Arrows of Time for Large Language Models
2401.17505
6
0
Abstract
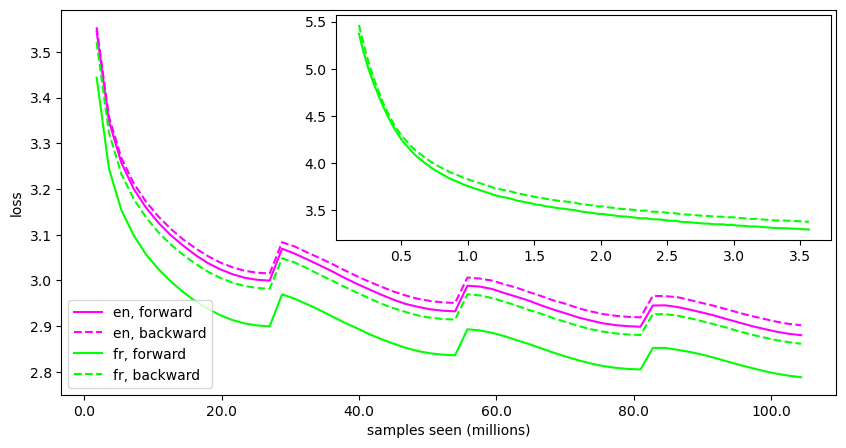
We study the probabilistic modeling performed by Autoregressive Large Language Models (LLMs) through the angle of time directionality, addressing a question first raised in (Shannon, 1951). For large enough models, we empirically find a time asymmetry in their ability to learn natural language: a difference in the average log-perplexity when trying to predict the next token versus when trying to predict the previous one. This difference is at the same time subtle and very consistent across various modalities (language, model size, training time, ...). Theoretically, this is surprising: from an information-theoretic point of view, there should be no such difference. We provide a theoretical framework to explain how such an asymmetry can appear from sparsity and computational complexity considerations, and outline a number of perspectives opened by our results.
Create account to get full access
Overview
- This paper explores the concept of "arrows of time" in the context of large language models (LLMs), which are powerful AI systems trained on vast amounts of text data.
- The authors investigate how the directionality of time affects the behavior and capabilities of LLMs, particularly in the realm of autoregressive modeling, where the model generates text one word at a time.
- The paper provides insights into the fundamental characteristics of LLMs and how they process temporal information, with implications for their use in tasks like time series forecasting and zero-shot learning.
Plain English Explanation
Large language models (LLMs) are AI systems that have been trained on massive amounts of text data, allowing them to generate human-like text and perform a wide range of language-related tasks. In this paper, the researchers explore how the directionality of time, or the "arrow of time," affects the way these LLMs process and generate text.
Imagine you're reading a book and trying to predict the next word. As you read from left to right, you're moving forward in time, and your predictions are based on the context of the words that came before. This is the way autoregressive LLMs work – they generate text one word at a time, using the previous words as a guide.
The researchers in this paper investigate how this forward-in-time perspective shapes the capabilities and limitations of LLMs. They look at how the arrow of time influences tasks like time series forecasting, where the model needs to predict future values based on past data, and zero-shot learning, where the model is asked to perform a task it hasn't been explicitly trained for.
By understanding the fundamental properties of LLMs and how they relate to the flow of time, the researchers hope to provide insights that can inform the development and application of these powerful AI systems, particularly in areas where the directionality of time is a crucial factor.
Technical Explanation
The paper begins by introducing the concept of autoregressive LLMs, which are a type of language model that generates text one word at a time, using the previous words as a guide. This forward-in-time perspective is central to the way these models operate and underlies their remarkable ability to produce coherent and fluent text.
The authors then explore the "arrow of time" and how it relates to the behavior and capabilities of LLMs. They note that the directionality of time is a fundamental feature of the physical world, and they hypothesize that this temporal asymmetry is reflected in the way LLMs process and generate language.
To investigate this, the researchers conduct a series of experiments that examine the performance of LLMs on various tasks, such as time series forecasting and zero-shot learning. They find that the arrow of time plays a significant role in shaping the models' abilities, with forward-in-time tasks generally being easier for the LLMs to handle than backward-in-time tasks.
The authors attribute this to the inherent temporal bias of the language data used to train the models, as well as the models' reliance on the contextual information provided by the preceding words. They also explore the implications of these findings for the scaling laws that govern the performance of large-scale AI systems, suggesting that the arrow of time may be a crucial factor in these scaling relationships.
