Scaling-laws for Large Time-series Models
2405.13867
0
0
👨🏫
Abstract
Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
Create account to get full access
Overview
- This paper explores the scaling behavior of large transformer-based models for time series forecasting, similar to the scaling laws observed in large language models (LLMs).
- The researchers assembled a large and diverse dataset of time series data to train their models, and found that these foundational time series transformer models exhibit power-law scaling with respect to parameters, dataset size, and training compute.
- This suggests that the same principles governing the scaling of LLMs may apply to transformer-based models for time series tasks, opening up new possibilities for rapid performance improvements as model and dataset sizes increase.
Plain English Explanation
The paper looks at how the size and complexity of transformer-based models used for time series forecasting relate to their performance. Similar to what researchers have found with large language models (LLMs), the authors show that as you increase the number of parameters in the model, the size of the training dataset, and the amount of computing power used to train the model, the performance of the time series forecasting model also improves in a predictable way.
This is important because it suggests that the same principles that have allowed LLMs to become increasingly capable as they've scaled up in size can also be applied to transformer-based models for other sequential data tasks like time series forecasting. By understanding these scaling laws, researchers and engineers can more effectively design and train models for time series applications, potentially leading to rapid performance gains as model and dataset sizes continue to grow.
Technical Explanation
The researchers in this paper trained large transformer-based models on a diverse corpus of time series data, spanning over five orders of magnitude in terms of the number of parameters, dataset size, and training compute. They found that these foundational time series transformer models exhibit power-law scaling behavior, similar to what has been observed with LLMs.
Specifically, the team found that model performance (as measured by various forecasting metrics) scaled predictably with the number of model parameters, the size of the training dataset, and the amount of compute used for training. This held true even as they varied architectural details like the aspect ratio and number of attention heads, which had relatively minimal impact on the scaling trends.
By assembling this large and heterogeneous time series dataset, the researchers were able to establish these scaling law relationships for time series transformers for the first time. This suggests that the same principles governing the scaling of language models may extend to other sequential data domains, opening up new avenues for rapid performance improvements as model and dataset sizes continue to grow.
Critical Analysis
The researchers acknowledge several limitations and caveats to their work. First, while the time series dataset they compiled is large and diverse, it may not fully capture the breadth of real-world time series applications. Further research is needed to validate whether the observed scaling laws hold for other time series datasets and tasks.
Additionally, the paper focuses solely on decoder-only transformer architectures, leaving open the question of whether encoder-decoder transformer models, which are commonly used for sequence-to-sequence tasks, would exhibit similar scaling behavior. Exploring the scaling properties of other transformer variants could provide a more comprehensive understanding of the principles underlying these models.
The researchers also note that their analysis is limited to forecasting metrics, and do not examine how scaling impacts other relevant time series characteristics, such as uncertainty quantification or anomaly detection. Expanding the performance evaluation criteria could yield additional insights into the scaling properties of time series transformers.
Despite these limitations, this work represents an important step towards unraveling the mysteries of scaling laws in the context of time series modeling. By establishing these foundational scaling relationships, the researchers have laid the groundwork for future investigations into the broader applicability and implications of these principles.
Conclusion
This paper demonstrates that transformer-based models for time series forecasting exhibit analogous scaling behavior to large language models, with predictable performance improvements as model size, dataset size, and training compute increase. These findings suggest that the principles governing the scaling of LLMs may extend to other sequential data domains, opening up new opportunities for rapid advancements in time series applications as model and dataset sizes continue to grow.
The researchers' assembly of a large, diverse time series dataset and their rigorous analysis of the scaling properties of these transformer models represent an important contribution to the field. While further research is needed to validate the broader applicability of these scaling laws, this work lays the foundation for developing more effective and efficient transformer-based solutions for a wide range of time series forecasting and analysis tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Scaling Law for Time Series Forecasting
Jingzhe Shi, Qinwei Ma, Huan Ma, Lei Li
0
0
Scaling law that rewards large datasets, complex models and enhanced data granularity has been observed in various fields of deep learning. Yet, studies on time series forecasting have cast doubt on scaling behaviors of deep learning methods for time series forecasting: while more training data improves performance, more capable models do not always outperform less capable models, and longer input horizons may hurt performance for some models. We propose a theory for scaling law for time series forecasting that can explain these seemingly abnormal behaviors. We take into account the impact of dataset size and model complexity, as well as time series data granularity, particularly focusing on the look-back horizon, an aspect that has been unexplored in previous theories. Furthermore, we empirically evaluate various models using a diverse set of time series forecasting datasets, which (1) verifies the validity of scaling law on dataset size and model complexity within the realm of time series forecasting, and (2) validates our theoretical framework, particularly regarding the influence of look back horizon. We hope our findings may inspire new models targeting time series forecasting datasets of limited size, as well as large foundational datasets and models for time series forecasting in future works.footnote{Codes for our experiments will be made public at: url{https://github.com/JingzheShi/ScalingLawForTimeSeriesForecasting}.
