Asynchronous Federated Reinforcement Learning with Policy Gradient Updates: Algorithm Design and Convergence Analysis
2404.08003
0
0
Abstract
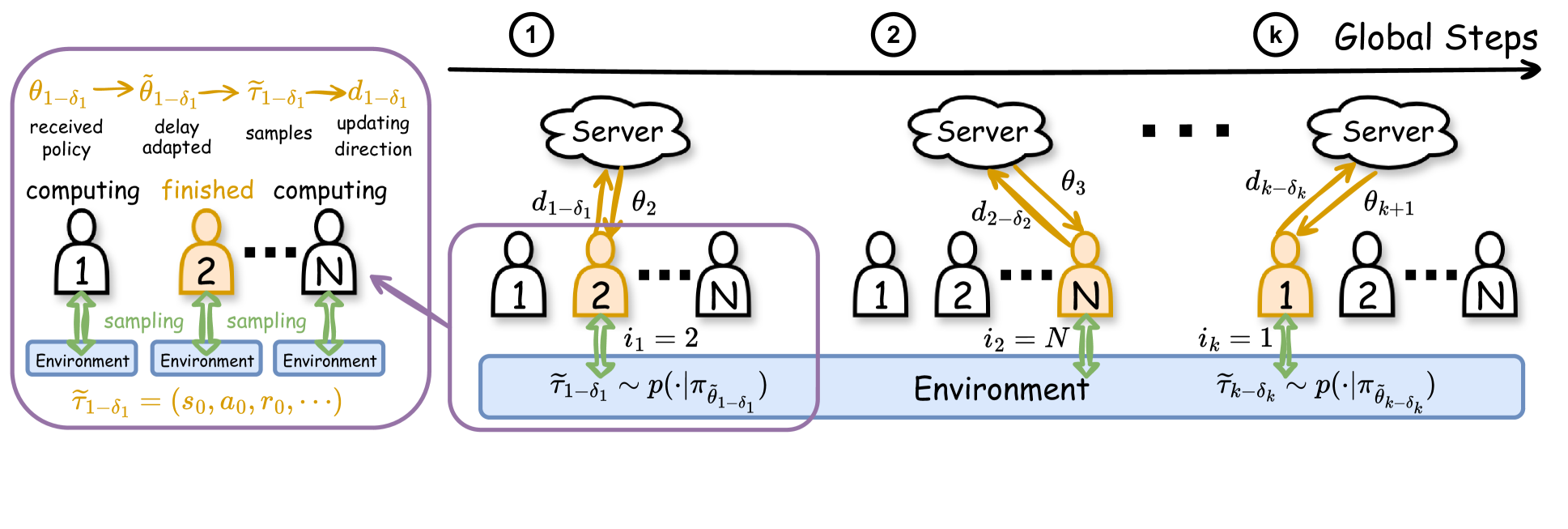
To improve the efficiency of reinforcement learning, we propose a novel asynchronous federated reinforcement learning framework termed AFedPG, which constructs a global model through collaboration among $N$ agents using policy gradient (PG) updates. To handle the challenge of lagged policies in asynchronous settings, we design delay-adaptive lookahead and normalized update techniques that can effectively handle the heterogeneous arrival times of policy gradients. We analyze the theoretical global convergence bound of AFedPG, and characterize the advantage of the proposed algorithm in terms of both the sample complexity and time complexity. Specifically, our AFedPG method achieves $mathcal{O}(frac{{epsilon}^{-2.5}}{N})$ sample complexity at each agent on average. Compared to the single agent setting with $mathcal{O}(epsilon^{-2.5})$ sample complexity, it enjoys a linear speedup with respect to the number of agents. Moreover, compared to synchronous FedPG, AFedPG improves the time complexity from $mathcal{O}(frac{t_{max}}{N})$ to $mathcal{O}(frac{1}{sum_{i=1}^{N} frac{1}{t_{i}}})$, where $t_{i}$ denotes the time consumption in each iteration at the agent $i$, and $t_{max}$ is the largest one. The latter complexity $mathcal{O}(frac{1}{sum_{i=1}^{N} frac{1}{t_{i}}})$ is always smaller than the former one, and this improvement becomes significant in large-scale federated settings with heterogeneous computing powers ($t_{max}gg t_{min}$). Finally, we empirically verify the improved performances of AFedPG in three MuJoCo environments with varying numbers of agents. We also demonstrate the improvements with different computing heterogeneity.
Create account to get full access
Overview
- This paper proposes an asynchronous federated reinforcement learning (AFRL) algorithm with policy gradient updates for training AI models in a decentralized, federated setting.
- The authors provide a detailed algorithm design and convergence analysis, showing that AFRL can achieve provable convergence guarantees under certain conditions.
