API Pack: A Massive Multi-Programming Language Dataset for API Call Generation

0
Sign in to get full access
Overview
• This research paper presents "API Pack," a large-scale, multilingual dataset for training models to generate API call sequences based on natural language instructions.
• The dataset contains over 1 million API call sequences in 11 programming languages, spanning a wide range of domains such as web development, data analysis, and machine learning.
• The paper also introduces several novel techniques for generating high-quality API call data, including the use of Octopus, a device-centric language model, and C-Pack, a framework for creating comprehensive corpora.
Plain English Explanation
The researchers have created a massive dataset called "API Pack" that can be used to train machine learning models to help developers write code. The dataset contains over 1 million examples of API calls (which are like the building blocks of code) in 11 different programming languages, covering a wide range of topics like web development and data analysis.
This is significant because it provides a huge amount of high-quality training data that can be used to build AI models that can understand natural language instructions and translate them into the appropriate code. For example, a developer could describe what they want a program to do in plain English, and the AI model could generate the necessary API calls to make it happen.
The researchers used some innovative techniques to create this dataset, like leveraging Octopus, a special language model that is focused on understanding how APIs work, and C-Pack, a framework for building comprehensive datasets. These approaches helped ensure that the data is of high quality and covers a wide range of use cases.
Technical Explanation
The paper introduces "API Pack," a large-scale, multilingual dataset for training models to generate API call sequences from natural language instructions. The dataset contains over 1 million API call sequences in 11 programming languages, spanning a wide range of domains such as web development, data analysis, and machine learning.
To create this dataset, the researchers developed several novel techniques. First, they leveraged Octopus, a device-centric language model that is specifically designed to understand API functions and their usage. Octopus was used to generate high-quality API call sequences based on natural language inputs.
Additionally, the researchers employed C-Pack, a framework for creating comprehensive corpora, to ensure that the dataset covers a diverse range of API usage scenarios. C-Pack allowed the researchers to systematically collect and curate API documentation, code samples, and other relevant resources to build a rich, multilingual dataset.
The paper also introduces several benchmark tasks for evaluating the performance of models trained on API Pack, such as API call generation, API documentation generation, and API-related question answering. The researchers demonstrate the effectiveness of their approach by training various language models on the API Pack dataset and evaluating their performance on these benchmark tasks.
Critical Analysis
The researchers have made a significant contribution to the field of machine learning for software development by creating the API Pack dataset. The large scale and multilingual nature of the dataset, as well as the innovative techniques used to generate it, are impressive and have the potential to advance the state-of-the-art in areas such as code completion and API misuse detection.
That said, the paper does not address some potential limitations and areas for further research. For example, the dataset may not fully capture the nuances of API usage in real-world software development projects, which often involve complex interactions between multiple APIs and other software components. Additionally, the paper does not discuss the potential biases or blind spots that may exist in the dataset, which could lead to model performance issues in certain domains or use cases.
Further research is also needed to understand how models trained on API Pack can be effectively integrated into existing software development workflows and tools, and how they can be adapted to handle evolving API ecosystems and changing user needs.
Conclusion
The API Pack dataset and the techniques used to create it represent a significant advancement in the field of machine learning for software development. By providing a large-scale, multilingual dataset for training models to generate API call sequences from natural language instructions, the researchers have opened up new possibilities for AI-powered tools that can enhance developer productivity and reduce the risk of API misuse.
