Are Bigger Encoders Always Better in Vision Large Models?

0

Sign in to get full access
Overview
- This paper investigates the relationship between encoder size and performance in vision-language large models.
- The researchers conduct extensive experiments to understand how encoder capacity impacts model capabilities across a range of tasks.
- The findings provide valuable insights for effectively designing and scaling vision-language models.
Plain English Explanation
The paper examines whether simply increasing the size of the encoder component in vision-language models leads to better performance. Vision-language models are AI systems that can understand and process both visual and textual information. The researchers wanted to understand how the size of the encoder, which is responsible for processing the visual inputs, affects the overall capabilities of these models.
They ran a series of experiments to test models with different encoder sizes on a variety of tasks, such as image classification, visual question answering, and image-text retrieval. The results show that bigger encoders do not always lead to better performance across the board. In fact, the researchers found that the benefits of a larger encoder can diminish or even reverse depending on the specific task and dataset.
These findings have important implications for how we design and scale vision-language models going forward. They suggest that simply making the encoder bigger may not be the most effective strategy, and that other factors, such as the model architecture, training data, and task-specific optimization, need to be carefully considered.
Technical Explanation
The paper presents a systematic study of the relationship between encoder size and model performance in vision-language large models. The researchers experiment with various encoder configurations, ranging from small to extremely large, and evaluate their impact on a diverse set of tasks, including image classification, visual question answering, and image-text retrieval.
The key findings include:
-
Encoder Size and Task Performance: Contrary to the common assumption that bigger encoders are always better, the results show that the benefits of increasing encoder size can diminish or even reverse depending on the specific task and dataset. For some tasks, a smaller encoder can outperform a larger one.
-
Encoder Scaling Limits: The researchers identify thresholds beyond which further increasing the encoder size provides diminishing or negative returns in terms of overall model performance. This suggests that there are practical limits to the benefits of scaling up the encoder component.
-
Task-Specific Optimization: The paper highlights the importance of task-specific optimization, where the encoder size is tailored to the unique requirements of each task. A one-size-fits-all approach may not be the most effective strategy.
-
Architectural Considerations: The findings suggest that the encoder capacity needs to be balanced with other model components, such as the transformer layers and the language model, to achieve optimal performance. Simply scaling up the encoder alone may not be sufficient.
These insights have significant implications for the design and development of vision-language large models. They challenge the prevailing notion that bigger encoders are inherently better and underscore the need for a more nuanced, task-specific approach to model scaling and optimization.
Critical Analysis
The paper presents a rigorous and comprehensive analysis of the relationship between encoder size and model performance in vision-language large models. The researchers have done an admirable job in designing and executing a diverse set of experiments to uncover the key insights.
One potential limitation of the study is the reliance on a relatively small number of datasets and tasks. While the researchers have selected a representative set of standard benchmarks, it would be valuable to explore a wider range of tasks and datasets to further validate the generalizability of the findings.
Additionally, the paper does not delve into the underlying mechanisms and architectural considerations that contribute to the observed performance patterns. A more in-depth analysis of the model internals and the interplay between the encoder and other model components could provide deeper insights and guide future model design decisions.