5/28/2024
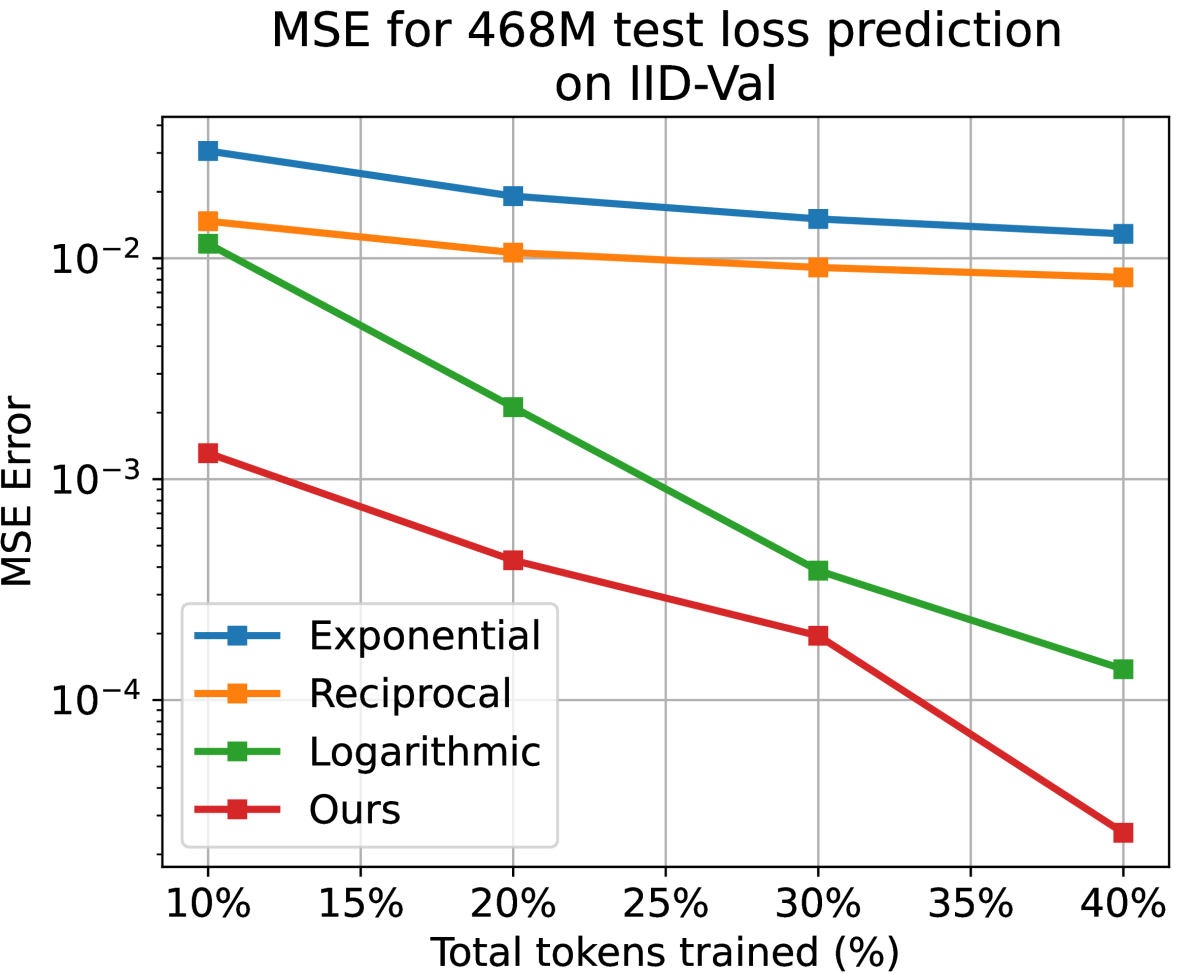
Temporal Scaling Law for Large Language Models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Jianwei Niu, Guiguang Ding
0
0
Recently, Large Language Models (LLMs) have been widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed Scaling Laws, have discovered that the final test loss of LLMs scales as power-laws with model size, computational budget, and dataset size. However, the temporal change of the test loss of an LLM throughout its pre-training process remains unexplored, though it is valuable in many aspects, such as selecting better hyperparameters textit{directly} on the target LLM. In this paper, we propose the novel concept of Temporal Scaling Law, studying how the test loss of an LLM evolves as the training steps scale up. In contrast to modeling the test loss as a whole in a coarse-grained manner, we break it down and dive into the fine-grained test loss of each token position, and further develop a dynamic hyperbolic-law. Afterwards, we derive the much more precise temporal scaling law by studying the temporal patterns of the parameters in the dynamic hyperbolic-law. Results on both in-distribution (ID) and out-of-distribution (OOD) validation datasets demonstrate that our temporal scaling law accurately predicts the test loss of LLMs across training steps. Our temporal scaling law has broad practical applications. First, it enables direct and efficient hyperparameter selection on the target LLM, such as data mixture proportions. Secondly, viewing the LLM pre-training dynamics from the token position granularity provides some insights to enhance the understanding of LLM pre-training.
