Assessing LLMs Suitability for Knowledge Graph Completion
2405.17249
0
0

Abstract
Recent work shown the capability of Large Language Models (LLMs) to solve tasks related to Knowledge Graphs, such as Knowledge Graph Completion, even in Zero- or Few-Shot paradigms. However, they are known to hallucinate answers, or output results in a non-deterministic manner, thus leading to wrongly reasoned responses, even if they satisfy the user's demands. To highlight opportunities and challenges in knowledge graphs-related tasks, we experiment with two distinguished LLMs, namely Mixtral-8x7B-Instruct-v0.1, and gpt-3.5-turbo-0125, on Knowledge Graph Completion for static knowledge graphs, using prompts constructed following the TELeR taxonomy, in Zero- and One-Shot contexts, on a Task-Oriented Dialogue system use case. When evaluated using both strict and flexible metrics measurement manners, our results show that LLMs could be fit for such a task if prompts encapsulate sufficient information and relevant examples.
Create account to get full access
Overview
- This paper explores the suitability of large language models (LLMs) for knowledge graph completion, a task that involves inferring missing information in a knowledge graph.
- The researchers investigate the effectiveness of different prompting strategies and evaluate the performance of LLMs on this task compared to traditional knowledge graph completion methods.
- The findings provide insights into the capabilities and limitations of LLMs for this type of structured reasoning task, which has implications for the use of LLMs in knowledge-intensive applications.
Plain English Explanation
Knowledge graphs are digital representations of real-world entities and the relationships between them. They are used to store and organize information in a structured way, similar to a database. However, knowledge graphs are often incomplete, with missing information that needs to be inferred or "filled in."
The researchers in this paper wanted to see how well large language models (LLMs) - powerful AI systems trained on vast amounts of text data - could be used to complete these missing pieces of information in knowledge graphs. They experimented with different ways of prompting the LLMs, which involves providing them with specific instructions or context to guide their reasoning.
The results showed that LLMs can be effective at this knowledge graph completion task, but their performance depends on the prompting strategy used. Some prompting approaches worked better than others, and the LLMs still struggled with certain types of reasoning compared to traditional knowledge graph completion methods.
These findings are important because they help us understand the capabilities and limitations of LLMs when it comes to working with structured data like knowledge graphs. This has implications for how LLMs could be used in real-world applications that rely on knowledge-intensive reasoning, such as task-oriented dialogue systems or systems that construct knowledge graphs from text.
Technical Explanation
The paper first reviews related work on using LLMs for knowledge-intensive tasks, including prior research on LLMs and structured reasoning and prompting techniques for using LLMs with knowledge graphs.
The core of the paper involves an empirical evaluation of different prompting strategies for using LLMs to complete missing information in a knowledge graph. The researchers experimented with prompts that provided the LLMs with varying levels of context about the knowledge graph structure and task requirements.
To assess performance, they compared the LLM-based approaches to traditional knowledge graph completion methods. The key metrics included completion accuracy, as well as measures of the quality and diversity of the inferred information.
The results showed that the effectiveness of the LLMs depended heavily on the prompting strategy used. Some prompts that gave the LLMs more detailed instructions and structure led to better performance, while more open-ended prompts resulted in lower accuracy. However, the LLMs also demonstrated the ability to generate novel and diverse completion candidates that traditional methods struggled with.
Critical Analysis
The paper provides a thorough and rigorous evaluation of LLM capabilities for knowledge graph completion. The authors acknowledge several limitations, such as the reliance on a single knowledge graph dataset and the fact that the prompting strategies were hand-crafted rather than automatically optimized.
Additionally, the paper does not delve deeply into the underlying reasons why certain prompting strategies were more effective than others. Further research could explore the cognitive and architectural factors that influence LLM reasoning on these types of structured tasks.
It would also be interesting to see how the LLM performance compares to human experts in knowledge graph completion, and whether the models can capture the nuance and context-sensitivity that humans bring to this type of reasoning.
Overall, this paper makes a valuable contribution by shedding light on the strengths and weaknesses of LLMs for knowledge-intensive applications. The findings can inform the development of more effective prompting techniques and help guide the integration of LLMs into knowledge-centric systems.
Conclusion
This paper presents an in-depth exploration of using large language models (LLMs) for the task of knowledge graph completion. The researchers found that LLMs can be effective at this structured reasoning task, but their performance is highly dependent on the prompting strategy used.
The results provide important insights into the capabilities and limitations of LLMs when it comes to working with knowledge-intensive data and applications. This has implications for the development of task-oriented dialogue systems, knowledge graph construction methods, and other knowledge-centric AI systems that could benefit from the powerful language understanding abilities of LLMs.
