Applied Machine Learning to Anomaly Detection in Enterprise Purchase Processes

0
❗
Sign in to get full access
Overview
- Discusses a methodology to prioritize the investigation of anomalies detected in large purchase datasets
- Employs unsupervised machine learning techniques like z-Score, DBSCAN, k-Means, and Isolation Forest to identify anomalies
- Provides an ensemble prioritization of the anomaly candidates and proposes explainability methods to help specialists understand the results
Plain English Explanation
As organizations increasingly digitize their processes, they face the challenge of detecting suspicious activities within the growing volume of data. To address this, companies regularly conduct audits, and internal auditors and purchase specialists are constantly seeking new ways to automate these processes. This research paper proposes a methodology to prioritize the investigation of anomalies detected in two large purchase datasets from real-world data. The goal is to improve the effectiveness of the companies' control efforts and increase the performance of these tasks.
The researchers first conduct a comprehensive Exploratory Data Analysis before applying unsupervised machine learning techniques to detect anomalies. They use a univariate approach with the z-Score index and the DBSCAN algorithm, as well as a multivariate analysis with the k-Means and Isolation Forest algorithms, and the Silhouette index. Each method provides a set of transaction candidates that require further review. The researchers then propose an ensemble prioritization of the candidates and suggest the use of explainability methods like LIME, Shapley, and SHAP to help the company specialists understand the results.
Technical Explanation
The paper presents a methodology to prioritize the investigation of anomalies detected in large purchase datasets using unsupervised machine learning techniques. The researchers first conduct an Exploratory Data Analysis to gain a comprehensive understanding of the datasets.
They then employ a univariate approach, applying the z-Score index and the DBSCAN algorithm to identify anomalies. This is followed by a multivariate analysis using the k-Means and Isolation Forest algorithms, as well as the Silhouette index. Each method provides a set of transaction candidates that are potential anomalies and require further investigation.
To assist the company specialists in understanding the results, the researchers propose an ensemble prioritization of the anomaly candidates and suggest the use of explainability methods, such as LIME, Shapley, and SHAP. These techniques can help the specialists interpret the models' decisions and gain deeper insights into the detected anomalies.
Critical Analysis
The paper presents a comprehensive approach to detecting and prioritizing anomalies in large purchase datasets, which can be valuable for companies aiming to improve their control efforts and automate their audit processes. However, the researchers do not provide a detailed evaluation of the performance of the different machine learning techniques used, nor do they compare the results to other anomaly detection methods.
Additionally, the paper does not address the potential limitations of the explainability methods proposed, such as their ability to handle complex models or their interpretability for non-technical stakeholders. Further research could explore the practical implications of implementing this methodology in real-world business settings and assess its long-term effectiveness.
Conclusion
This research paper presents a methodology to prioritize the investigation of anomalies detected in large purchase datasets using unsupervised machine learning techniques. The proposed approach combines univariate and multivariate analysis methods to identify potential anomalies and provides an ensemble prioritization of the candidates, along with suggestions for using explainability methods to help company specialists understand the results.
While the paper offers a promising approach to improving the effectiveness of companies' control efforts, further research is needed to evaluate the performance of the techniques used and address potential limitations in their practical application. Overall, this work contributes to the ongoing efforts to automate and enhance the auditing processes in the context of increasing data volumes and digital transformation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
Applied Machine Learning to Anomaly Detection in Enterprise Purchase Processes
A. Herreros-Mart'inez, R. Magdalena-Benedicto, J. Vila-Franc'es, A. J. Serrano-L'opez, S. P'erez-D'iaz
In a context of a continuous digitalisation of processes, organisations must deal with the challenge of detecting anomalies that can reveal suspicious activities upon an increasing volume of data. To pursue this goal, audit engagements are carried out regularly, and internal auditors and purchase specialists are constantly looking for new methods to automate these processes. This work proposes a methodology to prioritise the investigation of the cases detected in two large purchase datasets from real data. The goal is to contribute to the effectiveness of the companies' control efforts and to increase the performance of carrying out such tasks. A comprehensive Exploratory Data Analysis is carried out before using unsupervised Machine Learning techniques addressed to detect anomalies. A univariate approach has been applied through the z-Score index and the DBSCAN algorithm, while a multivariate analysis is implemented with the k-Means and Isolation Forest algorithms, and the Silhouette index, resulting in each method having a transaction candidates' proposal to be reviewed. An ensemble prioritisation of the candidates is provided jointly with a proposal of explicability methods (LIME, Shapley, SHAP) to help the company specialists in their understanding.
Read more5/24/2024

0
Anomaly Detection Within Mission-Critical Call Processing
Sean Doris, Iosif Salem, Stefan Schmid
With increasingly larger and more complex telecommunication networks, there is a need for improved monitoring and reliability. Requirements increase further when working with mission-critical systems requiring stable operations to meet precise design and client requirements while maintaining high availability. This paper proposes a novel methodology for developing a machine learning model that can assist in maintaining availability (through anomaly detection) for client-server communications in mission-critical systems. To that end, we validate our methodology for training models based on data classified according to client performance. The proposed methodology evaluates the use of machine learning to perform anomaly detection of a single virtualized server loaded with simulated network traffic (using SIPp) with media calls. The collected data for the models are classified based on the round trip time performance experienced on the client side to determine if the trained models can detect anomalous client side performance only using key performance indicators available on the server. We compared the performance of seven different machine learning models by testing different trained and untrained test stressor scenarios. In the comparison, five models achieved an F1-score above 0.99 for the trained test scenarios. Random Forest was the only model able to attain an F1-score above 0.9 for all untrained test scenarios with the lowest being 0.980. The results suggest that it is possible to generate accurate anomaly detection to evaluate degraded client-side performance.
