Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP

0
Sign in to get full access
Overview
- This paper examines the design of tasks for long-context language models (LLMs) and whether they truly require long-context understanding or can be solved through retrieval alone.
- The authors argue that many existing long-context NLP tasks are not genuinely difficult and can be solved by LLMs with access to external information sources, rather than requiring deep long-context reasoning.
- They propose a new task design approach to create more challenging long-context tasks that push the boundaries of LLM capabilities.
Plain English Explanation
The paper explores the issue of whether current long-context language tasks genuinely require LLMs to understand and reason over long stretches of text, or if they can be solved more simply by retrieving relevant information from external sources.
The authors note that many existing long-context NLP tasks, such as question answering on long documents or summarization of lengthy passages, may not actually be as difficult as they seem. LLMs may be able to find the necessary information through retrieval from a knowledge base rather than having to deeply understand and reason over the full long-context.
The researchers propose a new approach to designing long-context tasks that are more genuinely challenging, forcing LLMs to go beyond simple retrieval and truly engage with the long-context in order to succeed. Their goal is to push the boundaries of what LLMs can do with long-context information, rather than relying on shortcuts.
Technical Explanation
The paper begins by noting that many existing "long-context" NLP tasks, such as question answering on long documents or summarization of lengthy passages, may not actually require deep long-context understanding. The authors hypothesize that LLMs can often solve these tasks through retrieval of relevant information rather than true long-range reasoning.
To test this, the researchers propose a new task design approach focused on creating more genuinely challenging long-context tasks. Their key insight is that tasks should require LLMs to integrate information dispersed throughout the long-context, rather than being solvable by simply retrieving a few key facts.
They illustrate this through a case study on context learning in long-context models. The authors show that even state-of-the-art LLMs struggle with tasks that demand deep reasoning about the relationships between dispersed pieces of information in long passages.
The paper's main contribution is this new task design methodology, which the authors argue is essential for pushing the boundaries of long-context NLP and driving genuine progress in LLM capabilities. By creating more challenging long-context tasks, the field can move beyond the current limitations of retrieval-based approaches.
Critical Analysis
The paper makes a compelling case that many existing long-context NLP tasks may be solvable through retrieval rather than true long-range reasoning. This is an important insight, as it suggests that progress in this area may be overstated if the tasks do not genuinely test LLM capabilities.
However, the authors' proposed approach for designing more challenging long-context tasks could be further refined. While the case study on context learning is illustrative, additional examples and more rigorous evaluations would strengthen the generalizability of their findings.
Additionally, the paper does not address potential issues around the scalability of their task design approach. Developing genuinely difficult long-context tasks may require significant manual effort and domain expertise, which could limit its practical application.
Further research is also needed to understand the cognitive processes and architectural requirements for LLMs to succeed on these more challenging long-context tasks. The paper hints at this direction, but does not delve deeply into the underlying mechanisms.
Overall, this paper offers a valuable perspective on the limitations of current long-context NLP tasks and the need for more rigorous task design. By pushing the field towards genuinely difficult long-context challenges, the authors aim to spur progress in the development of LLMs with true long-range reasoning capabilities.
Conclusion
This paper challenges the assumption that current "long-context" NLP tasks are truly testing the limits of language model understanding. The authors argue that many of these tasks can be solved through retrieval of relevant information, rather than requiring deep reasoning over long passages of text.
To address this, the researchers propose a new task design methodology focused on creating more genuinely difficult long-context challenges. By forcing LLMs to integrate dispersed information and go beyond simple lookup, these tasks could help drive progress towards models with genuine long-range reasoning capabilities.