The insights and methodologies presented in this paper have the potential to inform the development of a new generation of AI-powered software development tools, ultimately improving the efficiency and quality of software development processes across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
API Pack: A Massive Multi-Programming Language Dataset for API Call Generation
Zhen Guo, Adriana Meza Soria, Wei Sun, Yikang Shen, Rameswar Panda
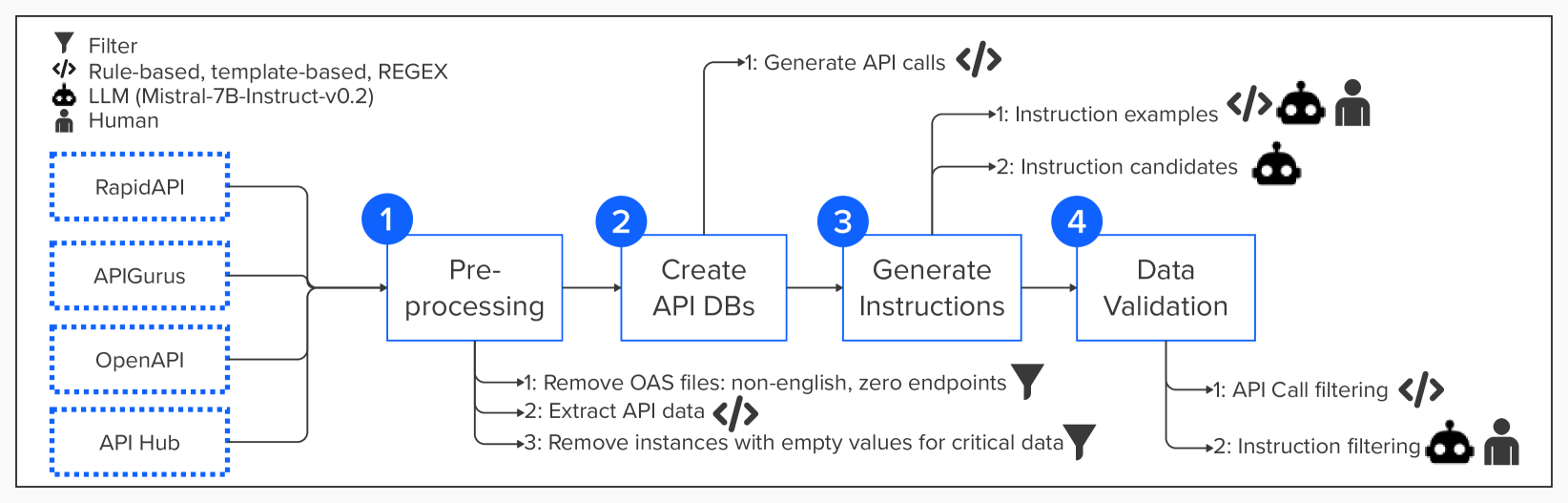
We introduce API Pack, a massive multi-programming language dataset containing more than 1 million instruction-API call pairs to improve the API call generation capabilities of large language models. By fine-tuning CodeLlama-13B on 20,000 Python instances from API Pack, we enable it to outperform GPT-3.5 and GPT-4 in generating unseen API calls. Fine-tuning on API Pack also facilitates cross-programming language generalization by leveraging a large amount of data in one language and small amounts of data from other languages. Scaling the training data to 1 million instances further improves the model's ability to generalize to new APIs not used in training. To facilitate further research, we open-source the API Pack dataset, trained model, and associated source code at https://github.com/zguo0525/API-Pack.
Read more6/5/2024
🖼️
0
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh Murthy, Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, Caiming Xiong
The advancement of function-calling agent models requires diverse, reliable, and high-quality datasets. This paper presents APIGen, an automated data generation pipeline designed to synthesize verifiable high-quality datasets for function-calling applications. We leverage APIGen and collect 3,673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness. We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku. We release a dataset containing 60,000 high-quality entries, aiming to advance the field of function-calling agent domains. The dataset is available on Huggingface: https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k and the project homepage: https://apigen-pipeline.github.io/
Read more6/27/2024
🏋️
0
API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
Kinjal Basu, Ibrahim Abdelaziz, Subhajit Chaudhury, Soham Dan, Maxwell Crouse, Asim Munawar, Sadhana Kumaravel, Vinod Muthusamy, Pavan Kapanipathi, Luis A. Lastras
There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
Read more5/21/2024
🛸
0
C-Pack: Packaged Resources To Advance General Chinese Embedding
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, Jian-Yun Nie
We introduce C-Pack, a package of resources that significantly advance the field of general Chinese embeddings. C-Pack includes three critical resources. 1) C-MTEB is a comprehensive benchmark for Chinese text embeddings covering 6 tasks and 35 datasets. 2) C-MTP is a massive text embedding dataset curated from labeled and unlabeled Chinese corpora for training embedding models. 3) C-TEM is a family of embedding models covering multiple sizes. Our models outperform all prior Chinese text embeddings on C-MTEB by up to +10% upon the time of the release. We also integrate and optimize the entire suite of training methods for C-TEM. Along with our resources on general Chinese embedding, we release our data and models for English text embeddings. The English models achieve state-of-the-art performance on MTEB benchmark; meanwhile, our released English data is 2 times larger than the Chinese data. All these resources are made publicly available at https://github.com/FlagOpen/FlagEmbedding.
Read more5/14/2024