Asteroid: Resource-Efficient Hybrid Pipeline Parallelism for Collaborative DNN Training on Heterogeneous Edge Devices

0

Sign in to get full access
Overview
- Asteroid is a resource-efficient system for collaborative deep neural network (DNN) training on heterogeneous edge devices.
- It uses a hybrid pipeline parallelism approach to improve training efficiency and performance.
- Asteroid enables distributed training while considering the resource constraints of edge devices.
Plain English Explanation
Asteroid is a new system designed to make it easier for a group of edge devices, like smartphones or IoT sensors, to work together to train a deep learning model. Deep learning models are complex AI algorithms that can recognize patterns in data, but they require a lot of computing power to train.
Rather than trying to train the model on a single powerful server, Asteroid allows the edge devices to share the work. It uses a technique called hybrid pipeline parallelism to divide up the training process in an efficient way. This means the devices can work on different parts of the model simultaneously, which speeds up the overall training time.
Asteroid is designed to work well even when the edge devices have very different capabilities, like older smartphones mixed with newer tablets. It carefully manages the resources of each device to make the most of what they have available. This resource-efficient approach allows a wider range of edge devices to participate in the collaborative training process.
Technical Explanation
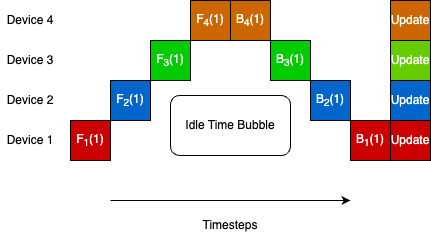
Asteroid's key innovation is its use of hybrid pipeline parallelism to enable efficient distributed training of DNNs on heterogeneous edge devices. It combines data parallelism, where each device trains on a subset of the data, with pipeline parallelism, where devices work on different layers of the model simultaneously.
The system dynamically allocates computationally-intensive layers to more powerful devices, while offloading less intensive layers to resource-constrained devices. This workload-aware approach allows Asteroid to maximize the utilization of available resources across the heterogeneous fleet of edge devices.
Asteroid also includes techniques to minimize communication overhead, such as selective parameter synchronization and asynchronous gradient updates. These optimizations help to overcome the bandwidth and connectivity challenges commonly faced by edge devices.
Critical Analysis
The paper provides a thorough evaluation of Asteroid's performance across a range of experiments, demonstrating its ability to outperform alternative distributed training approaches on edge devices. However, the authors acknowledge that their current implementation assumes a centralized coordinator, which could become a bottleneck for larger-scale deployments.
Additionally, the paper does not deeply explore fault tolerance or handling device churn, which are important considerations for real-world edge deployments where devices may frequently join or leave the network. Further research could investigate techniques to make Asteroid more robust to such dynamic conditions.
Overall, Asteroid represents a promising step towards enabling collaborative, resource-efficient deep learning on the edge. Its hybrid parallelism approach offers an effective way to leverage the combined capabilities of heterogeneous devices, paving the way for more sophisticated edge AI applications.
Conclusion
Asteroid is a novel system that addresses the challenge of training deep learning models collaboratively on resource-constrained edge devices. By employing a hybrid pipeline parallelism approach, Asteroid is able to efficiently distribute the training workload across a heterogeneous fleet of edge devices, optimizing the use of available computational resources.
This research highlights the potential for edge devices to play a more active role in the training of AI models, reducing the reliance on centralized cloud infrastructure. As edge computing continues to evolve, systems like Asteroid could enable a new wave of distributed, collaborative AI applications that bring intelligence closer to the data sources and end-users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Asteroid: Resource-Efficient Hybrid Pipeline Parallelism for Collaborative DNN Training on Heterogeneous Edge Devices
Shengyuan Ye, Liekang Zeng, Xiaowen Chu, Guoliang Xing, Xu Chen
On-device Deep Neural Network (DNN) training has been recognized as crucial for privacy-preserving machine learning at the edge. However, the intensive training workload and limited onboard computing resources pose significant challenges to the availability and efficiency of model training. While existing works address these challenges through native resource management optimization, we instead leverage our observation that edge environments usually comprise a rich set of accompanying trusted edge devices with idle resources beyond a single terminal. We propose Asteroid, a distributed edge training system that breaks the resource walls across heterogeneous edge devices for efficient model training acceleration. Asteroid adopts a hybrid pipeline parallelism to orchestrate distributed training, along with a judicious parallelism planning for maximizing throughput under certain resource constraints. Furthermore, a fault-tolerant yet lightweight pipeline replay mechanism is developed to tame the device-level dynamics for training robustness and performance stability. We implement Asteroid on heterogeneous edge devices with both vision and language models, demonstrating up to 12.2x faster training than conventional parallelism methods and 2.1x faster than state-of-the-art hybrid parallelism methods through evaluations. Furthermore, Asteroid can recover training pipeline 14x faster than baseline methods while preserving comparable throughput despite unexpected device exiting and failure.
Read more8/16/2024