Despite these minor caveats, the paper makes a significant contribution to our understanding of the role of encoder size in vision-language large models. The findings challenge common assumptions and provide a strong foundation for rethinking the approach to model scaling and optimization in this domain.
Conclusion
This paper offers valuable insights into the complex relationship between encoder size and model performance in vision-language large models. The key takeaway is that bigger encoders are not always better, and that a one-size-fits-all approach to scaling may not be the most effective strategy.
The findings emphasize the importance of task-specific optimization and the need to balance the encoder capacity with other model components. These insights can inform the design and development of more efficient and effective vision-language large models, with potential implications for a wide range of applications, from image recognition to multimodal information retrieval.
As the field of vision-language AI continues to evolve, this paper serves as a valuable contribution to our understanding of the underlying principles and tradeoffs involved in scaling these complex models. It encourages researchers and practitioners to think critically about the role of encoder size and to explore more nuanced approaches to model design and optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Are Bigger Encoders Always Better in Vision Large Models?
Bozhou Li, Hao Liang, Zimo Meng, Wentao Zhang
In recent years, multimodal large language models (MLLMs) have shown strong potential in real-world applications. They are developing rapidly due to their remarkable ability to comprehend multimodal information and their inherent powerful cognitive and reasoning capabilities. Among MLLMs, vision language models (VLM) stand out for their ability to understand vision information. However, the scaling trend of VLMs under the current mainstream paradigm has not been extensively studied. Whether we can achieve better performance by training even larger models is still unclear. To address this issue, we conducted experiments on the pretraining stage of MLLMs. We conduct our experiment using different encoder sizes and large language model (LLM) sizes. Our findings indicate that merely increasing the size of encoders does not necessarily enhance the performance of VLMs. Moreover, we analyzed the effects of LLM backbone parameter size and data quality on the pretraining outcomes. Additionally, we explored the differences in scaling laws between LLMs and VLMs.
Read more8/2/2024
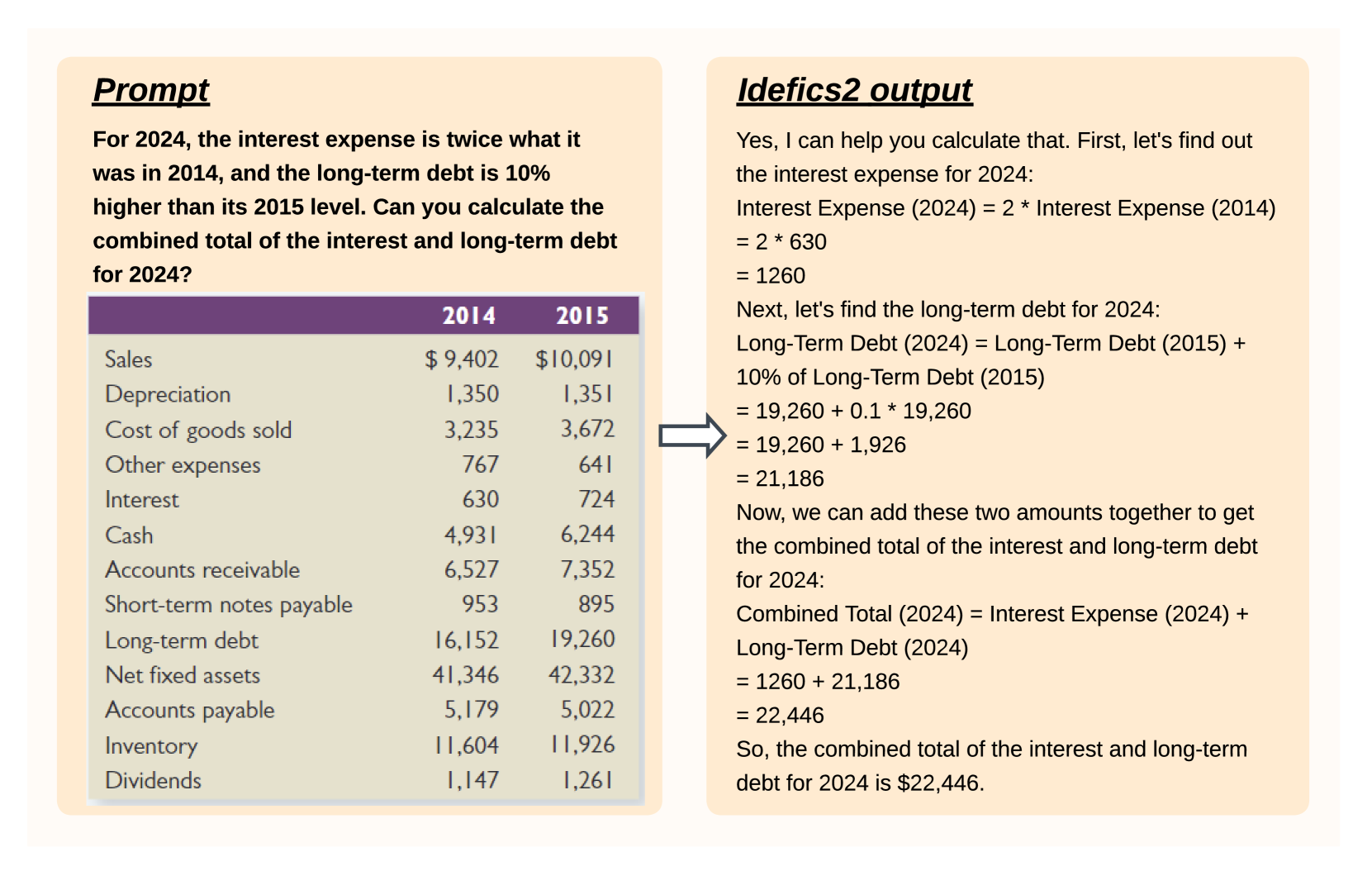
0
What matters when building vision-language models?
Hugo Laurenc{c}on, L'eo Tronchon, Matthieu Cord, Victor Sanh
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
Read more5/6/2024

0
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment
Kun Luo, Minghao Qin, Zheng Liu, Shitao Xiao, Jun Zhao, Kang Liu
Pretrained language models like BERT and T5 serve as crucial backbone encoders for dense retrieval. However, these models often exhibit limited generalization capabilities and face challenges in improving in domain accuracy. Recent research has explored using large language models (LLMs) as retrievers, achieving SOTA performance across various tasks. Despite these advancements, the specific benefits of LLMs over traditional retrievers and the impact of different LLM configurations, such as parameter sizes, pretraining duration, and alignment processes on retrieval tasks remain unclear. In this work, we conduct a comprehensive empirical study on a wide range of retrieval tasks, including in domain accuracy, data efficiency, zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. We evaluate over 15 different backbone LLMs and non LLMs. Our findings reveal that larger models and extensive pretraining consistently enhance in domain accuracy and data efficiency. Additionally, larger models demonstrate significant potential in zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. These results underscore the advantages of LLMs as versatile and effective backbone encoders in dense retrieval, providing valuable insights for future research and development in this field.
Read more8/26/2024
🤔
125
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
Read more4/22/2024