Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment

0

Sign in to get full access
Overview
- This paper provides a comprehensive empirical assessment of large language models (LLMs) as foundations for next-generation dense retrieval systems.
- The authors explore the effectiveness of various LLM-based approaches for retrieval tasks across multiple datasets.
- The findings offer insights into the potential of LLMs as powerful building blocks for advanced information retrieval systems.
Plain English Explanation
The paper examines how large language models (LLMs) - powerful AI systems trained on vast amounts of text data - can be used as the foundation for dense retrieval systems. These are information retrieval systems that can quickly and accurately find relevant information from large document collections.
The researchers tested different ways of incorporating LLMs into retrieval models and evaluated their performance on various datasets. They found that LLMs can indeed serve as reliable knowledge bases and provide significant benefits for retrieval tasks.
This work provides insights into how advanced language models can be leveraged as powerful building blocks for the next generation of information retrieval systems. The results suggest that larger encoders are not always better for certain applications, and that careful integration of LLMs is key for enhanced knowledge representation and effective retrieval performance.
Technical Explanation
The paper investigates the use of large language models (LLMs) as foundations for dense retrieval systems. The authors explore various approaches for incorporating LLMs into retrieval models and evaluate their performance on multiple datasets, including MS MARCO, TREC-DL, and BEIR.
The key experiments and findings include:
-
LLM Configurations: The authors tested different ways of using LLMs, such as directly using the LLM's output as a representation, fine-tuning the LLM on the retrieval task, and combining the LLM with other components like a dual-encoder architecture.
-
Performance Evaluation: The retrieval models were evaluated on metrics like Recall@k and Normalized Discounted Cumulative Gain (NDCG), which measure how well the systems can rank relevant documents.
-
Insights and Findings: The results showed that LLM-based approaches generally outperformed traditional retrieval baselines. However, the researchers also found that larger LLMs did not always lead to better performance, suggesting the importance of careful model design and integration.
The paper provides a comprehensive empirical assessment of LLMs as foundations for dense retrieval systems, offering valuable insights for researchers and practitioners working on advanced information retrieval solutions.
Critical Analysis
The paper provides a thorough and well-designed empirical evaluation of using large language models (LLMs) for dense retrieval tasks. The authors acknowledge several limitations and areas for further research:
-
Dataset Diversity: The evaluation was primarily conducted on English-language datasets, and the authors suggest exploring the performance of LLM-based retrieval on more diverse, multilingual datasets.
-
Efficiency Considerations: While the paper focuses on effectiveness (retrieval quality), the authors note the importance of also considering efficiency aspects, such as inference latency and indexing costs, in real-world deployment scenarios.
-
Interpretability and Explainability: The paper does not delve into the interpretability and explainability of the LLM-based retrieval models, which could be an important consideration for certain applications.
-
Potential Biases: As with any large-scale language model, there may be inherent biases present in the LLMs used, which could influence the retrieval results. The authors do not address this issue in-depth.
