Evaluating the Adversarial Robustness of Retrieval-Based In-Context Learning for Large Language Models
2405.15984
0
0

Abstract
With the emergence of large language models, such as LLaMA and OpenAI GPT-3, In-Context Learning (ICL) gained significant attention due to its effectiveness and efficiency. However, ICL is very sensitive to the choice, order, and verbaliser used to encode the demonstrations in the prompt. Retrieval-Augmented ICL methods try to address this problem by leveraging retrievers to extract semantically related examples as demonstrations. While this approach yields more accurate results, its robustness against various types of adversarial attacks, including perturbations on test samples, demonstrations, and retrieved data, remains under-explored. Our study reveals that retrieval-augmented models can enhance robustness against test sample attacks, outperforming vanilla ICL with a 4.87% reduction in Attack Success Rate (ASR); however, they exhibit overconfidence in the demonstrations, leading to a 2% increase in ASR for demonstration attacks. Adversarial training can help improve the robustness of ICL methods to adversarial attacks; however, such a training scheme can be too costly in the context of LLMs. As an alternative, we introduce an effective training-free adversarial defence method, DARD, which enriches the example pool with those attacked samples. We show that DARD yields improvements in performance and robustness, achieving a 15% reduction in ASR over the baselines. Code and data are released to encourage further research: https://github.com/simonucl/adv-retreival-icl
Create account to get full access
Overview
- This paper evaluates the adversarial robustness of retrieval-based in-context learning for large language models.
- In-context learning allows language models to quickly adapt to new tasks by using a small number of examples provided in the input.
- Retrieval-based in-context learning uses a retrieve-then-generate approach, where the model first retrieves relevant examples from a database and then generates the output based on those examples.
- The researchers investigate how this approach performs under adversarial attacks, where the input is intentionally modified to mislead the model.
Plain English Explanation
Large language models have become incredibly powerful at tasks like question answering, text generation, and even programming. These models can be "fine-tuned" on specific datasets to perform well on particular tasks. However, this fine-tuning process can be time-consuming and resource-intensive.
An alternative approach is in-context learning, where the language model can adapt to a new task using just a few examples provided in the input. One way to do this is through a "retrieve-then-generate" method, where the model first retrieves relevant examples from a database and then generates the output based on those examples.
This paper looks at how well this retrieval-based in-context learning approach holds up against adversarial attacks - cases where the input is intentionally modified to try to confuse or mislead the model. The researchers investigate different attack strategies and evaluate the robustness of the retrieval-based approach compared to standard fine-tuning.
Technical Explanation
The paper first provides an overview of prior work on in-context learning and making language models more robust to adversarial attacks.
The core of the paper then presents the researchers' experiments evaluating the adversarial robustness of retrieval-based in-context learning. They use a retrieve-then-generate approach where the model first retrieves relevant examples from a database and then generates the output based on those examples.
The researchers test this approach against various adversarial attack strategies, such as inserting distracting text, paraphrasing the input, and using synonyms. They compare the performance of the retrieval-based in-context learning to standard fine-tuning, and also investigate the impact of using task-specific hints to improve robustness.
The results show that the retrieval-based in-context learning approach is generally more robust to adversarial attacks than standard fine-tuning. However, the researchers also identify some weaknesses and discuss strategies for making retrieval-augmented language models more robust in the face of such attacks.
Critical Analysis
The paper provides a thorough and rigorous evaluation of the adversarial robustness of retrieval-based in-context learning. The researchers carefully designed their experiments to test a range of attack strategies and compare the performance to standard fine-tuning.
One potential limitation is that the experiments were conducted on a relatively small set of tasks and datasets. It would be valuable to see how the findings generalize to a wider range of applications and real-world scenarios.
Additionally, the paper does not delve deeply into the underlying reasons why the retrieval-based approach tends to be more robust. Further analysis of the model's behavior and the specific failure modes under adversarial attacks could provide additional insights.
Overall, this paper makes a valuable contribution to the understanding of in-context learning and its robustness to adversarial attacks. The findings suggest that retrieval-based approaches may be a promising direction for building more secure and reliable language models.
