APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets

0
🖼️
Sign in to get full access
Overview
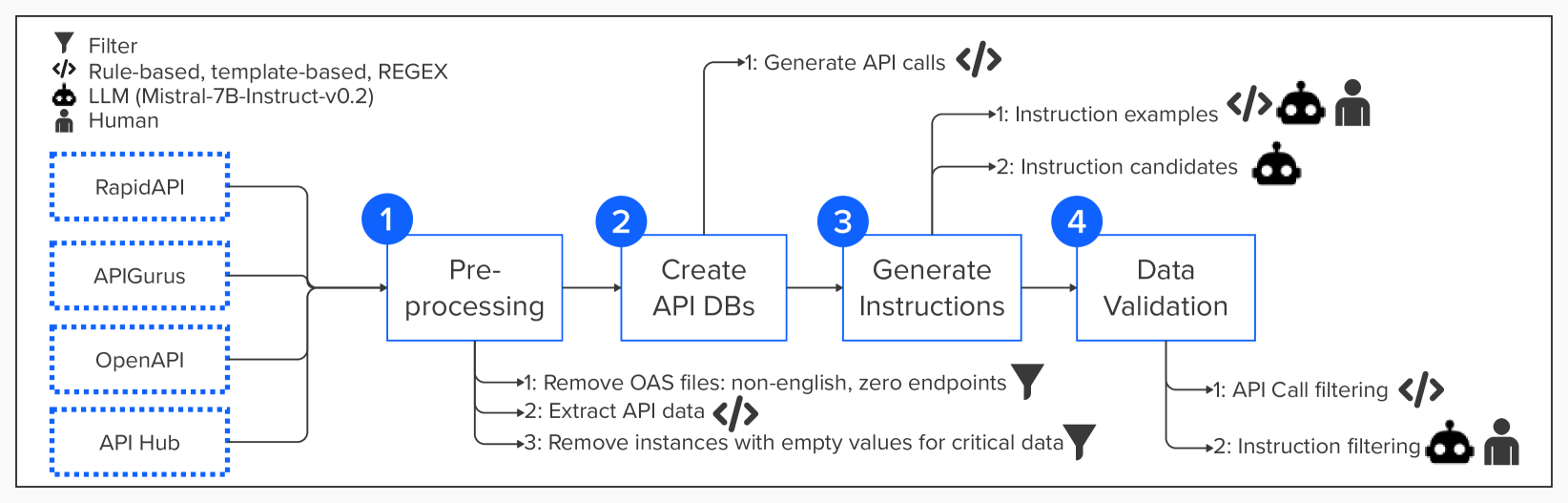
- This research paper presents APIGen, an automated data generation pipeline designed to create high-quality datasets for function-calling applications.
- The team collected 3,673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner.
- Each dataset entry is verified through three stages to ensure reliability and correctness: format checking, actual function executions, and semantic verification.
- The authors demonstrate that models trained on their curated datasets can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models.
- They also show that their 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku.
- The team has released a dataset containing 60,000 high-quality entries to advance the field of function-calling agent domains.
Plain English Explanation
The researchers behind this paper recognized that creating reliable, high-quality datasets is crucial for developing effective function-calling agent models. To address this, they developed a tool called APIGen, which can automatically generate diverse datasets for these types of applications.
Using APIGen, the team collected 3,673 executable APIs across 21 different categories. This allowed them to create a wide range of function-calling scenarios to train models on. Importantly, they implemented a thorough verification process to ensure the quality and accuracy of each dataset entry, checking the format, executing the functions, and validating the semantic meaning.
The researchers then trained machine learning models using their curated datasets and found that even relatively small models (7B parameters) could outperform larger, more powerful models like GPT-4 on the Berkeley Function-Calling Benchmark. They also showed that their 1B parameter model could surpass the performance of GPT-3.5-Turbo and Claude-3 Haiku, which are larger and more capable models.
By making their 60,000-entry dataset publicly available, the team hopes to accelerate progress in the field of function-calling agent domains, where models need to understand and interact with various programming interfaces. This work builds on previous efforts like API-PACK, RoboGEN, and Generative AI to Generate Test Data Generators, which have also explored ways to generate high-quality datasets for related applications.
Technical Explanation
The key innovation in this work is the development of the APIGen pipeline, which automates the process of creating diverse, reliable, and high-quality datasets for function-calling applications. The researchers leveraged APIGen to collect 3,673 executable APIs across 21 different categories, ranging from math and finance to web development and machine learning.
To ensure the quality and correctness of the generated datasets, the team implemented a three-stage verification process. First, they checked the format of each data entry to ensure it conformed to the expected structure. Next, they executed the functions to confirm they were runnable. Finally, they performed semantic verification, analyzing the input-output behavior of the functions to validate their correctness.
