Assessing In-context Learning and Fine-tuning for Topic Classification of German Web Data

0

Sign in to get full access
Overview
- Evaluates in-context learning and fine-tuning for topic classification of German web data
- Compares performance of language models with and without fine-tuning on a German text classification task
- Investigates the impact of prompting and prompt engineering for in-context learning
Plain English Explanation
This research paper examines different approaches for classifying the topics of German web content using machine learning models. The researchers compared the performance of language models that were either fine-tuned on a specific dataset or used in-context learning (where the model learns from the input prompt itself, without additional training).
The key finding was that in-context learning can be just as effective as fine-tuning for this task, and may require less effort. In-context learning involves crafting prompts that guide the language model to understand and classify the input text, without needing to undergo extensive retraining on a large dataset.
The researchers explored different prompt engineering techniques to optimize the in-context learning performance. They found that careful prompt design can enable language models to perform topic classification with accuracy comparable to fine-tuned models, without the need for additional training.
This research is significant because it suggests that in-context learning may be a viable alternative to resource-intensive fine-tuning for certain text classification tasks, at least in the domain of German web content. The findings could help streamline the deployment of language models for real-world applications that require topic categorization.
Technical Explanation
The paper evaluates the performance of large language models (LLMs) on a German text classification task, comparing in-context learning and fine-tuning approaches. The researchers used a dataset of German web pages labeled with topic categories, and experimented with prompting techniques to guide the LLMs in classifying the content.
For the fine-tuning approach, the researchers trained LLMs on the labeled dataset using supervised learning. They then evaluated the fine-tuned models on held-out test data.
In the in-context learning experiments, the researchers crafted prompts that provided the LLMs with context about the classification task and input text. This allowed the models to learn from the prompt itself, without needing to undergo extensive retraining.
The results showed that in-context learning can achieve classification performance on par with fine-tuning, and may require less computational resources and effort. The researchers also found that prompt engineering, such as incorporating topic descriptions and providing clear task instructions, can significantly improve the in-context learning capability of the LLMs.
Critical Analysis
The paper provides a thorough and well-designed evaluation of in-context learning and fine-tuning for topic classification of German web data. However, there are a few potential limitations and areas for further research:
-
Dataset and Domain: The study is focused on German web content, so the findings may not generalize to other languages or domains. Further research is needed to investigate the transferability of these techniques to different datasets and use cases.
-
Prompt Engineering: While the paper demonstrates the importance of prompt engineering, the process of crafting effective prompts is still largely manual and can be time-consuming. Automated or semi-automated prompt generation methods could be an area for future exploration.
-
Model Generalization: The paper does not examine how well the fine-tuned and in-context learned models generalize to new, unseen data. This is an important consideration for real-world deployment, and should be investigated in future studies.
-
Computational Efficiency: While in-context learning may be more efficient than fine-tuning, the paper does not provide a detailed comparison of the computational resources required for each approach. This information would be valuable for practical application of these techniques.
Overall, the paper presents a valuable contribution to the understanding of in-context learning and its potential for text classification tasks. The findings could have important implications for the deployment of language models in real-world applications that require efficient and effective topic categorization.
Conclusion
This research paper investigates the use of in-context learning and fine-tuning for topic classification of German web data, comparing the performance of these two approaches. The key finding is that in-context learning can be just as effective as fine-tuning, while potentially requiring fewer computational resources and less effort.
The researchers demonstrate the importance of prompt engineering in enabling language models to effectively learn from the input context, without the need for extensive retraining. This suggests that in-context learning may be a viable alternative to fine-tuning for certain text classification tasks, potentially streamlining the deployment of language models in real-world applications.
