CoCo-Agent: A Comprehensive Cognitive MLLM Agent for Smartphone GUI Automation

0
🚀
Sign in to get full access
Overview
- Proposes a novel "Comprehensive Cognitive LLM Agent" (CoCo-Agent) with two key approaches to improve graphical user interface (GUI) automation.
- Introduces "Comprehensive Environment Perception" (CEP) to enable more thorough GUI perception.
- Presents "Conditional Action Prediction" (CAP) to decompose action prediction into sub-problems.
- Achieves state-of-the-art performance on AITW and META-GUI benchmarks.
Plain English Explanation
The paper explores using large language models (LLMs) as autonomous agents to interact with graphical user interfaces (GUIs). However, the authors note that current GUI agents lack comprehensive cognition abilities, including thorough perception of the environment and reliable action responses.
To address this, the authors propose the CoCo-Agent, a new approach with two key innovations. First, Comprehensive Environment Perception (CEP) enables the agent to perceive the GUI from multiple angles, including screenshots, detailed layout information, and past user actions. This gives the agent a more holistic understanding of the environment.
Second, Conditional Action Prediction (CAP) breaks down the action prediction process into two sub-tasks: predicting the type of action to take (e.g., click, type, scroll) and then predicting the specific target for that action (e.g., which button to click, where to type, what to scroll). This more structured approach helps the agent make more reliable decisions.
By incorporating these two novel techniques, the authors demonstrate that their CoCo-Agent can outperform existing approaches on industry-standard benchmarks, showing promising abilities to interact with realistic GUI environments.
Technical Explanation
The paper introduces the CoCo-Agent, a comprehensive cognitive agent for GUI automation tasks. It addresses two key challenges: exhaustive perception of the GUI environment and reliable action response.
To enable more thorough perception, the authors propose Comprehensive Environment Perception (CEP). CEP combines multiple modalities, including screenshots for visual information, detailed layout data for finer-grained understanding, and historical user actions for contextual cues. This multi-faceted approach gives the agent a richer representation of the GUI.
For action prediction, the authors introduce Conditional Action Prediction (CAP). CAP decomposes the action prediction into two sub-tasks: first predicting the type of action (e.g., click, type, scroll) and then predicting the specific target for that action (e.g., which button to click, where to type, what to scroll). This structured approach allows the agent to make more reliable decisions.
The authors evaluate the CoCo-Agent on the AITW and META-GUI benchmarks, which test GUI automation capabilities in realistic scenarios. The CoCo-Agent achieves new state-of-the-art performance, demonstrating its ability to excel at these challenging tasks.
Critical Analysis
The paper presents a compelling approach to enhance the capabilities of LLM-based GUI agents. The authors' insights around the need for comprehensive perception and structured action prediction are well-founded, as evidenced by the CoCo-Agent's strong performance on industry-standard benchmarks.
However, the paper does not delve deeply into the limitations or potential drawbacks of the proposed techniques. For example, it would be helpful to understand the computational and training complexity of the CEP and CAP components, as well as any potential biases or edge cases that could arise in real-world deployment.
Additionally, the paper could benefit from a more thorough discussion of the implications of this research, particularly around the ethical considerations of human-centered LLM agents and their integration into user interfaces. As these technologies become more advanced, it is crucial to consider their societal impact and potential unintended consequences.
Conclusion
The CoCo-Agent introduced in this paper represents a significant step forward in the development of LLM-based GUI automation agents. By incorporating comprehensive environment perception and structured action prediction, the authors have demonstrated the potential for these agents to interact with real-world interfaces more effectively.
While the paper focuses on the technical details and benchmarking results, the broader implications of this research are worth further exploration. As LLM agents become more integrated into user interfaces, it will be crucial to consider the ethical and social considerations of these technologies. Nevertheless, the CoCo-Agent's strong performance suggests that this line of research holds promise for enhancing the autonomous capabilities of language models in practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
CoCo-Agent: A Comprehensive Cognitive MLLM Agent for Smartphone GUI Automation
Xinbei Ma, Zhuosheng Zhang, Hai Zhao
Multimodal large language models (MLLMs) have shown remarkable potential as human-like autonomous language agents to interact with real-world environments, especially for graphical user interface (GUI) automation. However, those GUI agents require comprehensive cognition ability including exhaustive perception and reliable action response. We propose a Comprehensive Cognitive LLM Agent, CoCo-Agent, with two novel approaches, comprehensive environment perception (CEP) and conditional action prediction (CAP), to systematically improve the GUI automation performance. First, CEP facilitates the GUI perception through different aspects and granularity, including screenshots and complementary detailed layouts for the visual channel and historical actions for the textual channel. Second, CAP decomposes the action prediction into sub-problems: action type prediction and action target conditioned on the action type. With our technical design, our agent achieves new state-of-the-art performance on AITW and META-GUI benchmarks, showing promising abilities in realistic scenarios. Code is available at https://github.com/xbmxb/CoCo-Agent.
