AQuA -- Combining Experts' and Non-Experts' Views To Assess Deliberation Quality in Online Discussions Using LLMs

0

Sign in to get full access
Related Work
The paper discusses related research in several areas, including:
-
Expert-curated Question-Answering: Prior work has explored using expert-curated questions and answers, such as in the ExpertQA dataset, to train and evaluate language models.
-
Information Extraction from Language Models: Researchers have investigated how to effectively extract information from large language models, as explored in the Evaluating Generative Language Models for Information Extraction paper.
-
Improving Language Model Performance for Speaking and Conversational Tasks: The ComuniQA project has studied how to leverage large language models to improve performance on speaking and conversational tasks.
-
Automatic Evaluation Metrics for Dialogues: Prior work has introduced metrics like Perplexity-Difference Density (PDD) to automatically measure the quality of dialogues, as discussed in the Unlocking the Structure: Measuring Dialogue Quality with PDD paper.
-
Datasets for AI-Generated Images: The research also builds on datasets like AIGIQA, which contain AI-generated images and related information.
By drawing on this existing body of work, the current paper aims to combine expert and non-expert perspectives to assess the quality of deliberation in online discussions using large language models.
Plain English Explanation
The researchers in this paper are trying to develop a way to automatically evaluate the quality of discussions that happen online, using a combination of input from experts and non-experts.
The key idea is to use large language models - powerful AI systems that can understand and generate human-like text - to analyze the content and structure of online discussions. The researchers want to see if these language models can reliably assess whether a discussion is of high "deliberation quality," meaning the participants are engaging in thoughtful, nuanced debate on the topic.
To do this, the researchers will first get input from both expert judges (people with deep knowledge of the topic) and non-expert judges (regular people) on what makes a high-quality online discussion. They'll then train the language models to recognize the patterns and features of high-quality deliberation, based on the expert and non-expert feedback.
The goal is to develop a system that can automatically assess the quality of online discussions at scale, without needing human raters for every conversation. This could be useful for moderating online forums, understanding the dynamics of public discourse, and generally improving the quality of online interactions.
Technical Explanation
The key elements of the paper's technical approach include:
-
Expert and Non-Expert Annotation: The researchers will collect quality ratings on online discussions from both expert judges (with domain expertise) and non-expert judges (regular users). This allows them to understand deliberation quality from multiple perspectives.
-
Language Model-Based Quality Assessment: The researchers will then train large language models to automatically assess the deliberation quality of online discussions, using the expert and non-expert ratings as training data. This allows them to scale quality assessment beyond manual human raters.
-
Multimodal Integration: In addition to the textual content of discussions, the researchers plan to incorporate other modalities like images, which are increasingly common in online conversations. This multimodal approach could lead to more robust quality assessment.
-
Evaluation Metrics: The paper proposes using metrics like Perplexity-Difference Density (PDD), which measure the coherence and flow of dialogue, to automatically evaluate the deliberation quality of the online discussions.
-
Diverse Dataset: The researchers will build a dataset of online discussions spanning multiple topics and platforms, to ensure the quality assessment system generalizes well.
By combining expert and non-expert perspectives, leveraging powerful language models, and incorporating multimodal signals, the researchers aim to develop a scalable and reliable system for assessing the quality of deliberation in online discussions.
Critical Analysis
The research proposed in this paper addresses an important challenge in understanding and improving online discourse. Automatically assessing the quality of deliberation in online discussions could have significant implications for content moderation, public dialogue analysis, and fostering more constructive online interactions.
One potential strength of the approach is the integration of both expert and non-expert viewpoints on what constitutes high-quality deliberation. This could lead to a more nuanced and representative understanding of deliberation quality, beyond just relying on expert opinions.
However, the paper does not fully address potential biases or limitations in the expert and non-expert annotations. It will be important to carefully examine the composition and potential biases of the judges, as well as how their individual perspectives may influence the final quality assessments.