While the paper's findings are compelling, further research is needed to refine the task design approach and explore the underlying cognitive processes involved. Nonetheless, this work represents an important step towards pushing the boundaries of long-context NLP and unlocking the true potential of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP
Omer Goldman, Alon Jacovi, Aviv Slobodkin, Aviya Maimon, Ido Dagan, Reut Tsarfaty
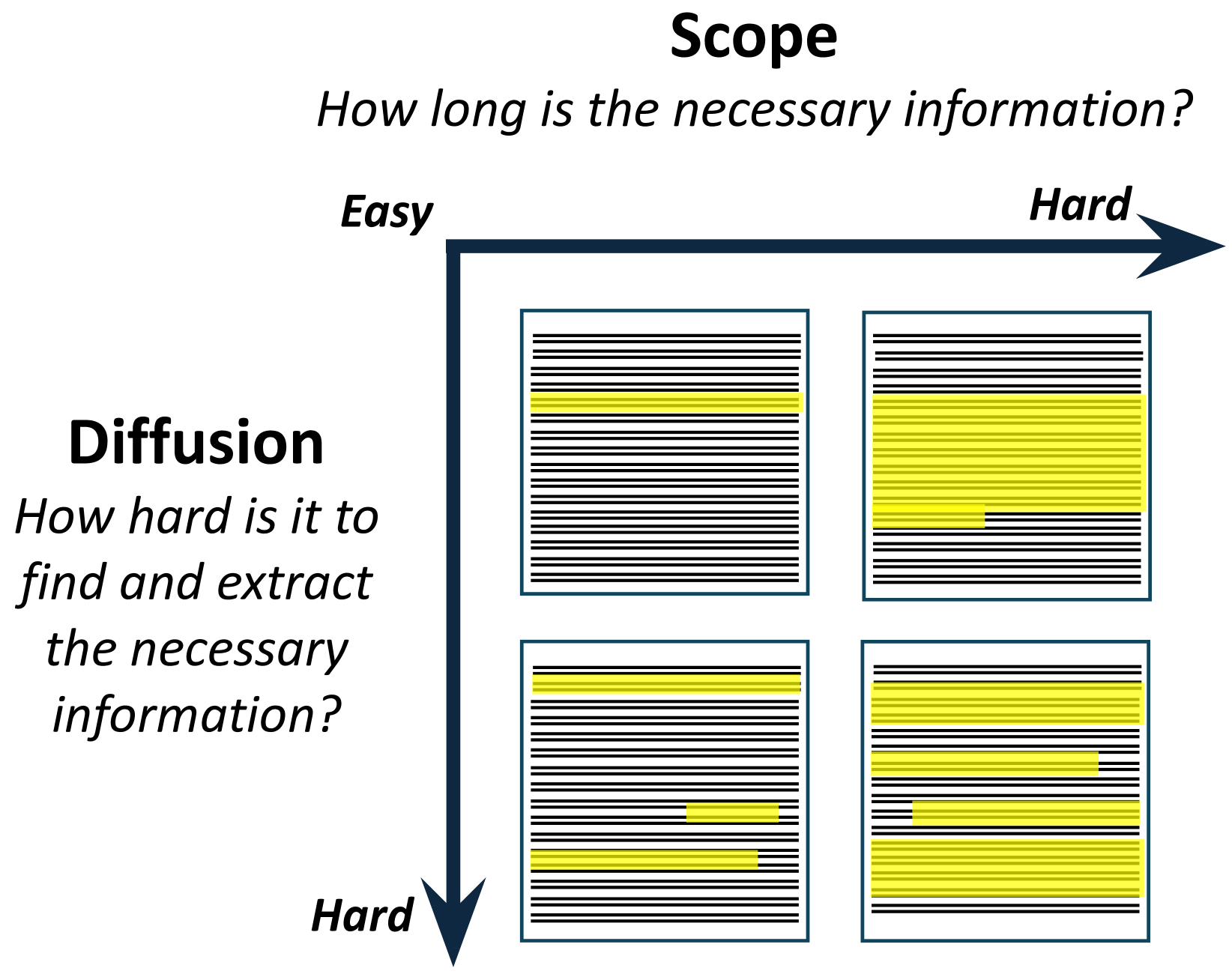
Improvements in language models' capabilities have pushed their applications towards longer contexts, making long-context evaluation and development an active research area. However, many disparate use-cases are grouped together under the umbrella term of long-context, defined simply by the total length of the model's input, including - for example - Needle-in-a-Haystack tasks, book summarization, and information aggregation. Given their varied difficulty, in this position paper we argue that conflating different tasks by their context length is unproductive. As a community, we require a more precise vocabulary to understand what makes long-context tasks similar or different. We propose to unpack the taxonomy of long-context based on the properties that make them more difficult with longer contexts. We propose two orthogonal axes of difficulty: (I) Diffusion: How hard is it to find the necessary information in the context? (II) Scope: How much necessary information is there to find? We survey the literature on long-context, provide justification for this taxonomy as an informative descriptor, and situate the literature with respect to it. We conclude that the most difficult and interesting settings, whose necessary information is very long and highly diffused within the input, is severely under-explored. By using a descriptive vocabulary and discussing the relevant properties of difficulty in long-context, we can implement more informed research in this area. We call for a careful design of tasks and benchmarks with distinctly long context, taking into account the characteristics that make it qualitatively different from shorter context.