Conclusion
This paper evaluates the adversarial robustness of retrieval-based in-context learning for large language models. In-context learning allows language models to quickly adapt to new tasks using just a few examples, and the retrieve-then-generate approach leverages a database of relevant examples.
The researchers found that this retrieval-based in-context learning approach is generally more robust to adversarial attacks than standard fine-tuning. However, they also identified some weaknesses and discussed strategies for improving the robustness of retrieval-augmented language models.
The findings from this work contribute to the ongoing efforts to make language models more secure and reliable, which is crucial as these models become increasingly prevalent in real-world applications. Further research on the underlying mechanisms and generalization to a wider range of tasks could provide additional insights and guide the development of more robust language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Hijacking Large Language Models via Adversarial In-Context Learning
Yao Qiang, Xiangyu Zhou, Dongxiao Zhu
0
0
In-context learning (ICL) has emerged as a powerful paradigm leveraging LLMs for specific downstream tasks by utilizing labeled examples as demonstrations (demos) in the precondition prompts. Despite its promising performance, ICL suffers from instability with the choice and arrangement of examples. Additionally, crafted adversarial attacks pose a notable threat to the robustness of ICL. However, existing attacks are either easy to detect, rely on external models, or lack specificity towards ICL. This work introduces a novel transferable attack against ICL to address these issues, aiming to hijack LLMs to generate the target response or jailbreak. Our hijacking attack leverages a gradient-based prompt search method to learn and append imperceptible adversarial suffixes to the in-context demos without directly contaminating the user queries. Comprehensive experimental results across different generation and jailbreaking tasks highlight the effectiveness of our hijacking attack, resulting in distracted attention towards adversarial tokens and consequently leading to unwanted target outputs. We also propose a defense strategy against hijacking attacks through the use of extra clean demos, which enhances the robustness of LLMs during ICL. Broadly, this work reveals the significant security vulnerabilities of LLMs and emphasizes the necessity for in-depth studies on their robustness.
6/18/2024
📶
RetICL: Sequential Retrieval of In-Context Examples with Reinforcement Learning
Alexander Scarlatos, Andrew Lan
0
0
Recent developments in large pre-trained language models have enabled unprecedented performance on a variety of downstream tasks. Achieving best performance with these models often leverages in-context learning, where a model performs a (possibly new) task given one or more examples. However, recent work has shown that the choice of examples can have a large impact on task performance and that finding an optimal set of examples is non-trivial. While there are many existing methods for selecting in-context examples, they generally score examples independently, ignoring the dependency between them and the order in which they are provided to the model. In this work, we propose Retrieval for In-Context Learning (RetICL), a learnable method for modeling and optimally selecting examples sequentially for in-context learning. We frame the problem of sequential example selection as a Markov decision process and train an example retriever using reinforcement learning. We evaluate RetICL on math word problem solving and scientific question answering tasks and show that it consistently outperforms or matches heuristic and learnable baselines. We also use case studies to show that RetICL implicitly learns representations of problem solving strategies.
4/17/2024
🌿
Using Natural Language Explanations to Improve Robustness of In-context Learning
Xuanli He, Yuxiang Wu, Oana-Maria Camburu, Pasquale Minervini, Pontus Stenetorp
0
0
Recent studies demonstrated that large language models (LLMs) can excel in many tasks via in-context learning (ICL). However, recent works show that ICL-prompted models tend to produce inaccurate results when presented with adversarial inputs. In this work, we investigate whether augmenting ICL with natural language explanations (NLEs) improves the robustness of LLMs on adversarial datasets covering natural language inference and paraphrasing identification. We prompt LLMs with a small set of human-generated NLEs to produce further NLEs, yielding more accurate results than both a zero-shot-ICL setting and using only human-generated NLEs. Our results on five popular LLMs (GPT3.5-turbo, Llama2, Vicuna, Zephyr, and Mistral) show that our approach yields over 6% improvement over baseline approaches for eight adversarial datasets: HANS, ISCS, NaN, ST, PICD, PISP, ANLI, and PAWS. Furthermore, previous studies have demonstrated that prompt selection strategies significantly enhance ICL on in-distribution test sets. However, our findings reveal that these strategies do not match the efficacy of our approach for robustness evaluations, resulting in an accuracy drop of 8% compared to the proposed approach.