Additionally, the use of language models for this task raises questions about their interpretability and potential for reproducing or amplifying societal biases. The researchers should carefully consider ways to audit and mitigate these risks as they develop their system.
Finally, the proposed dataset and evaluation metrics, while promising, may not capture the full complexity of online discussions. The researchers should be open to iterating on their approach and incorporating feedback from a diverse set of stakeholders as the work progresses.
Conclusion
This paper presents an ambitious effort to leverage large language models and combined expert-non-expert perspectives to automatically assess the quality of deliberation in online discussions. If successful, this research could lead to valuable tools for understanding and improving the quality of public discourse in the digital age.
However, the researchers must navigate complex challenges related to bias, interpretability, and representativeness to ensure their system is robust and beneficial. Continued refinement, stakeholder engagement, and a commitment to responsible development will be crucial as this work moves forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AQuA -- Combining Experts' and Non-Experts' Views To Assess Deliberation Quality in Online Discussions Using LLMs
Maike Behrendt, Stefan Sylvius Wagner, Marc Ziegele, Lena Wilms, Anke Stoll, Dominique Heinbach, Stefan Harmeling
Measuring the quality of contributions in political online discussions is crucial in deliberation research and computer science. Research has identified various indicators to assess online discussion quality, and with deep learning advancements, automating these measures has become feasible. While some studies focus on analyzing specific quality indicators, a comprehensive quality score incorporating various deliberative aspects is often preferred. In this work, we introduce AQuA, an additive score that calculates a unified deliberative quality score from multiple indices for each discussion post. Unlike other singular scores, AQuA preserves information on the deliberative aspects present in comments, enhancing model transparency. We develop adapter models for 20 deliberative indices, and calculate correlation coefficients between experts' annotations and the perceived deliberativeness by non-experts to weigh the individual indices into a single deliberative score. We demonstrate that the AQuA score can be computed easily from pre-trained adapters and aligns well with annotations on other datasets that have not be seen during training. The analysis of experts' vs. non-experts' annotations confirms theoretical findings in the social science literature.
Read more4/5/2024

0
Estimating Contribution Quality in Online Deliberations Using a Large Language Model
Lodewijk Gelauff, Mohak Goyal, Bhargav Dindukurthi, Ashish Goel, Alice Siu
Deliberation involves participants exchanging knowledge, arguments, and perspectives and has been shown to be effective at addressing polarization. The Stanford Online Deliberation Platform facilitates large-scale deliberations. It enables video-based online discussions on a structured agenda for small groups without requiring human moderators. This paper's data comes from various deliberation events, including one conducted in collaboration with Meta in 32 countries, and another with 38 post-secondary institutions in the US. Estimating the quality of contributions in a conversation is crucial for assessing feature and intervention impacts. Traditionally, this is done by human annotators, which is time-consuming and costly. We use a large language model (LLM) alongside eight human annotators to rate contributions based on justification, novelty, expansion of the conversation, and potential for further expansion, with scores ranging from 1 to 5. Annotators also provide brief justifications for their ratings. Using the average rating from other human annotators as the ground truth, we find the model outperforms individual human annotators. While pairs of human annotators outperform the model in rating justification and groups of three outperform it on all four metrics, the model remains competitive. We illustrate the usefulness of the automated quality rating by assessing the effect of nudges on the quality of deliberation. We first observe that individual nudges after prolonged inactivity are highly effective, increasing the likelihood of the individual requesting to speak in the next 30 seconds by 65%. Using our automated quality estimation, we show that the quality ratings for statements prompted by nudging are similar to those made without nudging, signifying that nudging leads to more ideas being generated in the conversation without losing overall quality.