Read more6/4/2024
👁️
0
You Only Look at Screens: Multimodal Chain-of-Action Agents
Zhuosheng Zhang, Aston Zhang
Autonomous graphical user interface (GUI) agents aim to facilitate task automation by interacting with the user interface without manual intervention. Recent studies have investigated eliciting the capabilities of large language models (LLMs) for effective engagement in diverse environments. To align with the input-output requirement of LLMs, most existing approaches are developed under a sandbox setting where they rely on external tools and application-specific APIs to parse the environment into textual elements and interpret the predicted actions. Consequently, those approaches often grapple with inference inefficiency and error propagation risks. To mitigate the challenges, we introduce Auto-GUI, a multimodal solution that directly interacts with the interface, bypassing the need for environment parsing or reliance on application-dependent APIs. Moreover, we propose a chain-of-action technique -- leveraging a series of intermediate previous action histories and future action plans -- to help the agent decide what action to execute. We evaluate our approach on a new device-control benchmark AITW with 30$K$ unique instructions, spanning multi-step tasks such as application operation, web searching, and web shopping. Experimental results show that Auto-GUI achieves state-of-the-art performance with an action type prediction accuracy of 90% and an overall action success rate of 74%. Code is publicly available at https://github.com/cooelf/Auto-GUI.
Read more6/10/2024
0
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
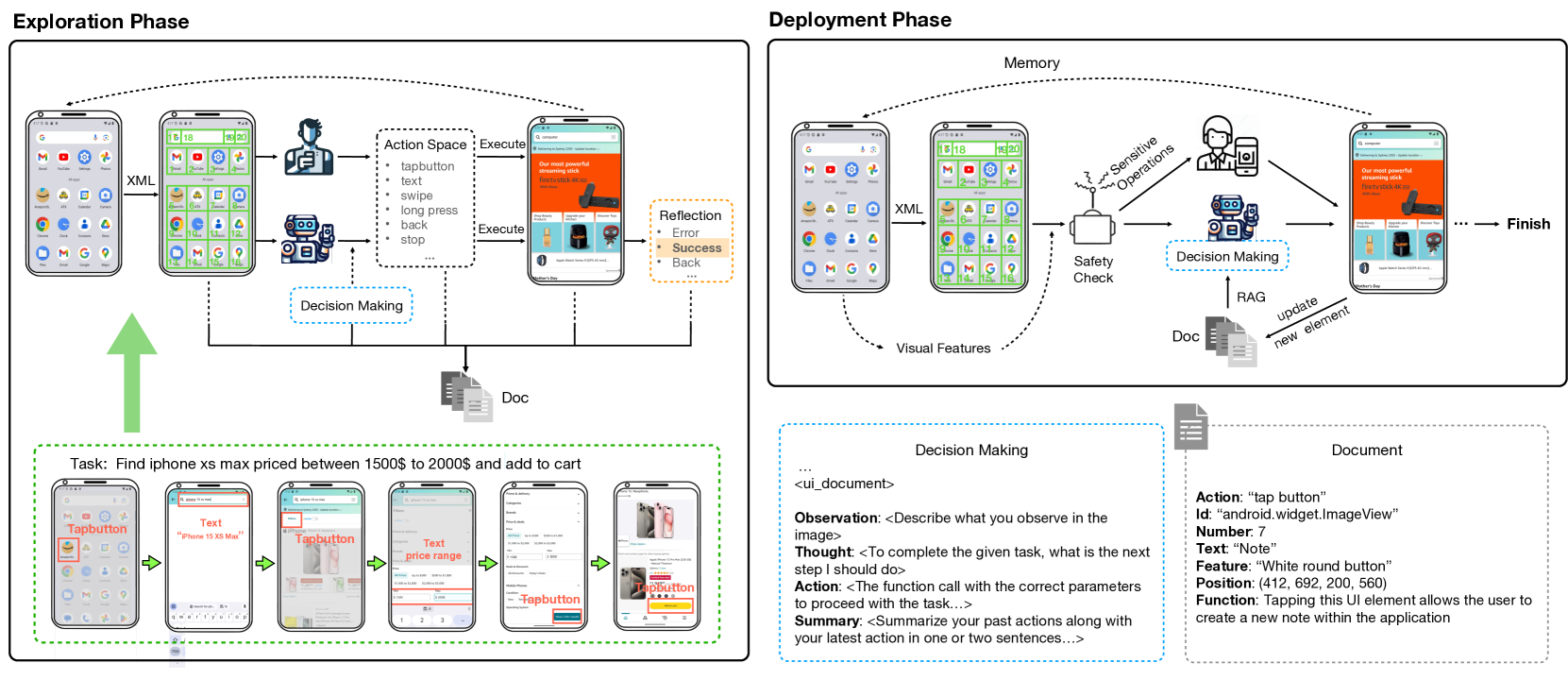
Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, Yunchao Wei
With the advancement of Multimodal Large Language Models (MLLM), LLM-driven visual agents are increasingly impacting software interfaces, particularly those with graphical user interfaces. This work introduces a novel LLM-based multimodal agent framework for mobile devices. This framework, capable of navigating mobile devices, emulates human-like interactions. Our agent constructs a flexible action space that enhances adaptability across various applications including parser, text and vision descriptions. The agent operates through two main phases: exploration and deployment. During the exploration phase, functionalities of user interface elements are documented either through agent-driven or manual explorations into a customized structured knowledge base. In the deployment phase, RAG technology enables efficient retrieval and update from this knowledge base, thereby empowering the agent to perform tasks effectively and accurately. This includes performing complex, multi-step operations across various applications, thereby demonstrating the framework's adaptability and precision in handling customized task workflows. Our experimental results across various benchmarks demonstrate the framework's superior performance, confirming its effectiveness in real-world scenarios. Our code will be open source soon.