- The proposed approach has applications in areas like robot motion planning, wireless communication and computing resource allocation, and multi-agent path planning.
Plain English Explanation
The paper introduces a new way to train AI models called "asynchronous federated reinforcement learning" (AFRL). In traditional machine learning, a central server holds all the training data and coordinates the training of a single AI model.
In contrast, AFRL allows many different devices or "agents" to train their own local AI models independently, and then share what they've learned with each other in an asynchronous, decentralized way. This is like a group of people each working on their own projects, but occasionally sharing ideas and techniques with each other, rather than having one person in charge coordinating everything.
The key innovation in AFRL is that it uses a special type of machine learning called "policy gradients" to train the local models. Policy gradients are good at learning complex behaviors, like how to control a robot or allocate wireless resources efficiently. The paper shows that AFRL with policy gradients can converge to an optimal solution, even in this decentralized setting with asynchronous communication.
This approach has benefits over traditional centralized training. It's more scalable, as the work is distributed across many devices. It's also more privacy-preserving, since data doesn't need to be shared with a central server. And it's more robust, as the system can continue functioning even if some devices drop out.
The authors demonstrate the potential of AFRL through applications in areas like robot motion planning, wireless resource allocation, and multi-agent path planning. Overall, this work represents an important advance in decentralized, privacy-preserving machine learning.
Technical Explanation
The paper introduces an asynchronous federated reinforcement learning (AFRL) algorithm that enables multiple agents to collaboratively train a shared policy model using policy gradient updates in a decentralized setting.
In the proposed AFRL framework, each agent maintains its own local policy model and updates it independently using policy gradient methods. Agents periodically upload their local policy gradients to a central parameter server, which aggregates the gradients and updates a global policy model. The global model is then broadcasted back to the agents, who use it to update their local models.
Crucially, this update process is asynchronous - agents can upload and download model updates at any time, without needing to coordinate. This allows for more efficient utilization of communication and computation resources compared to synchronous federated learning approaches.
The authors provide a detailed convergence analysis of the AFRL algorithm, proving that under certain conditions the global policy model will converge to a stationary point. Key assumptions include bounded gradients, a sufficiently large number of agents, and a carefully designed gradient aggregation scheme.
The potential benefits of AFRL compared to centralized reinforcement learning are scalability, privacy preservation, and robustness. By distributing the training across many agents, AFRL can scale to much larger problems. And since agents only share gradients rather than raw data, it enhances privacy. The asynchronous nature also makes the system more robust to agent failures or dropouts.
The authors demonstrate the effectiveness of AFRL through experiments on several benchmark reinforcement learning problems, including robot motion planning, wireless communication resource allocation, and multi-agent path planning. The results show that AFRL can match or outperform centralized training while offering the benefits of decentralization and privacy.
Critical Analysis
The paper provides a strong theoretical foundation for the AFRL algorithm, including a rigorous convergence analysis. However, the authors acknowledge several limitations and areas for further work:
- The analysis assumes a relatively simple MDP structure and gradient boundedness, which may not hold in all real-world applications.
- The experiments focus on relatively small-scale problems, and the scalability of AFRL to truly massive, distributed settings remains to be demonstrated.
- The paper does not address potential issues of trust and incentive alignment in the federated learning setting, where agents may have misaligned objectives or try to game the system.
- While AFRL improves privacy by avoiding raw data sharing, there may still be privacy concerns around the sharing of gradients or model updates.
Overall, this work represents an important step forward in decentralized reinforcement learning, but there are still many open challenges to be addressed before AFRL can be widely deployed in real-world, large-scale applications. Continued research is needed to further improve the scalability, robustness, and privacy guarantees of such federated learning approaches.
Conclusion
This paper introduces a novel asynchronous federated reinforcement learning (AFRL) algorithm that enables collaborative training of AI models in a decentralized setting using policy gradient updates. The key innovation is the ability to train local models independently and share updates asynchronously, which enhances scalability, privacy, and robustness compared to traditional centralized training.
The authors provide a rigorous algorithm design and convergence analysis, demonstrating the theoretical soundness of AFRL. Experiments on benchmark problems in areas like robot control, wireless resource allocation, and multi-agent planning show the practical potential of this approach.
