Are PPO-ed Language Models Hackable?
2406.02577
0
0
Abstract
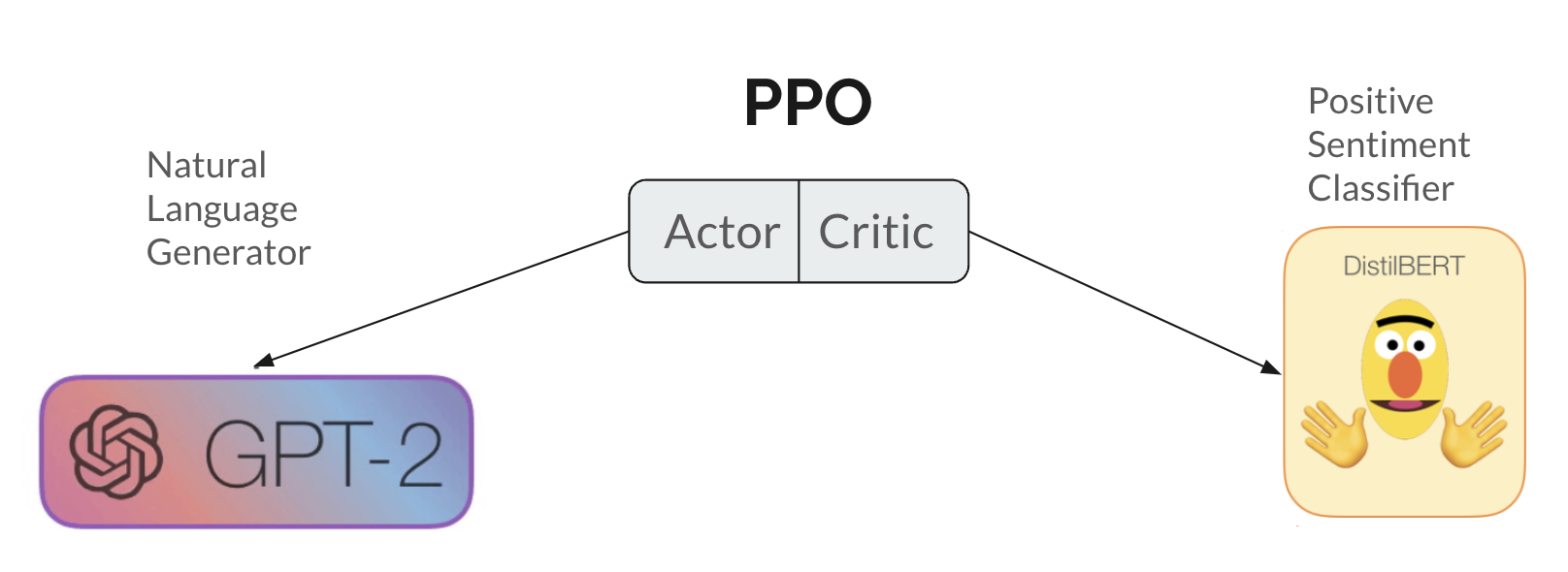
Numerous algorithms have been proposed to $textit{align}$ language models to remove undesirable behaviors. However, the challenges associated with a very large state space and creating a proper reward function often result in various jailbreaks. Our paper aims to examine this effect of reward in the controlled setting of positive sentiment language generation. Instead of online training of a reward model based on human feedback, we employ a statically learned sentiment classifier. We also consider a setting where our model's weights and activations are exposed to an end-user after training. We examine a pretrained GPT-2 through the lens of mechanistic interpretability before and after proximal policy optimization (PPO) has been applied to promote positive sentiment responses. Using these insights, we (1) attempt to hack the PPO-ed model to generate negative sentiment responses and (2) add a term to the reward function to try and alter `negative' weights.
Create account to get full access
Overview
- This paper investigates whether language models trained using Proximal Policy Optimization (PPO) are susceptible to hacking or manipulation.
- The authors explore the security and robustness of PPO-optimized language models, analyzing their potential vulnerabilities.
- They conduct experiments to assess the model's response to adversarial inputs and its ability to maintain alignment with intended behaviors.
Plain English Explanation
The paper examines whether language models that have been trained using a technique called Proximal Policy Optimization (PPO) can be "hacked" or manipulated. PPO is a method used to train AI models, including large language models, to behave in certain ways. The researchers wanted to see if these PPO-trained models are vulnerable to attacks or if they can maintain their intended behaviors even when faced with adversarial inputs.
To do this, the researchers conducted experiments to test the models' responses to different types of inputs, including those designed to try to get the models to behave in unintended ways. They looked at how the models performed and whether they were able to stay aligned with their original training objectives, even when challenged.
The findings from this research could have important implications for the security and reliability of language models, especially as they become more advanced and widely used. Understanding the potential vulnerabilities of these models is crucial for ensuring they can be deployed safely and reliably.
