Are Large Language Models Consistent over Value-laden Questions?

0

Sign in to get full access
Overview
- This paper investigates the consistency of large language models (LLMs) in their responses to value-laden questions.
- The researchers examine whether LLMs provide stable and coherent answers to ethical and political questions, or if their responses vary significantly across multiple prompts.
- The study aims to shed light on the reliability and robustness of LLMs when it comes to subjective, opinion-based topics.
Plain English Explanation
In this paper, the researchers explore whether large language models (LLMs) - powerful AI systems that can generate human-like text - are consistent in how they respond to questions on sensitive, value-laden topics. These could be ethical dilemmas, political issues, or other subjective questions without clear right or wrong answers.
The researchers wanted to see if LLMs would give stable, coherent responses to the same prompt, or if their answers would vary significantly. This is an important question because as LLMs become more advanced and integrated into our lives, we need to understand how reliable and trustworthy they are, especially on topics where there can be significant disagreement among humans.
The researchers designed experiments to test the consistency of LLM responses across multiple rounds of the same value-laden prompts. By analyzing the models' outputs, they aimed to shed light on whether LLMs can maintain a stable position on complex, opinion-based questions, or if they are more like chameleons, shifting their views to match the prompt.
Technical Explanation
The researchers conducted a series of experiments to assess the consistency of large language models (LLMs) when responding to value-laden questions. They collected a set of prompts covering ethical dilemmas, political issues, and other subjective topics, and presented these prompts to several popular LLMs, including GPT-3, Anthropic's InstructGPT, and Cohere's Generate.
For each prompt, the models were asked to generate multiple responses, and the researchers analyzed the consistency of these outputs. They looked for signs of context dependence and instability, where the models' positions or reasoning would shift significantly across repeated prompts.
The researchers also explored the relationship between the models' consistency and the perceived "easiness" or subjectivity of the prompt. They hypothesized that LLMs may be more consistent on straightforward factual questions, but struggle to maintain coherent stances on complex, value-laden issues.
Through their analysis, the researchers aimed to uncover insights into the moral and reasoning capabilities of LLMs, as well as their suitability for tasks that require stable and consistent decision-making.
Critical Analysis
The researchers acknowledge several limitations and caveats in their study. First, the set of prompts used may not be representative of the full spectrum of value-laden questions that LLMs could encounter in real-world applications. The researchers suggest that further research is needed to evaluate consistency across a broader range of topics and scenarios.
Additionally, the researchers note that their analysis focuses on the surface-level consistency of LLM responses, without delving deeper into the underlying reasoning or justifications provided by the models. It is possible that LLMs could exhibit inconsistencies in their logic or ethical frameworks, even if their final outputs appear superficially consistent.
Another potential concern is the influence of biases and training data on the LLMs' responses. The researchers suggest that the models' consistency (or lack thereof) may be partly a reflection of the biases and inconsistencies present in the data used to train them, rather than inherent limitations of the models themselves.
Conclusion
This research provides valuable insights into the consistency and reliability of large language models (LLMs) when it comes to value-laden questions. The findings suggest that while LLMs may be capable of generating coherent and plausible responses, their positions on complex, subjective topics can often be unstable and context-dependent.
These results have important implications for the deployment of LLMs in real-world applications that require stable and trustworthy decision-making, such as in policymaking, healthcare, or legal contexts. The paper highlights the need for further research and development to ensure that LLMs can maintain consistent, principled stances on important ethical and political issues.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Are Large Language Models Consistent over Value-laden Questions?
Jared Moore, Tanvi Deshpande, Diyi Yang
Large language models (LLMs) appear to bias their survey answers toward certain values. Nonetheless, some argue that LLMs are too inconsistent to simulate particular values. Are they? To answer, we first define value consistency as the similarity of answers across (1) paraphrases of one question, (2) related questions under one topic, (3) multiple-choice and open-ended use-cases of one question, and (4) multilingual translations of a question to English, Chinese, German, and Japanese. We apply these measures to a few large ($>=34b$), open LLMs including llama-3, as well as gpt-4o, using eight thousand questions spanning more than 300 topics. Unlike prior work, we find that models are relatively consistent across paraphrases, use-cases, translations, and within a topic. Still, some inconsistencies remain. Models are more consistent on uncontroversial topics (e.g., in the U.S., Thanksgiving) than on controversial ones (euthanasia). Base models are both more consistent compared to fine-tuned models and are uniform in their consistency across topics, while fine-tuned models are more inconsistent about some topics (euthanasia) than others (women's rights) like our human subjects (n=165).
Read more7/4/2024

0
Do LLMs have Consistent Values?
Naama Rozen, Gal Elidan, Amir Globerson, Ella Daniel
Values are a basic driving force underlying human behavior. Large Language Models (LLM) technology is constantly improving towards human-like dialogue. However, little research has been done to study the values exhibited in text generated by LLMs. Here we study this question by turning to the rich literature on value structure in psychology. We ask whether LLMs exhibit the same value structure that has been demonstrated in humans, including the ranking of values, and correlation between values. We show that the results of this analysis strongly depend on how the LLM is prompted, and that under a particular prompting strategy (referred to as 'Value Anchoring') the agreement with human data is quite compelling. Our results serve both to improve our understanding of values in LLMs, as well as introduce novel methods for assessing consistency in LLM responses.
Read more7/22/2024