Critical Analysis
The paper provides a thought-provoking exploration of the role of the arrow of time in the behavior and capabilities of large language models. The authors present a compelling case for the importance of this temporal asymmetry and its influence on tasks like time series forecasting and zero-shot learning.
One potential limitation of the study is the reliance on a limited set of tasks and datasets to investigate the arrow of time effects. While the authors demonstrate clear patterns in their experiments, it would be valuable to see these findings replicated and expanded upon in a broader range of settings.
Additionally, the paper does not delve deeply into the potential societal implications of these findings. As LLMs continue to grow in popularity and influence, understanding their fundamental biases and limitations is crucial. The authors could have explored how the arrow of time bias might affect the use of these models in areas like decision-making, content generation, and personal assistance.
Despite these minor caveats, the paper offers a valuable contribution to the growing body of research on the inner workings of large language models. By shedding light on the role of the arrow of time, the authors provide insights that can inform the development and application of these powerful AI systems, ultimately helping to ensure they are used in an ethical and responsible manner.
Conclusion
This paper presents a compelling exploration of the role of the arrow of time in the behavior and capabilities of large language models. By investigating how the directionality of time affects the performance of LLMs on tasks like time series forecasting and zero-shot learning, the authors uncover fundamental insights into the temporal biases and limitations of these powerful AI systems.
The findings have important implications for the development and application of large language models, as they suggest that the arrow of time is a crucial factor in shaping the models' abilities and the scaling laws that govern their performance. As LLMs continue to grow in importance and influence, understanding these underlying biases will be essential for ensuring they are used in a responsible and ethical manner.
Overall, this paper offers a valuable contribution to the ongoing research on the inner workings of large language models, providing a thought-provoking perspective on the role of time in these complex AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, Mingsheng Long
0
0
Foundation models of time series have not been fully developed due to the limited availability of time series corpora and the underexploration of scalable pre-training. Based on the similar sequential formulation of time series and natural language, increasing research demonstrates the feasibility of leveraging large language models (LLM) for time series. Nevertheless, the inherent autoregressive property and decoder-only architecture of LLMs have not been fully considered, resulting in insufficient utilization of LLM abilities. To further exploit the general-purpose token transition and multi-step generation ability of large language models, we propose AutoTimes to repurpose LLMs as autoregressive time series forecasters, which independently projects time series segments into the embedding space and autoregressively generates future predictions with arbitrary lengths. Compatible with any decoder-only LLMs, the consequent forecaster exhibits the flexibility of the lookback length and scalability of the LLM size. Further, we formulate time series as prompts, extending the context for prediction beyond the lookback window, termed in-context forecasting. By adopting textual timestamps as position embeddings, AutoTimes integrates multimodality for multivariate scenarios. Empirically, AutoTimes achieves state-of-the-art with 0.1% trainable parameters and over 5 times training/inference speedup compared to advanced LLM-based forecasters.
5/24/2024
Position: What Can Large Language Models Tell Us about Time Series Analysis
Ming Jin, Yifan Zhang, Wei Chen, Kexin Zhang, Yuxuan Liang, Bin Yang, Jindong Wang, Shirui Pan, Qingsong Wen
0
0
Time series analysis is essential for comprehending the complexities inherent in various realworld systems and applications. Although large language models (LLMs) have recently made significant strides, the development of artificial general intelligence (AGI) equipped with time series analysis capabilities remains in its nascent phase. Most existing time series models heavily rely on domain knowledge and extensive model tuning, predominantly focusing on prediction tasks. In this paper, we argue that current LLMs have the potential to revolutionize time series analysis, thereby promoting efficient decision-making and advancing towards a more universal form of time series analytical intelligence. Such advancement could unlock a wide range of possibilities, including time series modality switching and question answering. We encourage researchers and practitioners to recognize the potential of LLMs in advancing time series analysis and emphasize the need for trust in these related efforts. Furthermore, we detail the seamless integration of time series analysis with existing LLM technologies and outline promising avenues for future research.
6/4/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
👨🏫
Scaling-laws for Large Time-series Models
Thomas D. P. Edwards, James Alvey, Justin Alsing, Nam H. Nguyen, Benjamin D. Wandelt
0
0
Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
5/24/2024