Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data
2402.17644
0
0
Abstract
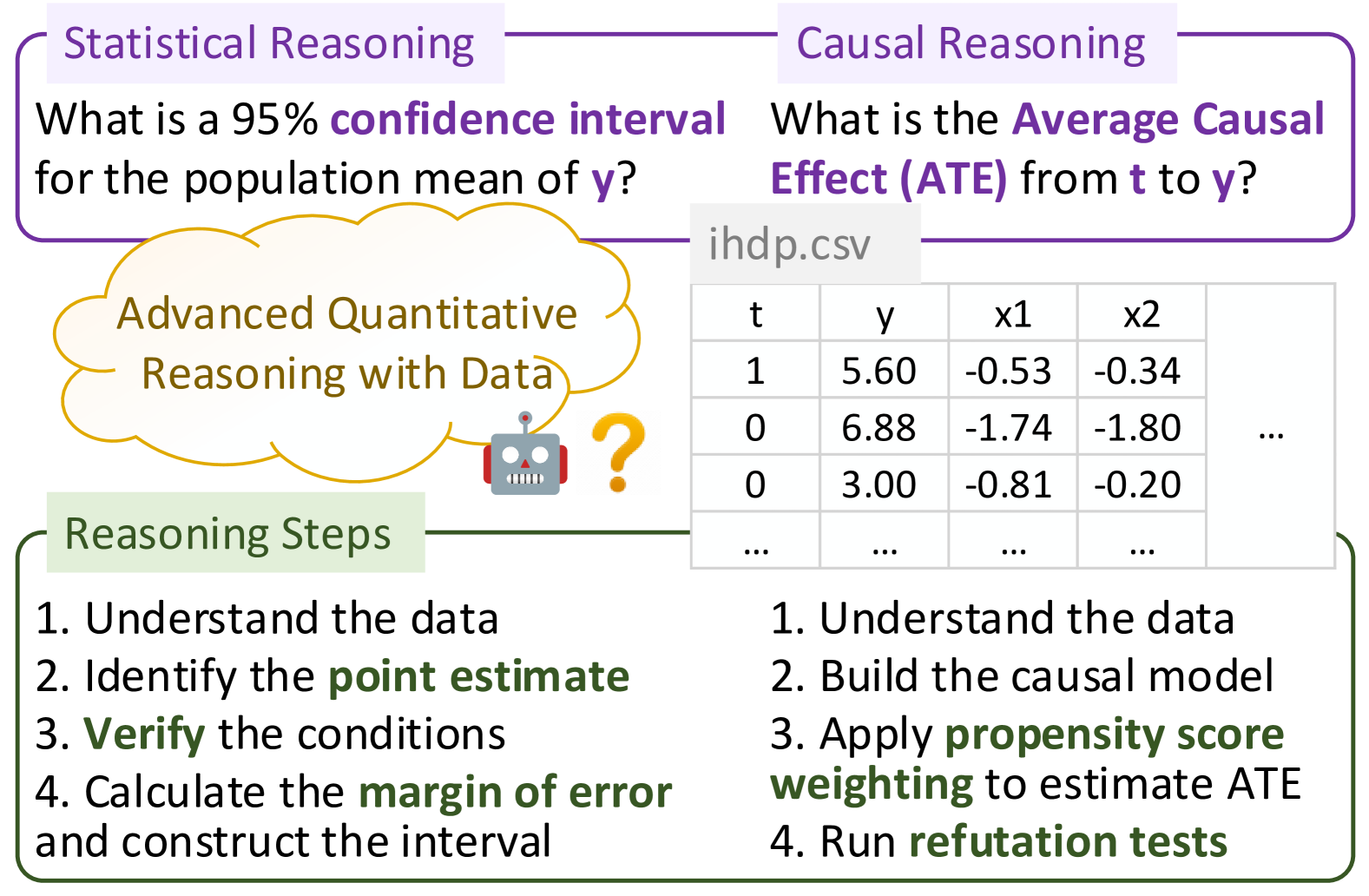
Quantitative reasoning is a critical skill to analyze data, yet the assessment of such ability remains limited. To address this gap, we introduce the Quantitative Reasoning with Data (QRData) benchmark, aiming to evaluate Large Language Models' capability in statistical and causal reasoning with real-world data. The benchmark comprises a carefully constructed dataset of 411 questions accompanied by data sheets from textbooks, online learning materials, and academic papers. To compare models' quantitative reasoning abilities on data and text, we enrich the benchmark with an auxiliary set of 290 text-only questions, namely QRText. We evaluate natural language reasoning, program-based reasoning, and agent reasoning methods including Chain-of-Thought, Program-of-Thoughts, ReAct, and code interpreter assistants on diverse models. The strongest model GPT-4 achieves an accuracy of 58%, which has much room for improvement. Among open-source models, Deepseek-coder-instruct, a code LLM pretrained on 2T tokens, gets the highest accuracy of 37%. Analysis reveals that models encounter difficulties in data analysis and causal reasoning, and struggle in using causal knowledge and provided data simultaneously. Code and data are in https://github.com/xxxiaol/QRData.