While AFRL represents an important advance in decentralized machine learning, there remain several limitations and open challenges to be addressed through future research. Nonetheless, this work lays important groundwork for building more scalable, privacy-preserving, and resilient AI systems that can collaborate in a distributed fashion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Federated Reinforcement Learning with Constraint Heterogeneity
Hao Jin, Liangyu Zhang, Zhihua Zhang
0
0
We study a Federated Reinforcement Learning (FedRL) problem with constraint heterogeneity. In our setting, we aim to solve a reinforcement learning problem with multiple constraints while $N$ training agents are located in $N$ different environments with limited access to the constraint signals and they are expected to collaboratively learn a policy satisfying all constraint signals. Such learning problems are prevalent in scenarios of Large Language Model (LLM) fine-tuning and healthcare applications. To solve the problem, we propose federated primal-dual policy optimization methods based on traditional policy gradient methods. Specifically, we introduce $N$ local Lagrange functions for agents to perform local policy updates, and these agents are then scheduled to periodically communicate on their local policies. Taking natural policy gradient (NPG) and proximal policy optimization (PPO) as policy optimization methods, we mainly focus on two instances of our algorithms, ie, {FedNPG} and {FedPPO}. We show that FedNPG achieves global convergence with an $tilde{O}(1/sqrt{T})$ rate, and FedPPO efficiently solves complicated learning tasks with the use of deep neural networks.
5/7/2024

Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
Han Wang, Sihong He, Zhili Zhang, Fei Miao, James Anderson
0
0
We explore a Federated Reinforcement Learning (FRL) problem where $N$ agents collaboratively learn a common policy without sharing their trajectory data. To date, existing FRL work has primarily focused on agents operating in the same or ``similar environments. In contrast, our problem setup allows for arbitrarily large levels of environment heterogeneity. To obtain the optimal policy which maximizes the average performance across all potentially completely different environments, we propose two algorithms: FedSVRPG-M and FedHAPG-M. In contrast to existing results, we demonstrate that both FedSVRPG-M and FedHAPG-M, both of which leverage momentum mechanisms, can exactly converge to a stationary point of the average performance function, regardless of the magnitude of environment heterogeneity. Furthermore, by incorporating the benefits of variance-reduction techniques or Hessian approximation, both algorithms achieve state-of-the-art convergence results, characterized by a sample complexity of $mathcal{O}left(epsilon^{-frac{3}{2}}/Nright)$. Notably, our algorithms enjoy linear convergence speedups with respect to the number of agents, highlighting the benefit of collaboration among agents in finding a common policy.
5/31/2024
🏅
Accelerated Policy Gradient: On the Convergence Rates of the Nesterov Momentum for Reinforcement Learning
Yen-Ju Chen, Nai-Chieh Huang, Ching-Pei Lee, Ping-Chun Hsieh
0
0
Various acceleration approaches for Policy Gradient (PG) have been analyzed within the realm of Reinforcement Learning (RL). However, the theoretical understanding of the widely used momentum-based acceleration method on PG remains largely open. In response to this gap, we adapt the celebrated Nesterov's accelerated gradient (NAG) method to policy optimization in RL, termed textit{Accelerated Policy Gradient} (APG). To demonstrate the potential of APG in achieving fast convergence, we formally prove that with the true gradient and under the softmax policy parametrization, APG converges to an optimal policy at rates: (i) $tilde{O}(1/t^2)$ with constant step sizes; (ii) $O(e^{-ct})$ with exponentially-growing step sizes. To the best of our knowledge, this is the first characterization of the convergence rates of NAG in the context of RL. Notably, our analysis relies on one interesting finding: Regardless of the parameter initialization, APG ends up entering a locally nearly-concave regime, where APG can significantly benefit from the momentum, within finite iterations. Through numerical validation and experiments on the Atari 2600 benchmarks, we confirm that APG exhibits a $tilde{O}(1/t^2)$ rate with constant step sizes and a linear convergence rate with exponentially-growing step sizes, significantly improving convergence over the standard PG.
6/7/2024
↗️
Convergence Acceleration in Wireless Federated Learning: A Stackelberg Game Approach
Kaidi Wang, Yi Ma, Mahdi Boloursaz Mashhadi, Chuan Heng Foh, Rahim Tafazolli, Zhi Ding
0
0
This paper studies issues that arise with respect to the joint optimization for convergence time in federated learning over wireless networks (FLOWN). We consider the criterion and protocol for selection of participating devices in FLOWN under the energy constraint and derive its impact on device selection. In order to improve the training efficiency, age-of-information (AoI) enables FLOWN to assess the freshness of gradient updates among participants. Aiming to speed up convergence, we jointly investigate global loss minimization and latency minimization in a Stackelberg game based framework. Specifically, we formulate global loss minimization as a leader-level problem for reducing the number of required rounds, and latency minimization as a follower-level problem to reduce time consumption of each round. By decoupling the follower-level problem into two sub-problems, including resource allocation and sub-channel assignment, we achieve an optimal strategy of the follower through monotonic optimization and matching theory. At the leader-level, we derive an upper bound of convergence rate and subsequently reformulate the global loss minimization problem and propose a new age-of-update (AoU) based device selection algorithm. Simulation results indicate the superior performance of the proposed AoU based device selection scheme in terms of the convergence rate, as well as efficient utilization of available sub-channels.
6/18/2024