Are Linear Regression Models White Box and Interpretable?

0

Sign in to get full access
Overview
- Linear regression models are widely used in data analysis and machine learning
- There is a debate around whether these models are truly interpretable and "white box" in nature
- This paper examines the interpretability and transparency of linear regression models
Plain English Explanation
Linear regression is a common statistical technique used to model the relationship between a dependent variable and one or more independent variables. These models aim to find the best-fitting line that describes this relationship, allowing you to make predictions about the dependent variable based on the independent variables.
One of the key benefits often cited for linear regression models is their interpretability - the idea that you can easily understand how the independent variables are affecting the dependent variable, and why the model is making the predictions it is. This <a href="https://aimodels.fyi/papers/arxiv/calibrated-explanations-regression">interpretability</a> is seen as an advantage over more complex "black box" machine learning models.
However, this paper investigates whether linear regression models are truly as interpretable and transparent as commonly believed. The authors argue that while linear regression may appear simple on the surface, there are often hidden complexities and caveats that can limit its interpretability in practice. They explore the potential <a href="https://aimodels.fyi/papers/arxiv/privacy-implications-explainable-ai-data-driven-systems">privacy implications</a> of trying to explain these models, as well as the challenges of maintaining <a href="https://aimodels.fyi/papers/arxiv/model-interpretation-explainability-towards-creating-transparency-prediction">interpretability</a> as models become more sophisticated.
Overall, this paper provides a more nuanced look at the interpretability of linear regression, highlighting both its strengths and limitations when it comes to being a truly "white box" and transparent modeling approach.
Technical Explanation
The paper begins by acknowledging the widespread use of linear regression models in data analysis and machine learning, as well as the common perception that they are highly interpretable "white box" models. The authors then proceed to examine this assumption more closely.
They discuss how linear regression models work by finding the best-fitting line that describes the relationship between the dependent variable and the independent variables. The coefficients of this line can be used to quantify the effect of each independent variable on the dependent variable. This seems to provide a clear, intuitive way to understand how the model is making predictions.
However, the authors argue that there are several factors that can complicate the interpretability of linear regression models in practice. These include:
- <a href="https://aimodels.fyi/papers/arxiv/interpretability-symbolic-regression-benchmark-explanatory-methods-using">Interpretability</a> issues that arise as models become more complex, with multiple independent variables and potential interactions between them.
- The fact that linear regression coefficients can be sensitive to the scaling and centering of the independent variables, which may not be immediately obvious to the user.
- Potential <a href="https://aimodels.fyi/papers/arxiv/privacy-implications-explainable-ai-data-driven-systems">privacy implications</a> of trying to fully explain linear regression models, as this could reveal sensitive information about the training data.
The authors also discuss the challenges of maintaining interpretability as linear regression models are extended to incorporate more advanced techniques, such as regularization or non-linear transformations of the independent variables.
Critical Analysis
The paper raises some important points about the limitations of linear regression models when it comes to interpretability and transparency. While these models may appear straightforward on the surface, the authors demonstrate that there can be hidden complexities that can undermine their interpretability in practice.
One of the key strengths of this paper is that it avoids simply accepting the common perception of linear regression as a "white box" model. Instead, it takes a more nuanced and critical look at the potential issues that can arise, such as the sensitivity of coefficients to variable scaling and the privacy implications of trying to fully explain the model.
That said, the paper could have gone further in exploring potential solutions or mitigation strategies for these interpretability challenges. For example, it could have discussed techniques like <a href="https://aimodels.fyi/papers/arxiv/robustness-explainable-artificial-intelligence-industrial-process-modelling">robust explanations</a> or the use of feature importance measures to help improve the interpretability of linear regression models.
Overall, this paper provides a valuable counterpoint to the often-repeated narrative of linear regression as a highly interpretable modeling approach. It encourages readers to think more critically about the realities of model interpretability and the potential trade-offs involved.
Conclusion
This paper challenges the common perception of linear regression models as inherently "white box" and interpretable. While these models do provide a straightforward way to understand the relationships between variables, the authors demonstrate that there can be hidden complexities and caveats that can limit their interpretability in practice.
The paper's nuanced analysis of the potential interpretability issues with linear regression models is a valuable contribution to the ongoing debate around model transparency and explainability in data analysis and machine learning. It highlights the importance of critically examining the assumptions and limitations of even seemingly simple modeling techniques, and encourages further research into improving the interpretability and transparency of these widely used statistical tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Are Linear Regression Models White Box and Interpretable?
Ahmed M Salih, Yuhe Wang
Explainable artificial intelligence (XAI) is a set of tools and algorithms that applied or embedded to machine learning models to understand and interpret the models. They are recommended especially for complex or advanced models including deep neural network because they are not interpretable from human point of view. On the other hand, simple models including linear regression are easy to implement, has less computational complexity and easy to visualize the output. The common notion in the literature that simple models including linear regression are considered as white box because they are more interpretable and easier to understand. This is based on the idea that linear regression models have several favorable outcomes including the effect of the features in the model and whether they affect positively or negatively toward model output. Moreover, uncertainty of the model can be measured or estimated using the confidence interval. However, we argue that this perception is not accurate and linear regression models are not easy to interpret neither easy to understand considering common XAI metrics and possible challenges might face. This includes linearity, local explanation, multicollinearity, covariates, normalization, uncertainty, features contribution and fairness. Consequently, we recommend the so-called simple models should be treated equally to complex models when it comes to explainability and interpretability.