Create account to get full access
Overview
- This paper explores the abilities of large language models (LLMs) to perform advanced quantitative reasoning with data, including statistical and causal analysis.
- The researchers developed a benchmark called LogicBench to systematically evaluate LLMs' capabilities in this area.
- The benchmark covers a range of tasks, such as interpreting data visualizations, conducting regression analysis, and making causal inferences.
- The researchers tested several prominent LLMs, including GPT-3, on the benchmark and analyzed their performance.
Plain English Explanation
This paper investigates how well large language models, like the ones used in chatbots and digital assistants, can reason with data. The researchers created a set of tests, called a "benchmark," to evaluate the models' abilities in areas like interpreting graphs, running statistical analyses, and understanding cause-and-effect relationships.
The benchmark covers a variety of data-related tasks that require advanced quantitative skills. The researchers then tested several popular language models on this benchmark to see how they performed. This helps understand the current capabilities and limitations of these models when it comes to using and reasoning with data in a sophisticated way.
The findings from this research could have important implications for how we use and develop large language models, particularly in applications that involve data analysis, decision-making, or problem-solving. It sheds light on what these models can and cannot do when it comes to working with quantitative information.
Technical Explanation
The paper presents a new benchmark called LogicBench for evaluating the quantitative reasoning abilities of large language models (LLMs). The benchmark includes a diverse set of tasks that require the models to interpret data visualizations, perform regression analysis, make causal inferences, and engage in other advanced statistical and causal reasoning.
The researchers tested several prominent LLMs, including GPT-3, on the LogicBench tasks. They analyzed the models' performance across the different task categories to gain insights into their strengths, weaknesses, and limitations in data-based reasoning.
The results show that while LLMs can exhibit some competence in basic data analysis and interpretation, they struggle with more complex quantitative reasoning tasks that require deeper understanding of statistics, causal relationships, and logical inference. The models often make systematic errors or fail to provide coherent, justified responses, suggesting that they lack robust data-driven reasoning capabilities.
Critical Analysis
The paper provides a valuable contribution to the ongoing debate around the capabilities and limitations of large language models. By developing a targeted benchmark for quantitative reasoning, the researchers have shed light on an important aspect of LLM performance that is often overlooked.
One potential limitation of the study is the specific set of tasks included in the LogicBench. While the researchers aimed to cover a broad range of quantitative reasoning skills, there may be other important abilities that are not captured by the current benchmark. Future research could explore expanding the benchmark or developing complementary evaluation frameworks.
Additionally, the paper does not delve deeply into the underlying reasons for the LLMs' difficulties with the LogicBench tasks. Further investigation into the models' internal representations, reasoning mechanisms, and training data could help explain these limitations and inform future model development.
Despite these caveats, the paper's findings raise important questions about the extent to which current large language models can engage in meaningful data-driven analysis and decision-making. As these models become increasingly integrated into real-world applications, understanding their quantitative reasoning capabilities will be crucial for ensuring their safe and effective deployment.
