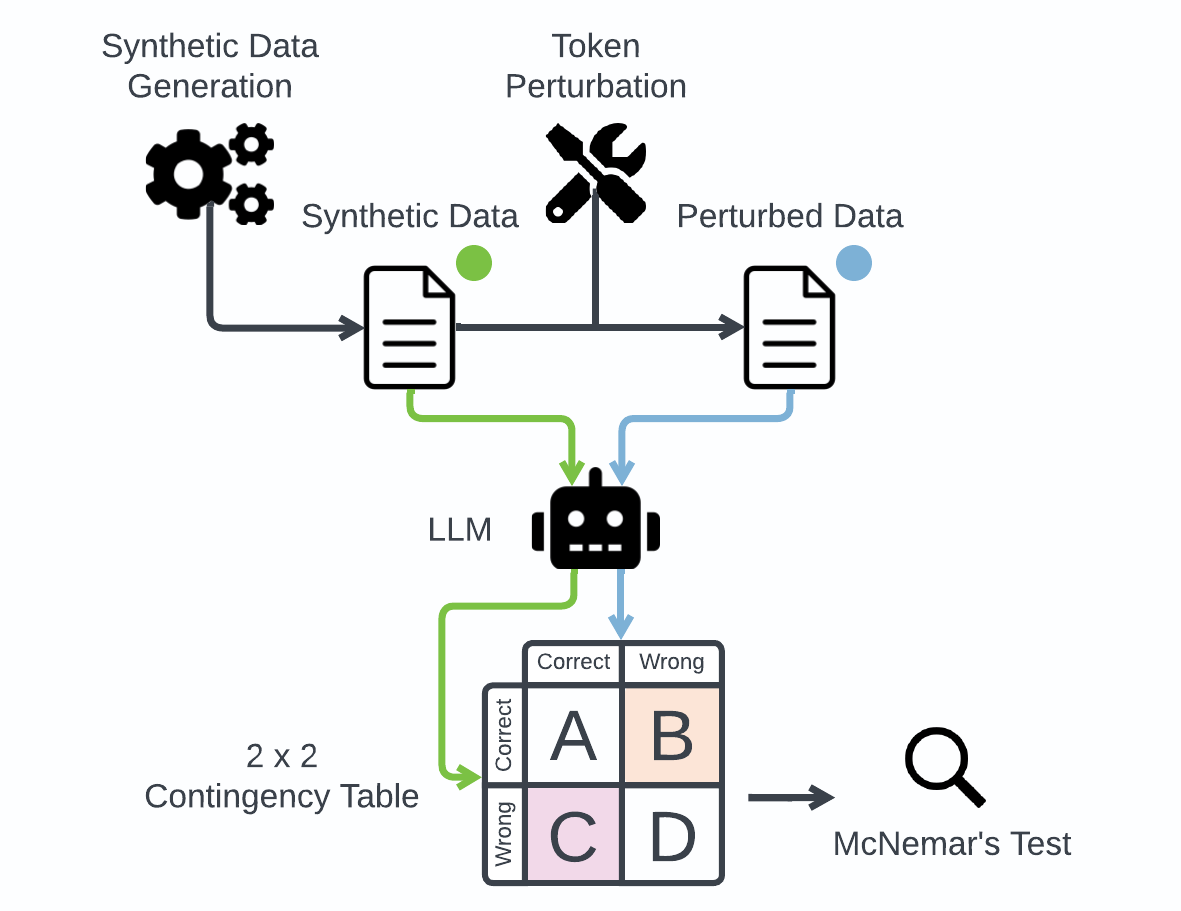
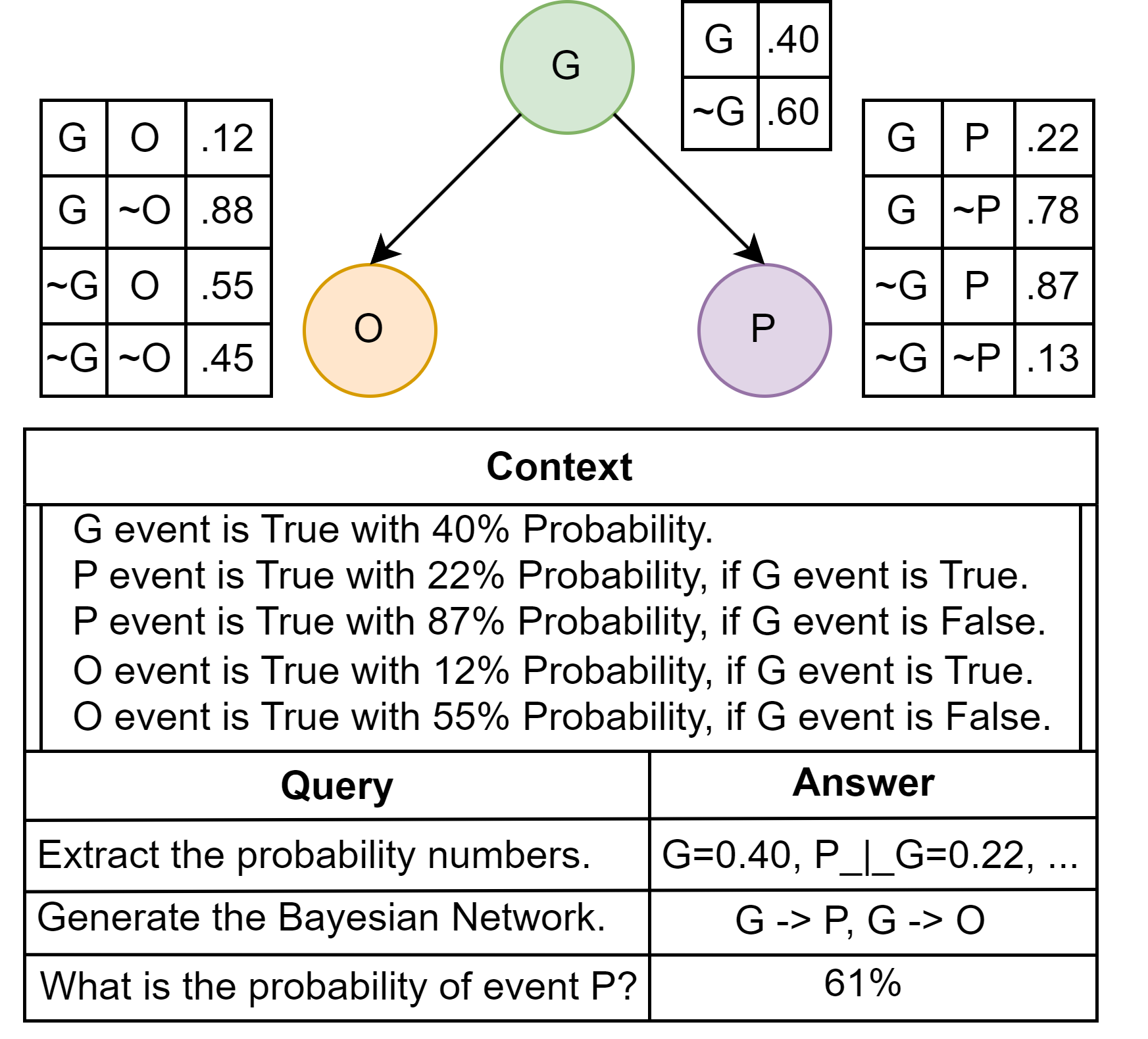
This paper considers the challenges Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We use BLInD to find out the limitations of LLMs for tasks involving probabilistic reasoning. In addition, we present several prompting strategies that map the problem to different formal representations, including Python