6/18/2024
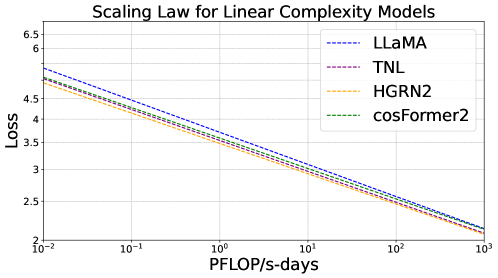
New!Scaling Laws for Linear Complexity Language Models
Xuyang Shen, Dong Li, Ruitao Leng, Zhen Qin, Weigao Sun, Yiran Zhong
0
0
The interest in linear complexity models for large language models is on the rise, although their scaling capacity remains uncertain. In this study, we present the scaling laws for linear complexity language models to establish a foundation for their scalability. Specifically, we examine the scaling behaviors of three efficient linear architectures. These include TNL, a linear attention model with data-independent decay; HGRN2, a linear RNN with data-dependent decay; and cosFormer2, a linear attention model without decay. We also include LLaMA as a baseline architecture for softmax attention for comparison. These models were trained with six variants, ranging from 70M to 7B parameters on a 300B-token corpus, and evaluated with a total of 1,376 intermediate checkpoints on various downstream tasks. These tasks include validation loss, commonsense reasoning, and information retrieval and generation. The study reveals that existing linear complexity language models exhibit similar scaling capabilities as conventional transformer-based models while also demonstrating superior linguistic proficiency and knowledge retention.
6/26/2024
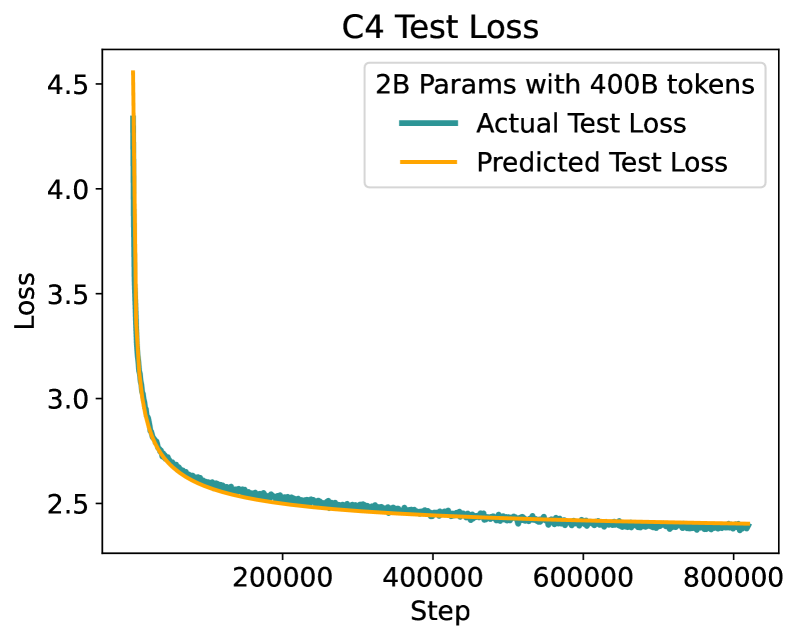
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
0
0
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
4/8/2024