Read more8/26/2024
0
Experiential Co-Learning of Software-Developing Agents
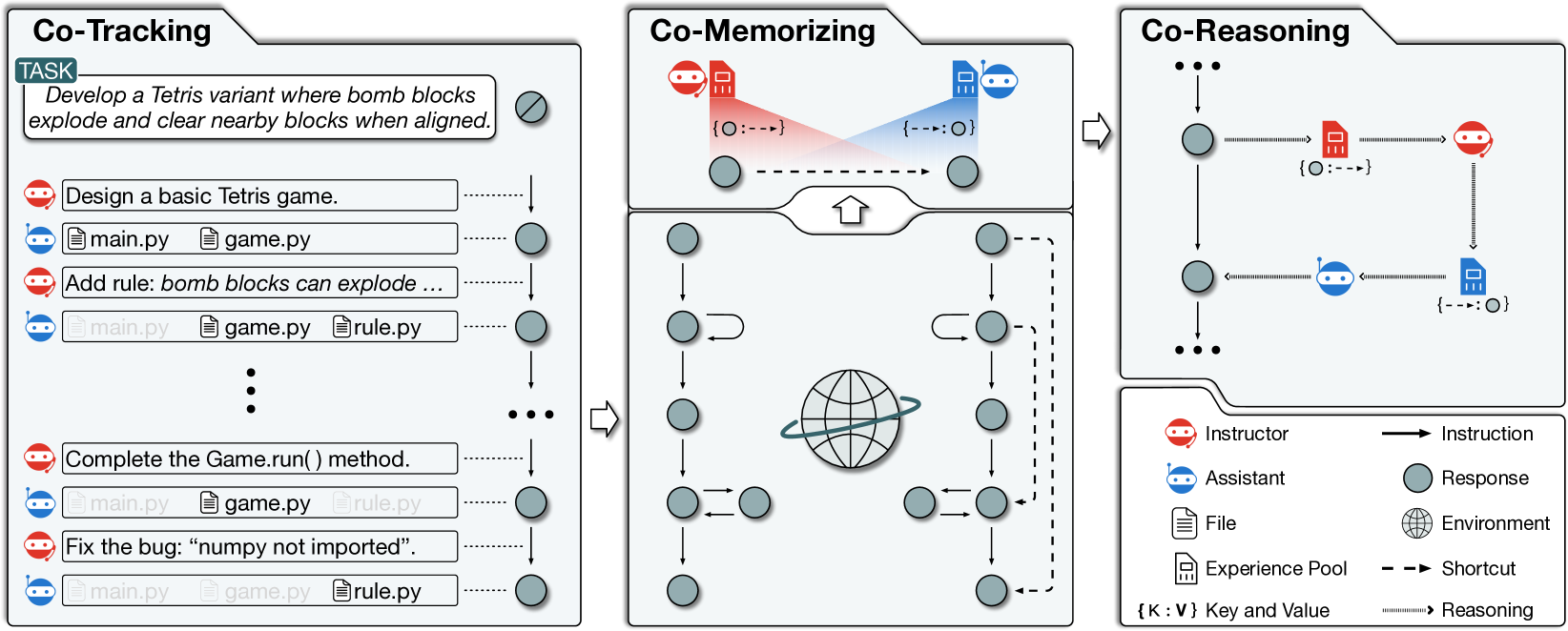
Chen Qian, Yufan Dang, Jiahao Li, Wei Liu, Zihao Xie, Yifei Wang, Weize Chen, Cheng Yang, Xin Cong, Xiaoyin Che, Zhiyuan Liu, Maosong Sun
Recent advancements in large language models (LLMs) have brought significant changes to various domains, especially through LLM-driven autonomous agents. A representative scenario is in software development, where LLM agents demonstrate efficient collaboration, task division, and assurance of software quality, markedly reducing the need for manual involvement. However, these agents frequently perform a variety of tasks independently, without benefiting from past experiences, which leads to repeated mistakes and inefficient attempts in multi-step task execution. To this end, we introduce Experiential Co-Learning, a novel LLM-agent learning framework in which instructor and assistant agents gather shortcut-oriented experiences from their historical trajectories and use these past experiences for future task execution. The extensive experiments demonstrate that the framework enables agents to tackle unseen software-developing tasks more effectively. We anticipate that our insights will guide LLM agents towards enhanced autonomy and contribute to their evolutionary growth in cooperative learning. The code and data are available at https://github.com/OpenBMB/ChatDev.
Read more6/6/2024