code, probabilistic algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and an adaptation of a causal reasoning question-answering dataset. Our empirical results highlight the effectiveness of our proposed strategies for multiple LLMs.
6/18/2024
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
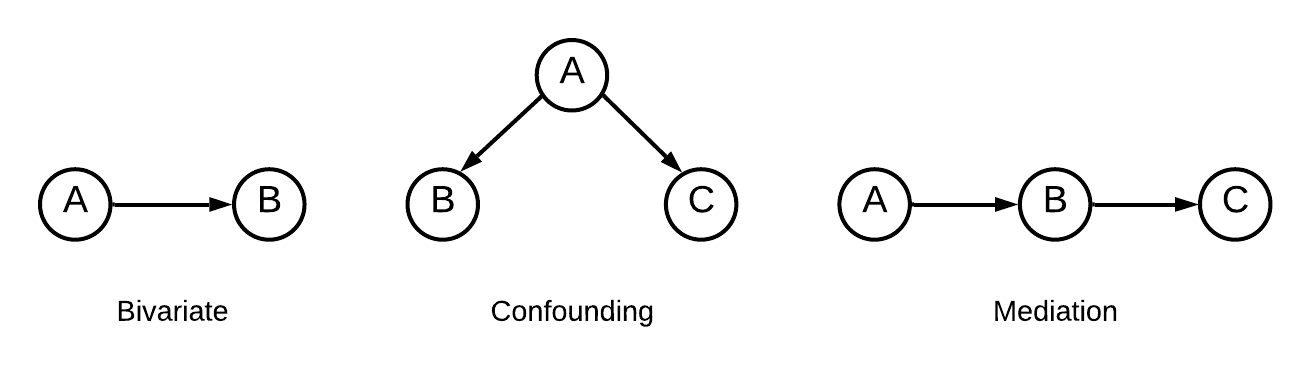
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024