Conclusion
This research paper makes a substantial contribution to the ongoing evaluation of large language models' abilities. By developing the LogicBench benchmark and testing prominent LLMs on a range of advanced quantitative reasoning tasks, the researchers have shed light on the current limitations of these models when it comes to data-based statistical and causal analysis.
The results highlight the need for further advancements in LLM development to enhance their data-driven reasoning capabilities. As these models become more widely deployed in applications involving decision-making, problem-solving, and real-world impact, it is crucial to understand their strengths and weaknesses in handling quantitative information and performing rigorous logical analysis.
Overall, this paper provides valuable insights that can inform the continued research and development of large language models, with the ultimate goal of creating AI systems that can reliably and transparently engage in sophisticated data-based reasoning to benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
0
0
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
6/7/2024

Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/28/2024

CriticBench: Benchmarking LLMs for Critique-Correct Reasoning
Zicheng Lin, Zhibin Gou, Tian Liang, Ruilin Luo, Haowei Liu, Yujiu Yang
0
0
The ability of Large Language Models (LLMs) to critique and refine their reasoning is crucial for their application in evaluation, feedback provision, and self-improvement. This paper introduces CriticBench, a comprehensive benchmark designed to assess LLMs' abilities to critique and rectify their reasoning across a variety of tasks. CriticBench encompasses five reasoning domains: mathematical, commonsense, symbolic, coding, and algorithmic. It compiles 15 datasets and incorporates responses from three LLM families. Utilizing CriticBench, we evaluate and dissect the performance of 17 LLMs in generation, critique, and correction reasoning, i.e., GQC reasoning. Our findings reveal: (1) a linear relationship in GQC capabilities, with critique-focused training markedly enhancing performance; (2) a task-dependent variation in correction effectiveness, with logic-oriented tasks being more amenable to correction; (3) GQC knowledge inconsistencies that decrease as model size increases; and (4) an intriguing inter-model critiquing dynamic, where stronger models are better at critiquing weaker ones, while weaker models can surprisingly surpass stronger ones in their self-critique. We hope these insights into the nuanced critique-correct reasoning of LLMs will foster further research in LLM critique and self-improvement.
6/4/2024
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
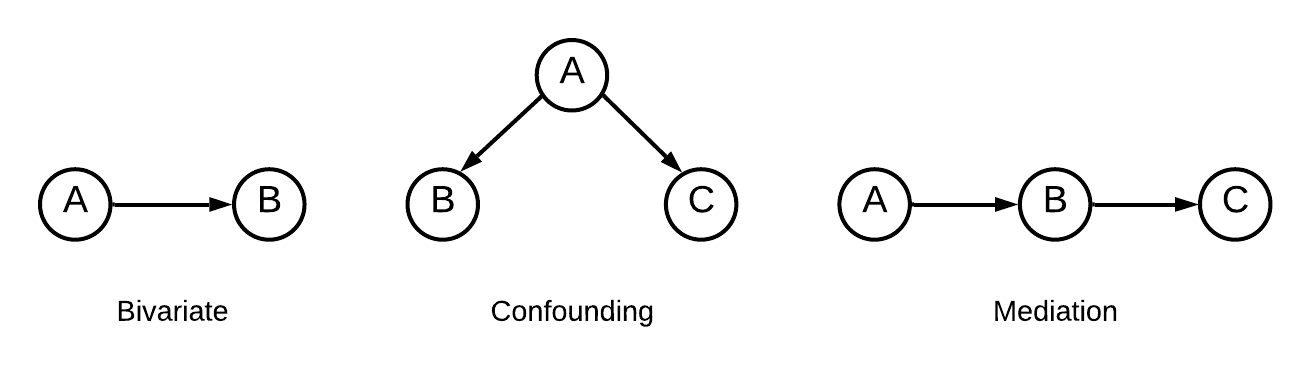
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024