Further research is needed to explore the generalization capabilities of these techniques, as well as their transferability to other languages and domains. Nonetheless, this study provides valuable insights into the potential of in-context learning for efficient and effective topic categorization of text data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Assessing In-context Learning and Fine-tuning for Topic Classification of German Web Data
Julian Schelb, Roberto Ulloa, Andreas Spitz
Researchers in the political and social sciences often rely on classification models to analyze trends in information consumption by examining browsing histories of millions of webpages. Automated scalable methods are necessary due to the impracticality of manual labeling. In this paper, we model the detection of topic-related content as a binary classification task and compare the accuracy of fine-tuned pre-trained encoder models against in-context learning strategies. Using only a few hundred annotated data points per topic, we detect content related to three German policies in a database of scraped webpages. We compare multilingual and monolingual models, as well as zero and few-shot approaches, and investigate the impact of negative sampling strategies and the combination of URL & content-based features. Our results show that a small sample of annotated data is sufficient to train an effective classifier. Fine-tuning encoder-based models yields better results than in-context learning. Classifiers using both URL & content-based features perform best, while using URLs alone provides adequate results when content is unavailable.
Read more7/24/2024
0
Language Models for Text Classification: Is In-Context Learning Enough?
Aleksandra Edwards, Jose Camacho-Collados
Recent foundational language models have shown state-of-the-art performance in many NLP tasks in zero- and few-shot settings. An advantage of these models over more standard approaches based on fine-tuning is the ability to understand instructions written in natural language (prompts), which helps them generalise better to different tasks and domains without the need for specific training data. This makes them suitable for addressing text classification problems for domains with limited amounts of annotated instances. However, existing research is limited in scale and lacks understanding of how text generation models combined with prompting techniques compare to more established methods for text classification such as fine-tuning masked language models. In this paper, we address this research gap by performing a large-scale evaluation study for 16 text classification datasets covering binary, multiclass, and multilabel problems. In particular, we compare zero- and few-shot approaches of large language models to fine-tuning smaller language models. We also analyse the results by prompt, classification type, domain, and number of labels. In general, the results show how fine-tuning smaller and more efficient language models can still outperform few-shot approaches of larger language models, which have room for improvement when it comes to text classification.