Read more8/23/2024
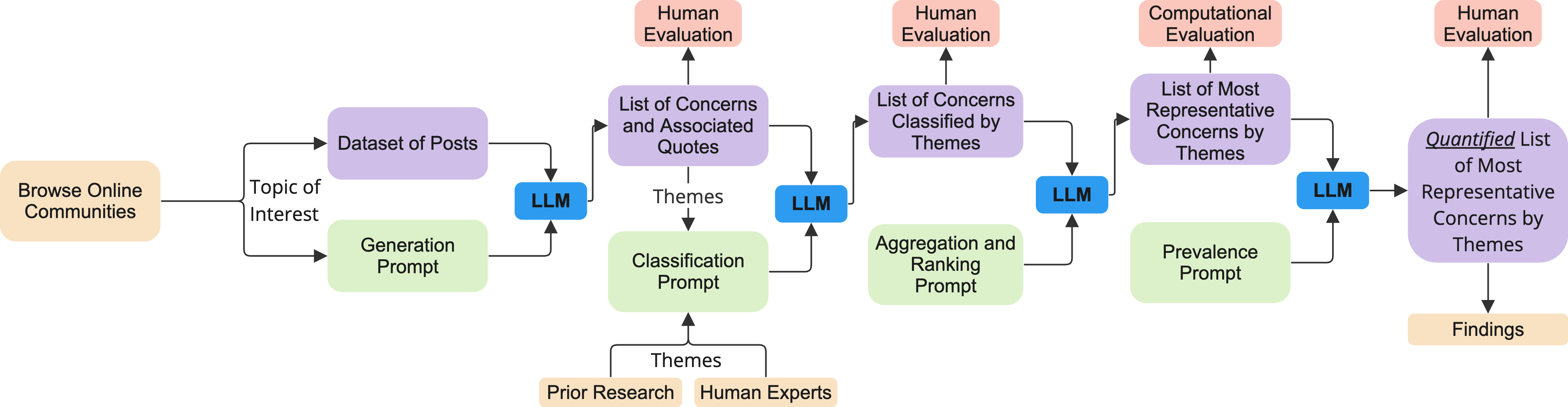
0
QuaLLM: An LLM-based Framework to Extract Quantitative Insights from Online Forums
Varun Nagaraj Rao, Eesha Agarwal, Samantha Dalal, Dan Calacci, Andr'es Monroy-Hern'andez
Online discussion forums provide crucial data to understand the concerns of a wide range of real-world communities. However, the typical qualitative and quantitative methods used to analyze those data, such as thematic analysis and topic modeling, are infeasible to scale or require significant human effort to translate outputs to human readable forms. This study introduces QuaLLM, a novel LLM-based framework to analyze and extract quantitative insights from text data on online forums. The framework consists of a novel prompting methodology and evaluation strategy. We applied this framework to analyze over one million comments from two Reddit's rideshare worker communities, marking the largest study of its type. We uncover significant worker concerns regarding AI and algorithmic platform decisions, responding to regulatory calls about worker insights. In short, our work sets a new precedent for AI-assisted quantitative data analysis to surface concerns from online forums.
Read more5/10/2024

0
DebateQA: Evaluating Question Answering on Debatable Knowledge
Rongwu Xu, Xuan Qi, Zehan Qi, Wei Xu, Zhijiang Guo
The rise of large language models (LLMs) has enabled us to seek answers to inherently debatable questions on LLM chatbots, necessitating a reliable way to evaluate their ability. However, traditional QA benchmarks assume fixed answers are inadequate for this purpose. To address this, we introduce DebateQA, a dataset of 2,941 debatable questions, each accompanied by multiple human-annotated partial answers that capture a variety of perspectives. We develop two metrics: Perspective Diversity, which evaluates the comprehensiveness of perspectives, and Dispute Awareness, which assesses if the LLM acknowledges the question's debatable nature. Experiments demonstrate that both metrics align with human preferences and are stable across different underlying models. Using DebateQA with two metrics, we assess 12 popular LLMs and retrieval-augmented generation methods. Our findings reveal that while LLMs generally excel at recognizing debatable issues, their ability to provide comprehensive answers encompassing diverse perspectives varies considerably.
Read more8/6/2024