Read more8/28/2024
📊
0
A Data Mining-Based Dynamical Anomaly Detection Method for Integrating with an Advance Metering System
Sarit Maitra
Building operations consume 30% of total power consumption and contribute 26% of global power-related emissions. Therefore, monitoring, and early detection of anomalies at the meter level are essential for residential and commercial buildings. This work investigates both supervised and unsupervised approaches and introduces a dynamic anomaly detection system. The system introduces a supervised Light Gradient Boosting machine and an unsupervised autoencoder with a dynamic threshold. This system is designed to provide real-time detection of anomalies at the meter level. The proposed dynamical system comes with a dynamic threshold based on the Mahalanobis distance and moving averages. This approach allows the system to adapt to changes in the data distribution over time. The effectiveness of the proposed system is evaluated using real-life power consumption data collected from smart metering systems. This empirical testing ensures that the system's performance is validated under real-world conditions. By detecting unusual data movements and providing early warnings, the proposed system contributes significantly to visual analytics and decision science. Early detection of anomalies enables timely troubleshooting, preventing financial losses and potential disasters such as fire incidents.
Read more5/7/2024
0
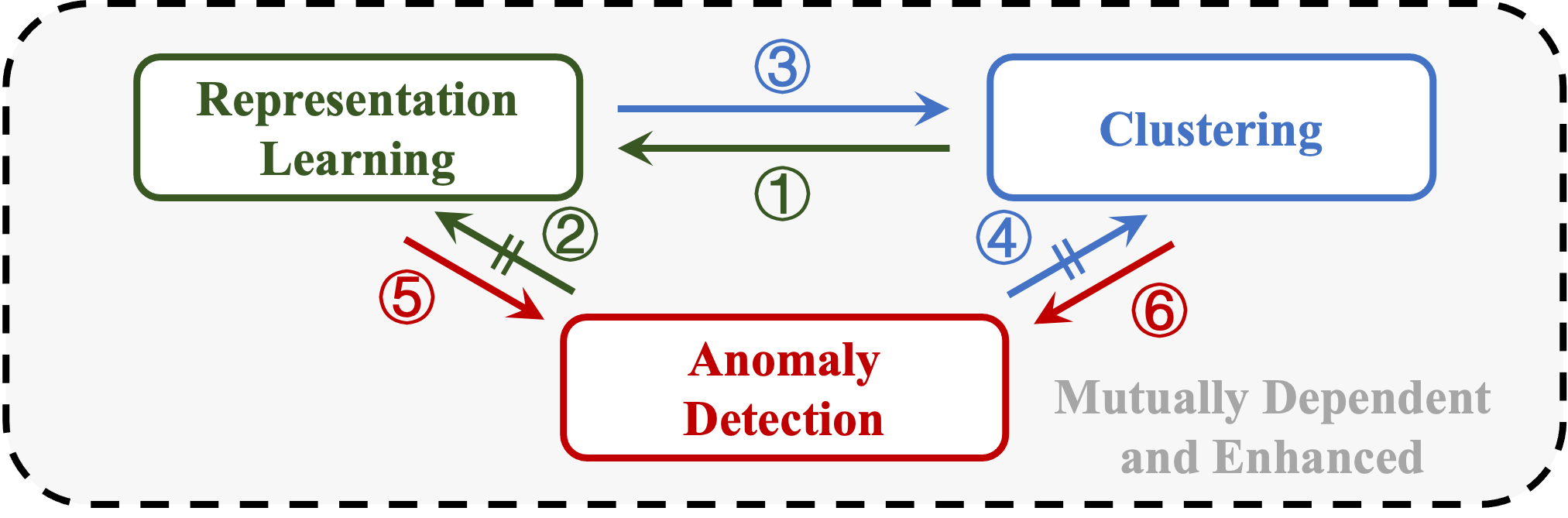
Towards a Unified Framework of Clustering-based Anomaly Detection
Zeyu Fang, Ming Gu, Sheng Zhou, Jiawei Chen, Qiaoyu Tan, Haishuai Wang, Jiajun Bu
Unsupervised Anomaly Detection (UAD) plays a crucial role in identifying abnormal patterns within data without labeled examples, holding significant practical implications across various domains. Although the individual contributions of representation learning and clustering to anomaly detection are well-established, their interdependencies remain under-explored due to the absence of a unified theoretical framework. Consequently, their collective potential to enhance anomaly detection performance remains largely untapped. To bridge this gap, in this paper, we propose a novel probabilistic mixture model for anomaly detection to establish a theoretical connection among representation learning, clustering, and anomaly detection. By maximizing a novel anomaly-aware data likelihood, representation learning and clustering can effectively reduce the adverse impact of anomalous data and collaboratively benefit anomaly detection. Meanwhile, a theoretically substantiated anomaly score is naturally derived from this framework. Lastly, drawing inspiration from gravitational analysis in physics, we have devised an improved anomaly score that more effectively harnesses the combined power of representation learning and clustering. Extensive experiments, involving 17 baseline methods across 30 diverse datasets, validate the effectiveness and generalization capability of the proposed method, surpassing state-of-the-art methods.
Read more6/4/2024