Technical Explanation
The paper explores the security and robustness of language models trained using Proximal Policy Optimization (PPO), a popular reinforcement learning algorithm. The authors investigate whether these PPO-optimized models are susceptible to hacking or manipulation, and analyze their ability to maintain alignment with intended behaviors.
Through a series of experiments, the researchers assess the models' responses to adversarial inputs designed to exploit potential vulnerabilities. They evaluate the models' performance and their capacity to remain aligned with their original training objectives, even when presented with challenging or adversarial stimuli.
The findings from this study have important implications for the deployment and security of advanced language models, as they become increasingly prevalent in real-world applications. Understanding the potential weaknesses of these models is crucial for ensuring they can be reliably and safely used, especially in sensitive or high-stakes scenarios.
Critical Analysis
The paper provides a thorough investigation of the security and robustness of PPO-optimized language models, which is an important area of research given the growing ubiquity of these models. The authors' experimental approach is rigorous, and the results offer valuable insights into the potential vulnerabilities of these systems.
However, the paper does not extensively discuss the broader context of language model security and potential attack vectors beyond the specific experiments conducted. While the findings are significant, there may be other ways in which these models could be exploited or manipulated that are not covered in the study.
Additionally, the paper does not delve into potential mitigation strategies or defense mechanisms that could be developed to enhance the security and reliability of PPO-optimized language models. Further research in this direction could be valuable for strengthening the overall security of these systems.
Conclusion
This paper presents a comprehensive analysis of the security and robustness of language models trained using Proximal Policy Optimization (PPO). The researchers conduct experiments to assess the models' susceptibility to hacking or manipulation, and their ability to maintain alignment with intended behaviors.
The findings from this study have important implications for the deployment and use of advanced language models, as they become increasingly prevalent in real-world applications. Understanding the potential vulnerabilities of these systems is crucial for ensuring they can be reliably and safely utilized, especially in sensitive or high-stakes scenarios.
The paper contributes to the growing body of research on language model security and provides a solid foundation for future work in this critical area. Continued investigation and development of robust defense mechanisms will be essential for the responsible and trustworthy deployment of these powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Robust Prompt Optimization for Defending Language Models Against Jailbreaking Attacks
Andy Zhou, Bo Li, Haohan Wang
0
0
Despite advances in AI alignment, large language models (LLMs) remain vulnerable to adversarial attacks or jailbreaking, in which adversaries can modify prompts to induce unwanted behavior. While some defenses have been proposed, they have not been adapted to newly proposed attacks and more challenging threat models. To address this, we propose an optimization-based objective for defending LLMs against jailbreaking attacks and an algorithm, Robust Prompt Optimization (RPO) to create robust system-level defenses. Our approach directly incorporates the adversary into the defensive objective and optimizes a lightweight and transferable suffix, enabling RPO to adapt to worst-case adaptive attacks. Our theoretical and experimental results show improved robustness to both jailbreaks seen during optimization and unknown jailbreaks, reducing the attack success rate (ASR) on GPT-4 to 6% and Llama-2 to 0% on JailbreakBench, setting the state-of-the-art. Code can be found at https://github.com/lapisrocks/rpo
6/7/2024

Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
0
0
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
6/6/2024
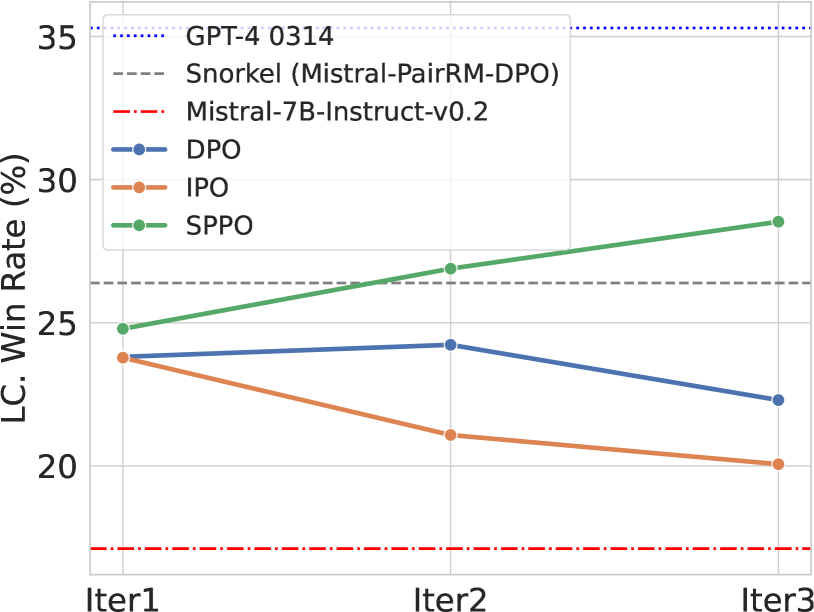
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
0
0
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed Self-Play Preference Optimization (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys a theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Starting from a stronger base model Llama-3-8B-Instruct, we are able to achieve a length-controlled win rate of 38.77%. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models. Codes are available at https://github.com/uclaml/SPPO.