Further research is still needed to fully unlock the potential of LLMs for these types of knowledge-intensive tasks, but this paper represents an important step forward in our understanding of their suitability and the factors that influence their performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
New!Enhancing Text-based Knowledge Graph Completion with Zero-Shot Large Language Models: A Focus on Semantic Enhancement
Rui Yang, Jiahao Zhu, Jianping Man, Li Fang, Yi Zhou
0
0
The design and development of text-based knowledge graph completion (KGC) methods leveraging textual entity descriptions are at the forefront of research. These methods involve advanced optimization techniques such as soft prompts and contrastive learning to enhance KGC models. The effectiveness of text-based methods largely hinges on the quality and richness of the training data. Large language models (LLMs) can utilize straightforward prompts to alter text data, thereby enabling data augmentation for KGC. Nevertheless, LLMs typically demand substantial computational resources. To address these issues, we introduce a framework termed constrained prompts for KGC (CP-KGC). This CP-KGC framework designs prompts that adapt to different datasets to enhance semantic richness. Additionally, CP-KGC employs a context constraint strategy to effectively identify polysemous entities within KGC datasets. Through extensive experimentation, we have verified the effectiveness of this framework. Even after quantization, the LLM (Qwen-7B-Chat-int4) still enhances the performance of text-based KGC methods footnote{Code and datasets are available at href{https://github.com/sjlmg/CP-KGC}{https://github.com/sjlmg/CP-KGC}}. This study extends the performance limits of existing models and promotes further integration of KGC with LLMs.
6/28/2024
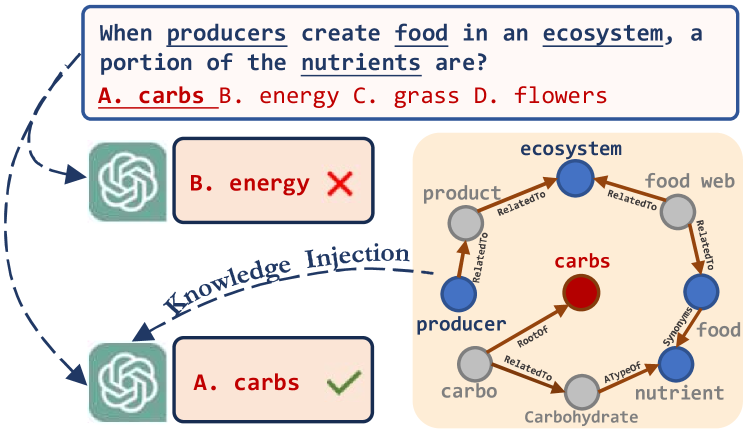
KnowGPT: Knowledge Graph based Prompting for Large Language Models
Qinggang Zhang, Junnan Dong, Hao Chen, Daochen Zha, Zailiang Yu, Xiao Huang
0
0
Large Language Models (LLMs) have demonstrated remarkable capabilities in many real-world applications. Nonetheless, LLMs are often criticized for their tendency to produce hallucinations, wherein the models fabricate incorrect statements on tasks beyond their knowledge and perception. To alleviate this issue, researchers have explored leveraging the factual knowledge in knowledge graphs (KGs) to ground the LLM's responses in established facts and principles. However, most state-of-the-art LLMs are closed-source, making it challenging to develop a prompting framework that can efficiently and effectively integrate KGs into LLMs with hard prompts only. Generally, existing KG-enhanced LLMs usually suffer from three critical issues, including huge search space, high API costs, and laborious prompt engineering, that impede their widespread application in practice. To this end, we introduce a novel Knowledge Graph based PrompTing framework, namely KnowGPT, to enhance LLMs with domain knowledge. KnowGPT contains a knowledge extraction module to extract the most informative knowledge from KGs, and a context-aware prompt construction module to automatically convert extracted knowledge into effective prompts. Experiments on three benchmarks demonstrate that KnowGPT significantly outperforms all competitors. Notably, KnowGPT achieves a 92.6% accuracy on OpenbookQA leaderboard, comparable to human-level performance.