0
Can Large Language Models Always Solve Easy Problems if They Can Solve Harder Ones?
Zhe Yang, Yichang Zhang, Tianyu Liu, Jian Yang, Junyang Lin, Chang Zhou, Zhifang Sui
Large language models (LLMs) have demonstrated impressive capabilities, but still suffer from inconsistency issues (e.g. LLMs can react differently to disturbances like rephrasing or inconsequential order change). In addition to these inconsistencies, we also observe that LLMs, while capable of solving hard problems, can paradoxically fail at easier ones. To evaluate this hard-to-easy inconsistency, we develop the ConsisEval benchmark, where each entry comprises a pair of questions with a strict order of difficulty. Furthermore, we introduce the concept of consistency score to quantitatively measure this inconsistency and analyze the potential for improvement in consistency by relative consistency score. Based on comprehensive experiments across a variety of existing models, we find: (1) GPT-4 achieves the highest consistency score of 92.2% but is still inconsistent to specific questions due to distraction by redundant information, misinterpretation of questions, etc.; (2) models with stronger capabilities typically exhibit higher consistency, but exceptions also exist; (3) hard data enhances consistency for both fine-tuning and in-context learning. Our data and code will be publicly available on GitHub.
Read more6/19/2024
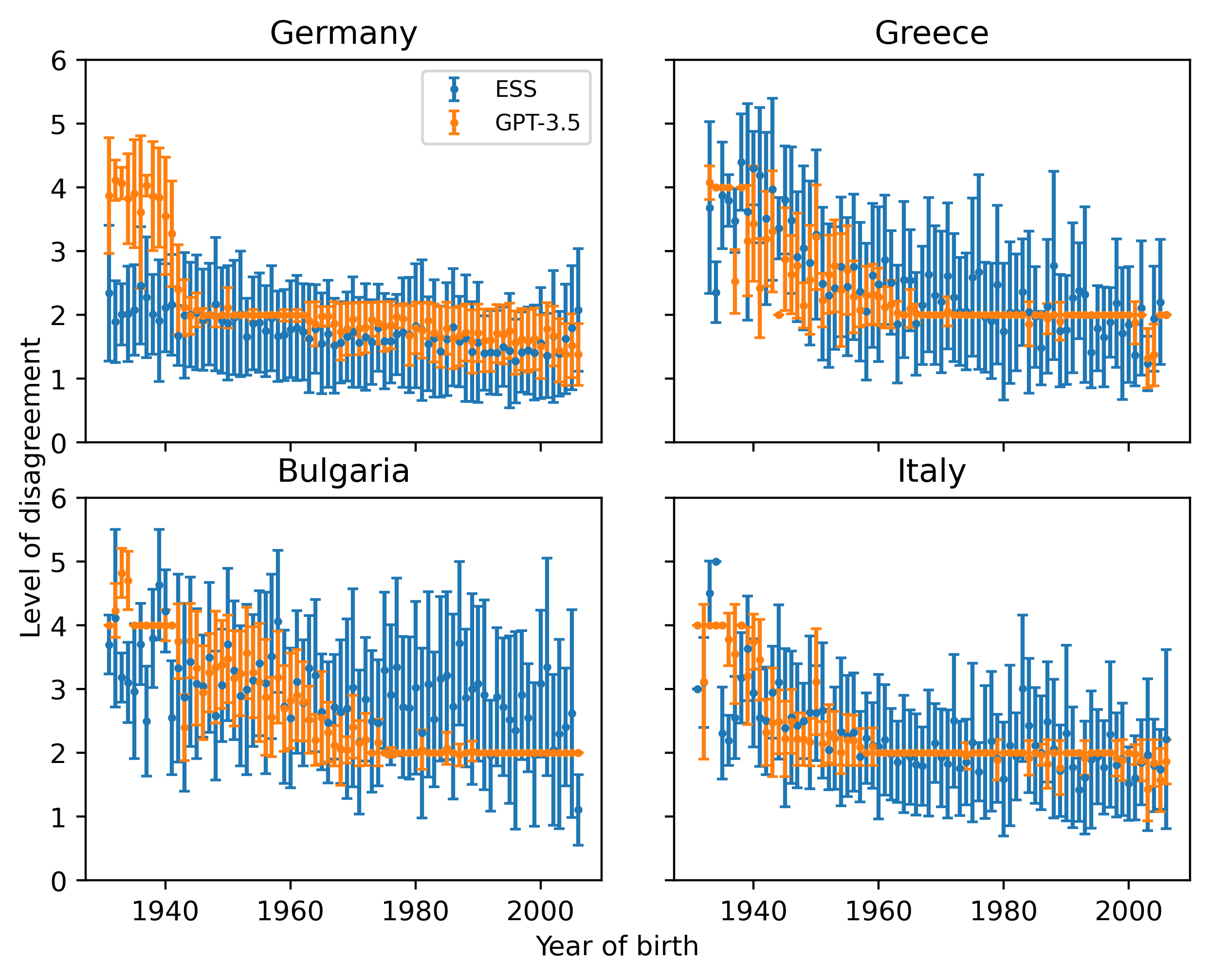
0
Are Large Language Models Chameleons?
Mingmeng Geng, Sihong He, Roberto Trotta
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
Read more5/30/2024