The researchers then trained machine learning models using their curated datasets and evaluated them on the Berkeley Function-Calling Benchmark. They found that even a 7B parameter model trained on their data could outperform multiple GPT-4 models, which have much larger parameter counts. Additionally, their 1B parameter model was able to surpass the performance of GPT-3.5-Turbo and Claude-3 Haiku, which are significantly larger models.
These results demonstrate the value of the APIGen pipeline in generating high-quality datasets that can effectively train function-calling agent models. This work builds on previous efforts like API-BLEND and BigCodeBench, which have also explored ways to create diverse and comprehensive datasets for programming-related tasks.
Critical Analysis
The researchers have made a strong case for the importance of high-quality datasets in the development of function-calling agent models. By implementing a rigorous verification process, they have ensured the reliability and correctness of their generated datasets, which is a crucial aspect of this work.
However, it's worth noting that the dataset is limited to 60,000 entries, which may not be sufficient to fully capture the diversity and complexity of real-world function-calling scenarios. Additionally, the dataset is focused on a specific set of 21 categories, and it's unclear how well the models trained on this data would generalize to other domains or types of function-calling tasks.
Further research could explore ways to expand the dataset, either by automating the process of collecting and verifying a larger number of APIs or by incorporating human-curated data from various sources. Addressing these potential limitations could help strengthen the generalizability and practical applicability of the APIGen pipeline and the resulting models.
Conclusion
The APIGen pipeline presented in this paper represents a significant step forward in the development of high-quality datasets for function-calling agent models. By automating the data generation and verification process, the researchers have created a scalable and structured way to produce diverse, reliable datasets that can effectively train machine learning models.
The impressive performance of the models trained on their curated datasets, even with relatively small parameter counts, highlights the value of this approach. By making their dataset publicly available, the team is helping to advance the field of function-calling agent domains, where models need to understand and interact with a wide range of programming interfaces.
This work builds on previous efforts in dataset creation and model development for programming-related tasks, and it serves as a foundation for further research and innovation in this area. As the field of AI continues to evolve, the availability of high-quality datasets and the ability to train effective models will be crucial for driving progress and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh Murthy, Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, Caiming Xiong
The advancement of function-calling agent models requires diverse, reliable, and high-quality datasets. This paper presents APIGen, an automated data generation pipeline designed to synthesize verifiable high-quality datasets for function-calling applications. We leverage APIGen and collect 3,673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness. We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku. We release a dataset containing 60,000 high-quality entries, aiming to advance the field of function-calling agent domains. The dataset is available on Huggingface: https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k and the project homepage: https://apigen-pipeline.github.io/
Read more6/27/2024

0
ToolACE: Winning the Points of LLM Function Calling
Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong Wang, Yuxian Wang, Wu Ning, Yutai Hou, Bin Wang, Chuhan Wu, Xinzhi Wang, Yong Liu, Yasheng Wang, Duyu Tang, Dandan Tu, Lifeng Shang, Xin Jiang, Ruiming Tang, Defu Lian, Qun Liu, Enhong Chen
Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.
Read more9/4/2024
0
API Pack: A Massive Multi-Programming Language Dataset for API Call Generation
Zhen Guo, Adriana Meza Soria, Wei Sun, Yikang Shen, Rameswar Panda
We introduce API Pack, a massive multi-programming language dataset containing more than 1 million instruction-API call pairs to improve the API call generation capabilities of large language models. By fine-tuning CodeLlama-13B on 20,000 Python instances from API Pack, we enable it to outperform GPT-3.5 and GPT-4 in generating unseen API calls. Fine-tuning on API Pack also facilitates cross-programming language generalization by leveraging a large amount of data in one language and small amounts of data from other languages. Scaling the training data to 1 million instances further improves the model's ability to generalize to new APIs not used in training. To facilitate further research, we open-source the API Pack dataset, trained model, and associated source code at https://github.com/zguo0525/API-Pack.
Read more6/5/2024
📊
0
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, Chuang Gan
We present RoboGen, a generative robotic agent that automatically learns diverse robotic skills at scale via generative simulation. RoboGen leverages the latest advancements in foundation and generative models. Instead of directly using or adapting these models to produce policies or low-level actions, we advocate for a generative scheme, which uses these models to automatically generate diversified tasks, scenes, and training supervisions, thereby scaling up robotic skill learning with minimal human supervision. Our approach equips a robotic agent with a self-guided propose-generate-learn cycle: the agent first proposes interesting tasks and skills to develop, and then generates corresponding simulation environments by populating pertinent objects and assets with proper spatial configurations. Afterwards, the agent decomposes the proposed high-level task into sub-tasks, selects the optimal learning approach (reinforcement learning, motion planning, or trajectory optimization), generates required training supervision, and then learns policies to acquire the proposed skill. Our work attempts to extract the extensive and versatile knowledge embedded in large-scale models and transfer them to the field of robotics. Our fully generative pipeline can be queried repeatedly, producing an endless stream of skill demonstrations associated with diverse tasks and environments.
Read more6/18/2024