6/5/2024
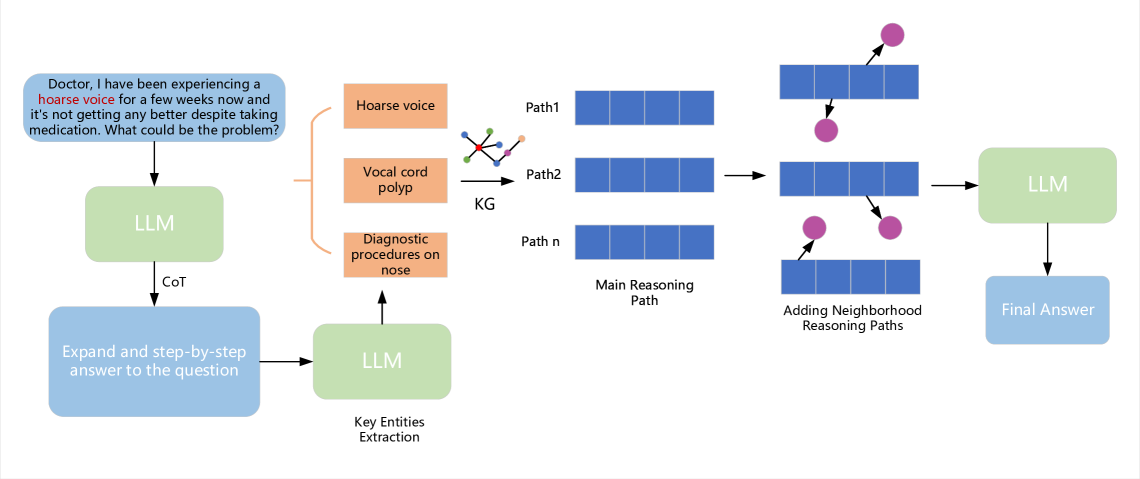
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
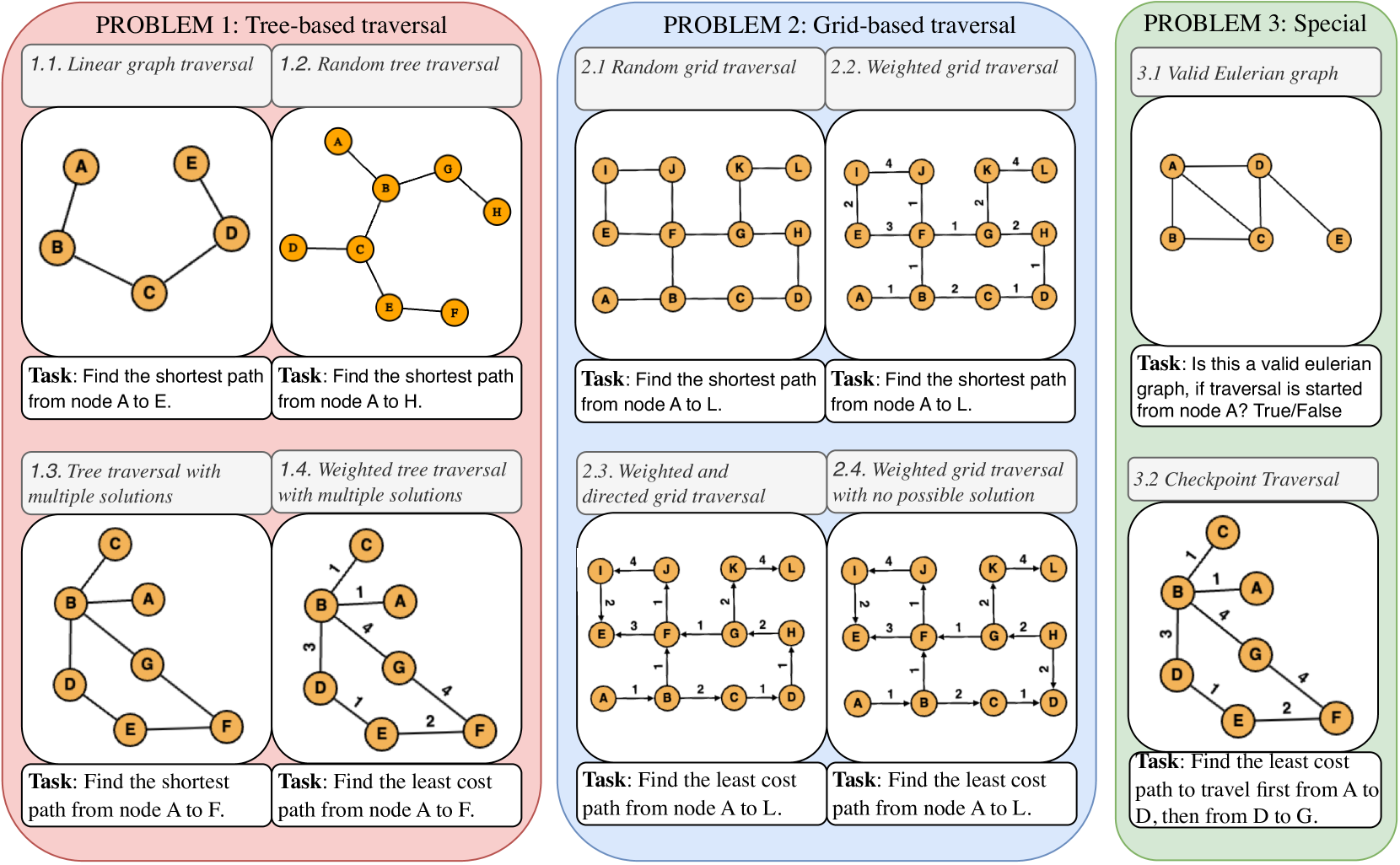
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
0
0
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
4/19/2024