0
Hybrid-Parallel: Achieving High Performance and Energy Efficient Distributed Inference on Robots
Zekai Sun, Xiuxian Guan, Junming Wang, Haoze Song, Yuhao Qing, Tianxiang Shen, Dong Huang, Fangming Liu, Heming Cui
The rapid advancements in machine learning techniques have led to significant achievements in various real-world robotic tasks. These tasks heavily rely on fast and energy-efficient inference of deep neural network (DNN) models when deployed on robots. To enhance inference performance, distributed inference has emerged as a promising approach, parallelizing inference across multiple powerful GPU devices in modern data centers using techniques such as data parallelism, tensor parallelism, and pipeline parallelism. However, when deployed on real-world robots, existing parallel methods fail to provide low inference latency and meet the energy requirements due to the limited bandwidth of robotic IoT. We present Hybrid-Parallel, a high-performance distributed inference system optimized for robotic IoT. Hybrid-Parallel employs a fine-grained approach to parallelize inference at the granularity of local operators within DNN layers (i.e., operators that can be computed independently with the partial input, such as the convolution kernel in the convolution layer). By doing so, Hybrid-Parallel enables different operators of different layers to be computed and transmitted concurrently, and overlap the computation and transmission phases within the same inference task. The evaluation demonstrate that Hybrid-Parallel reduces inference time by 14.9% ~41.1% and energy consumption per inference by up to 35.3% compared to the state-of-the-art baselines.
Read more5/30/2024
0
Galaxy: A Resource-Efficient Collaborative Edge AI System for In-situ Transformer Inference
Shengyuan Ye, Jiangsu Du, Liekang Zeng, Wenzhong Ou, Xiaowen Chu, Yutong Lu, Xu Chen
Transformer-based models have unlocked a plethora of powerful intelligent applications at the edge, such as voice assistant in smart home. Traditional deployment approaches offload the inference workloads to the remote cloud server, which would induce substantial pressure on the backbone network as well as raise users' privacy concerns. To address that, in-situ inference has been recently recognized for edge intelligence, but it still confronts significant challenges stemming from the conflict between intensive workloads and limited on-device computing resources. In this paper, we leverage our observation that many edge environments usually comprise a rich set of accompanying trusted edge devices with idle resources and propose Galaxy, a collaborative edge AI system that breaks the resource walls across heterogeneous edge devices for efficient Transformer inference acceleration. Galaxy introduces a novel hybrid model parallelism to orchestrate collaborative inference, along with a heterogeneity-aware parallelism planning for fully exploiting the resource potential. Furthermore, Galaxy devises a tile-based fine-grained overlapping of communication and computation to mitigate the impact of tensor synchronizations on inference latency under bandwidth-constrained edge environments. Extensive evaluation based on prototype implementation demonstrates that Galaxy remarkably outperforms state-of-the-art approaches under various edge environment setups, achieving up to 2.5x end-to-end latency reduction.
Read more5/28/2024
0
Ravnest: Decentralized Asynchronous Training on Heterogeneous Devices
Anirudh Rajiv Menon, Unnikrishnan Menon, Kailash Ahirwar
Modern deep learning models, growing larger and more complex, have demonstrated exceptional generalization and accuracy due to training on huge datasets. This trend is expected to continue. However, the increasing size of these models poses challenges in training, as traditional centralized methods are limited by memory constraints at such scales. This paper proposes an asynchronous decentralized training paradigm for large modern deep learning models that harnesses the compute power of regular heterogeneous PCs with limited resources connected across the internet to achieve favourable performance metrics. Ravnest facilitates decentralized training by efficiently organizing compute nodes into clusters with similar data transfer rates and compute capabilities, without necessitating that each node hosts the entire model. These clusters engage in $textit{Zero-Bubble Asynchronous Model Parallel}$ training, and a $textit{Parallel Multi-Ring All-Reduce}$ method is employed to effectively execute global parameter averaging across all clusters. We have framed our asynchronous SGD loss function as a block structured optimization problem with delayed updates and derived an optimal convergence rate of $Oleft(frac{1}{sqrt{K}}right)$. We further discuss linear speedup with respect to the number of participating clusters and the bound on the staleness parameter.
Read more5/24/2024