5/21/2024
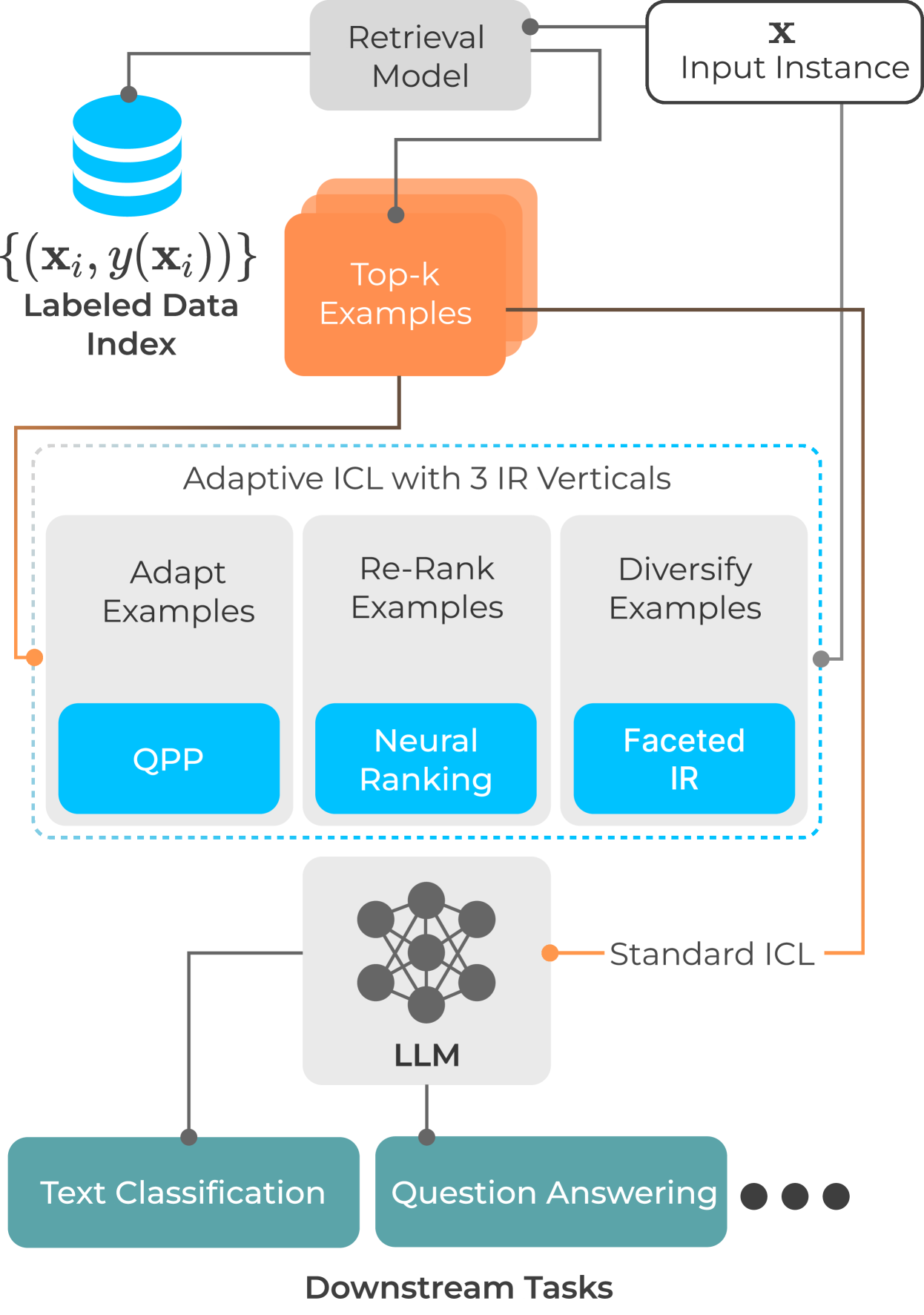
In-Context Learning or: How I learned to stop worrying and love Applied Information Retrieval
Andrew Parry, Debasis Ganguly, Manish Chandra
0
0
With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
5/3/2024