Read more7/18/2024
↗️
0
Calibrated Explanations for Regression
Tuwe Lofstrom, Helena Lofstrom, Ulf Johansson, Cecilia Sonstrod, Rudy Matela
Artificial Intelligence (AI) is often an integral part of modern decision support systems. The best-performing predictive models used in AI-based decision support systems lack transparency. Explainable Artificial Intelligence (XAI) aims to create AI systems that can explain their rationale to human users. Local explanations in XAI can provide information about the causes of individual predictions in terms of feature importance. However, a critical drawback of existing local explanation methods is their inability to quantify the uncertainty associated with a feature's importance. This paper introduces an extension of a feature importance explanation method, Calibrated Explanations, previously only supporting classification, with support for standard regression and probabilistic regression, i.e., the probability that the target is above an arbitrary threshold. The extension for regression keeps all the benefits of Calibrated Explanations, such as calibration of the prediction from the underlying model with confidence intervals, uncertainty quantification of feature importance, and allows both factual and counterfactual explanations. Calibrated Explanations for standard regression provides fast, reliable, stable, and robust explanations. Calibrated Explanations for probabilistic regression provides an entirely new way of creating probabilistic explanations from any ordinary regression model, allowing dynamic selection of thresholds. The method is model agnostic with easily understood conditional rules. An implementation in Python is freely available on GitHub and for installation using both pip and conda, making the results in this paper easily replicable.
Read more5/28/2024
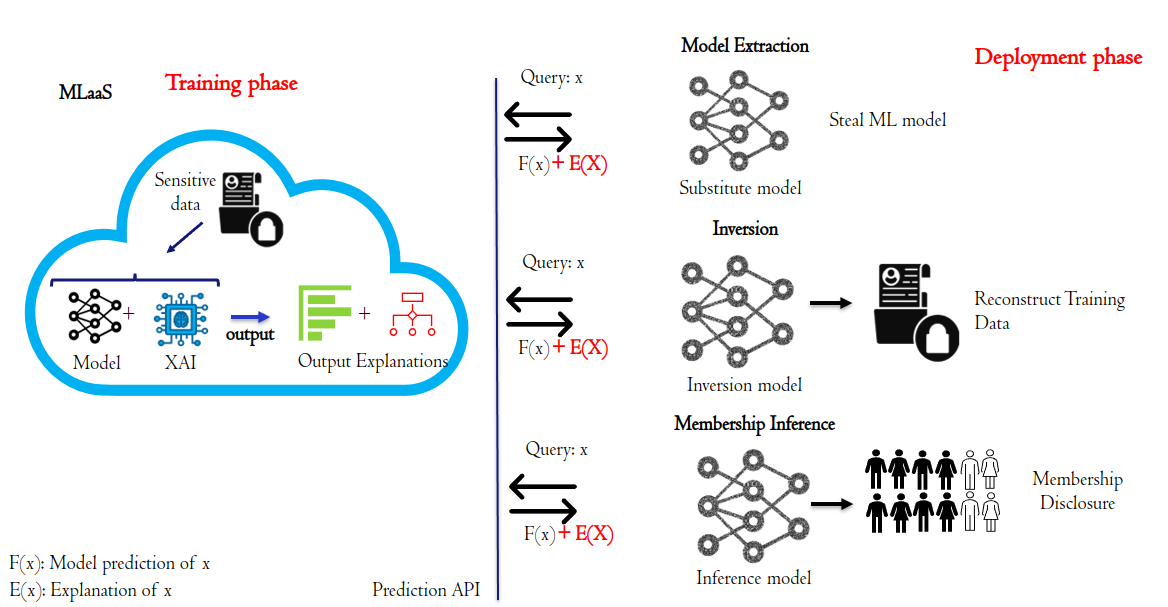
0
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
Read more6/26/2024
📈
0
Model Interpretation and Explainability: Towards Creating Transparency in Prediction Models
Donald Kridel, Jacob Dineen, Daniel Dolk, David Castillo
Explainable AI (XAI) has a counterpart in analytical modeling which we refer to as model explainability. We tackle the issue of model explainability in the context of prediction models. We analyze a dataset of loans from a credit card company and apply three stages: execute and compare four different prediction methods, apply the best known explainability techniques in the current literature to the model training sets to identify feature importance (FI) (static case), and finally to cross-check whether the FI set holds up under what if prediction scenarios for continuous and categorical variables (dynamic case). We found inconsistency in FI identification between the static and dynamic cases. We summarize the state of the art in model explainability and suggest further research to advance the field.
Read more6/3/2024