6/17/2024
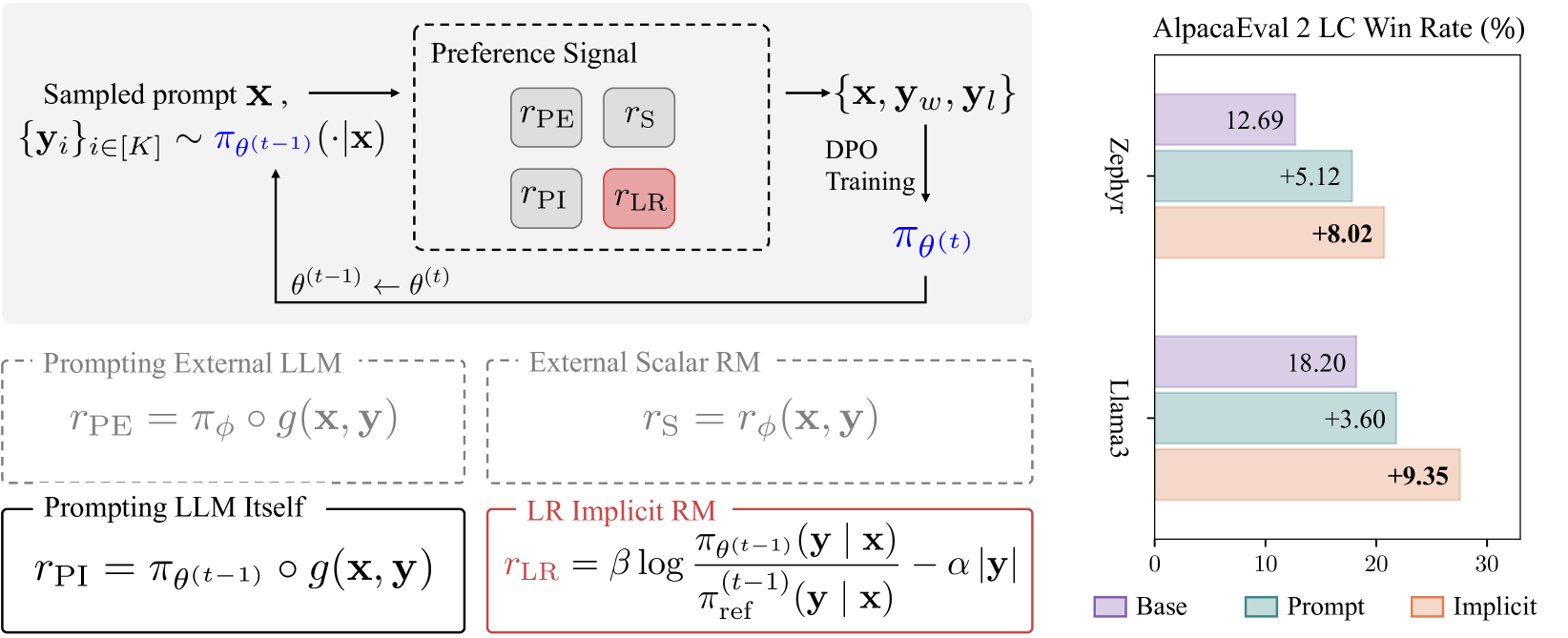
Bootstrapping Language Models with DPO Implicit Rewards
Changyu Chen, Zichen Liu, Chao Du, Tianyu Pang, Qian Liu, Arunesh Sinha, Pradeep Varakantham, Min Lin
0
0
Human alignment in large language models (LLMs) is an active area of research. A recent groundbreaking work, direct preference optimization (DPO), has greatly simplified the process from past work in reinforcement learning from human feedback (RLHF) by bypassing the reward learning stage in RLHF. DPO, after training, provides an implicit reward model. In this work, we make a novel observation that this implicit reward model can by itself be used in a bootstrapping fashion to further align the LLM. Our approach is to use the rewards from a current LLM model to construct a preference dataset, which is then used in subsequent DPO rounds. We incorporate refinements that debias the length of the responses and improve the quality of the preference dataset to further improve our approach. Our approach, named self-alignment with DPO ImpliCit rEwards (DICE), shows great improvements in alignment and achieves superior performance than Gemini Pro on AlpacaEval 2, reaching 27.55% length-controlled win rate against GPT-4 Turbo, but with only 8B parameters and no external feedback. Our code is available at https://github.com/sail-sg/dice.
6/17/2024