Read more4/16/2024
0
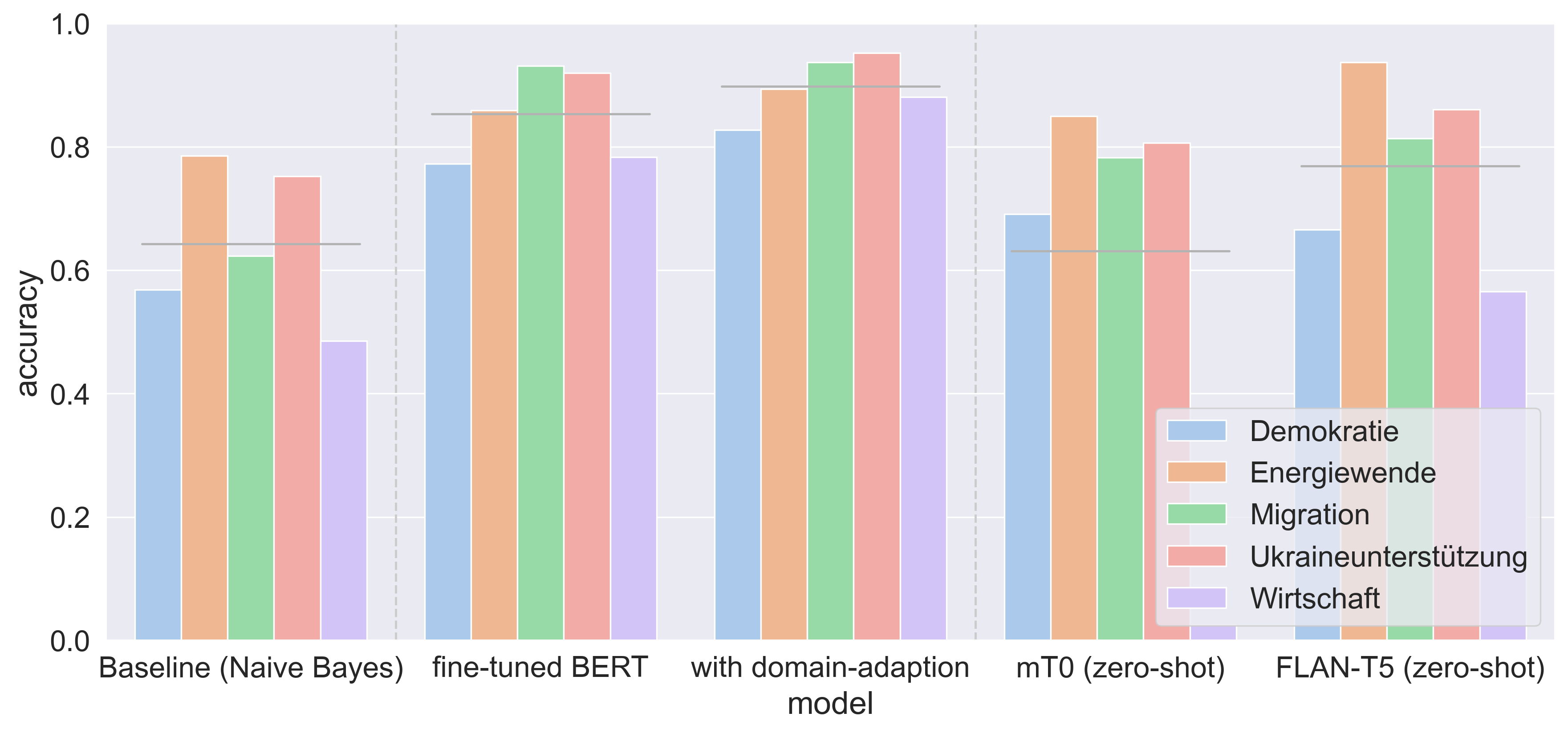
Zero-shot prompt-based classification: topic labeling in times of foundation models in German Tweets
Simon Munker, Kai Kugler, Achim Rettinger
Filtering and annotating textual data are routine tasks in many areas, like social media or news analytics. Automating these tasks allows to scale the analyses wrt. speed and breadth of content covered and decreases the manual effort required. Due to technical advancements in Natural Language Processing, specifically the success of large foundation models, a new tool for automating such annotation processes by using a text-to-text interface given written guidelines without providing training samples has become available. In this work, we assess these advancements in-the-wild by empirically testing them in an annotation task on German Twitter data about social and political European crises. We compare the prompt-based results with our human annotation and preceding classification approaches, including Naive Bayes and a BERT-based fine-tuning/domain adaptation pipeline. Our results show that the prompt-based approach - despite being limited by local computation resources during the model selection - is comparable with the fine-tuned BERT but without any annotated training data. Our findings emphasize the ongoing paradigm shift in the NLP landscape, i.e., the unification of downstream tasks and elimination of the need for pre-labeled training data.
Read more6/27/2024

0
AboutMe: Using Self-Descriptions in Webpages to Document the Effects of English Pretraining Data Filters
Li Lucy, Suchin Gururangan, Luca Soldaini, Emma Strubell, David Bamman, Lauren F. Klein, Jesse Dodge
Large language models' (LLMs) abilities are drawn from their pretraining data, and model development begins with data curation. However, decisions around what data is retained or removed during this initial stage are under-scrutinized. In our work, we ground web text, which is a popular pretraining data source, to its social and geographic contexts. We create a new dataset of 10.3 million self-descriptions of website creators, and extract information about who they are and where they are from: their topical interests, social roles, and geographic affiliations. Then, we conduct the first study investigating how ten quality and English language identification (langID) filters affect webpages that vary along these social dimensions. Our experiments illuminate a range of implicit preferences in data curation: we show that some quality classifiers act like topical domain filters, and langID can overlook English content from some regions of the world. Overall, we hope that our work will encourage a new line of research on pretraining data curation practices and its social implications.
Read more6/24/2024