Read more7/12/2024

0
Long-context LLMs Struggle with Long In-context Learning
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, Wenhu Chen
Large Language Models (LLMs) have made significant strides in handling long sequences. Some models like Gemini could even to be capable of dealing with millions of tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their true abilities in more challenging, real-world scenarios. We introduce a benchmark (LongICLBench) for long in-context learning in extreme-label classification using six datasets with 28 to 174 classes and input lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate on 15 long-context LLMs and find that they perform well on less challenging classification tasks with smaller label space and shorter demonstrations. However, they struggle with more challenging task like Discovery with 174 labels, suggesting a gap in their ability to process long, context-rich sequences. Further analysis reveals a bias towards labels presented later in the sequence and a need for improved reasoning over multiple pieces of information. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
Read more6/13/2024

0
A Controlled Study on Long Context Extension and Generalization in LLMs
Yi Lu, Jing Nathan Yan, Songlin Yang, Justin T. Chiu, Siyu Ren, Fei Yuan, Wenting Zhao, Zhiyong Wu, Alexander M. Rush
Broad textual understanding and in-context learning require language models that utilize full document contexts. Due to the implementation challenges associated with directly training long-context models, many methods have been proposed for extending models to handle long contexts. However, owing to differences in data and model classes, it has been challenging to compare these approaches, leading to uncertainty as to how to evaluate long-context performance and whether it differs from standard evaluation. We implement a controlled protocol for extension methods with a standardized evaluation, utilizing consistent base models and extension data. Our study yields several insights into long-context behavior. First, we reaffirm the critical role of perplexity as a general-purpose performance indicator even in longer-context tasks. Second, we find that current approximate attention methods systematically underperform across long-context tasks. Finally, we confirm that exact fine-tuning based methods are generally effective within the range of their extension, whereas extrapolation remains challenging. All codebases, models, and checkpoints will be made available open-source, promoting transparency and facilitating further research in this critical area of AI development.
Read more9/24/2024

0
Are Long-LLMs A Necessity For Long-Context Tasks?
Hongjin Qian, Zheng Liu, Peitian Zhang, Kelong Mao, Yujia Zhou, Xu Chen, Zhicheng Dou
The learning and deployment of long-LLMs remains a challenging problem despite recent progresses. In this work, we argue that the long-LLMs are not a necessity to solve long-context tasks, as common long-context tasks are short-context solvable, i.e. they can be solved by purely working with oracle short-contexts within the long-context tasks' inputs. On top of this argument, we propose a framework called LC-Boost (Long-Context Bootstrapper), which enables a short-LLM to address the long-context tasks in a bootstrapping manner. In our framework, the short-LLM prompts itself to reason for two critical decisions: 1) how to access to the appropriate part of context within the input, 2) how to make effective use of the accessed context. By adaptively accessing and utilizing the context based on the presented tasks, LC-Boost can serve as a general framework to handle diversified long-context processing problems. We comprehensively evaluate different types of tasks from popular long-context benchmarks, where LC-Boost is able to achieve a substantially improved performance with a much smaller consumption of resource.
Read more5/27/2024