Overall, the paper makes a compelling case for the potential of LLMs as powerful foundations for next-generation dense retrieval systems. However, the practical deployment of these models will likely require further research and consideration of various technical and ethical factors.
Conclusion
This comprehensive study demonstrates the promise of large language models (LLMs) as effective building blocks for advanced information retrieval systems. The empirical findings suggest that LLM-based approaches can outperform traditional retrieval baselines, offering insights into the integration of these powerful language models.
While the results are promising, the authors also highlight the need for further exploration, such as evaluating performance on more diverse datasets, considering efficiency trade-offs, and addressing interpretability and bias concerns. Nonetheless, this work represents an important step forward in the development of next-generation dense retrieval systems that leverage the knowledge and capabilities of large-scale language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment
Kun Luo, Minghao Qin, Zheng Liu, Shitao Xiao, Jun Zhao, Kang Liu
Pretrained language models like BERT and T5 serve as crucial backbone encoders for dense retrieval. However, these models often exhibit limited generalization capabilities and face challenges in improving in domain accuracy. Recent research has explored using large language models (LLMs) as retrievers, achieving SOTA performance across various tasks. Despite these advancements, the specific benefits of LLMs over traditional retrievers and the impact of different LLM configurations, such as parameter sizes, pretraining duration, and alignment processes on retrieval tasks remain unclear. In this work, we conduct a comprehensive empirical study on a wide range of retrieval tasks, including in domain accuracy, data efficiency, zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. We evaluate over 15 different backbone LLMs and non LLMs. Our findings reveal that larger models and extensive pretraining consistently enhance in domain accuracy and data efficiency. Additionally, larger models demonstrate significant potential in zero shot generalization, lengthy retrieval, instruction based retrieval, and multi task learning. These results underscore the advantages of LLMs as versatile and effective backbone encoders in dense retrieval, providing valuable insights for future research and development in this field.
Read more8/26/2024
0
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
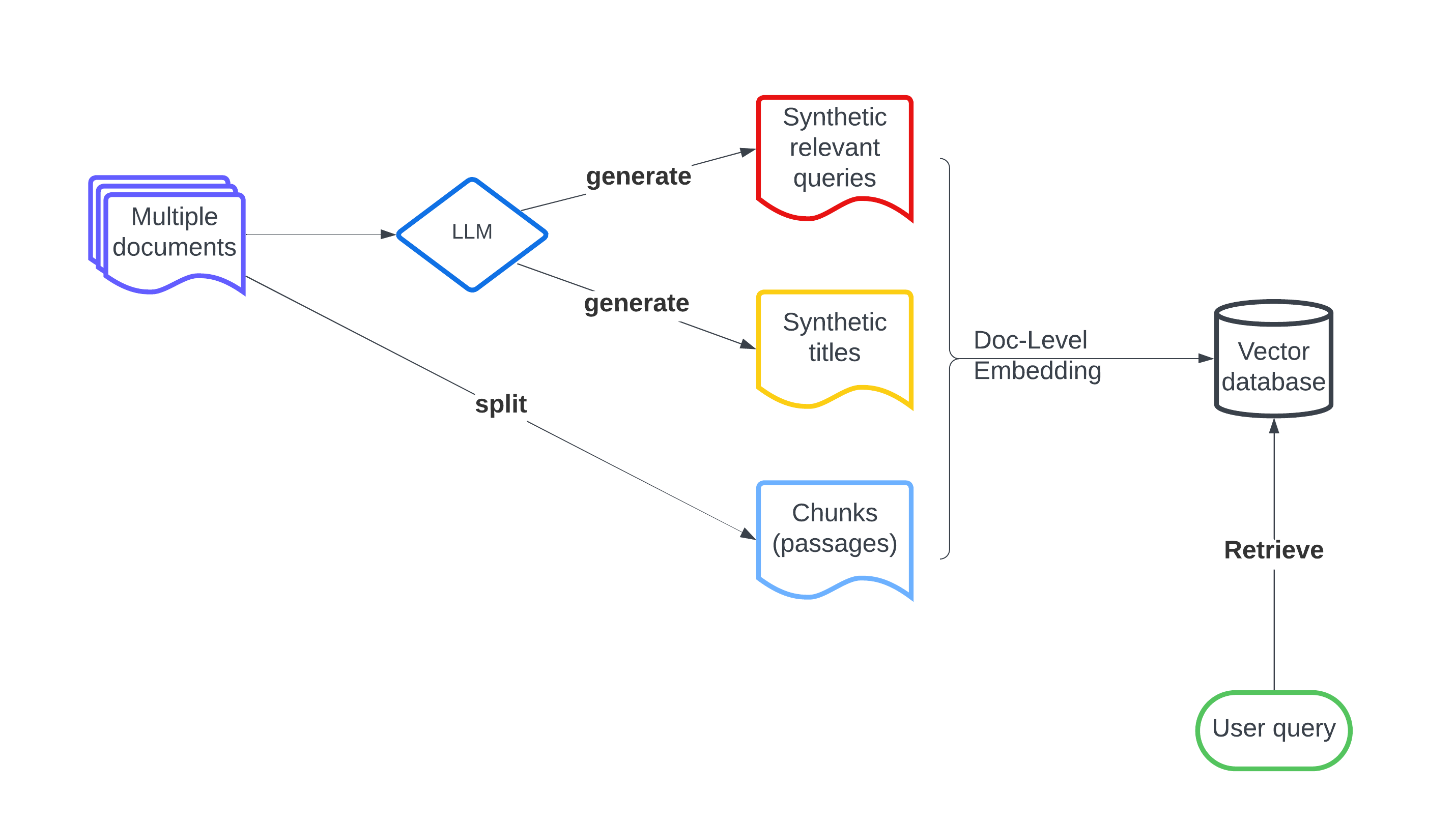
Mingrui Wu, Sheng Cao
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Read more4/10/2024

0
Large Language Models as Reliable Knowledge Bases?
Danna Zheng, Mirella Lapata, Jeff Z. Pan
The NLP community has recently shown a growing interest in leveraging Large Language Models (LLMs) for knowledge-intensive tasks, viewing LLMs as potential knowledge bases (KBs). However, the reliability and extent to which LLMs can function as KBs remain underexplored. While previous studies suggest LLMs can encode knowledge within their parameters, the amount of parametric knowledge alone is not sufficient to evaluate their effectiveness as KBs. This study defines criteria that a reliable LLM-as-KB should meet, focusing on factuality and consistency, and covering both seen and unseen knowledge. We develop several metrics based on these criteria and use them to evaluate 26 popular LLMs, while providing a comprehensive analysis of the effects of model size, instruction tuning, and in-context learning (ICL). Our results paint a worrying picture. Even a high-performant model like GPT-3.5-turbo is not factual or consistent, and strategies like ICL and fine-tuning are unsuccessful at making LLMs better KBs.
Read more7/19/2024
💬
1
Large Language Models for Information Retrieval: A Survey
Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Haonan Chen, Zheng Liu, Zhicheng Dou, Ji-Rong Wen
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions, such as search agents, within this expanding field.
Read more9/5/2024