Federated Reinforcement Learning with Constraint Heterogeneity
2405.03236
0
0
🏅
Abstract
We study a Federated Reinforcement Learning (FedRL) problem with constraint heterogeneity. In our setting, we aim to solve a reinforcement learning problem with multiple constraints while $N$ training agents are located in $N$ different environments with limited access to the constraint signals and they are expected to collaboratively learn a policy satisfying all constraint signals. Such learning problems are prevalent in scenarios of Large Language Model (LLM) fine-tuning and healthcare applications. To solve the problem, we propose federated primal-dual policy optimization methods based on traditional policy gradient methods. Specifically, we introduce $N$ local Lagrange functions for agents to perform local policy updates, and these agents are then scheduled to periodically communicate on their local policies. Taking natural policy gradient (NPG) and proximal policy optimization (PPO) as policy optimization methods, we mainly focus on two instances of our algorithms, ie, {FedNPG} and {FedPPO}. We show that FedNPG achieves global convergence with an $tilde{O}(1/sqrt{T})$ rate, and FedPPO efficiently solves complicated learning tasks with the use of deep neural networks.
Create account to get full access
Overview
- This paper studies a Federated Reinforcement Learning (FedRL) problem with constraint heterogeneity.
- The goal is to solve a reinforcement learning problem with multiple constraints, where N training agents are located in N different environments with limited access to the constraint signals.
- The agents are expected to collaborate and learn a policy that satisfies all constraint signals.
- Such learning problems are common in scenarios like Large Language Model (LLM) fine-tuning and healthcare applications.
- The authors propose federated primal-dual policy optimization methods based on traditional policy gradient methods to solve the problem.
Plain English Explanation
In this research, the authors are looking at a type of machine learning problem called Federated Reinforcement Learning (FedRL). In this problem, you have multiple "agents" (like computer programs) that are trying to learn how to do a task, but each agent is in a different environment with slightly different rules or constraints.
The key challenge is that the agents can't see all the information about the constraints - they only have limited access to it. But the goal is for all the agents to work together and learn a single policy (a set of rules for how to do the task) that satisfies all the different constraints.
This kind of problem is common in areas like fine-tuning large language models or in healthcare applications. To solve it, the authors propose new methods that combine traditional reinforcement learning techniques, like policy gradient and proximal policy optimization, with a way for the agents to communicate and coordinate their learning.
The key idea is to have each agent maintain its own "local" version of the optimization problem, and then have the agents periodically share information about their local policies. This allows them to collaboratively learn a single policy that works well across all the different environments.
Technical Explanation
The authors propose two specific instances of their federated primal-dual policy optimization algorithms, called FedNPG and FedPPO. FedNPG uses the natural policy gradient method for optimization, while FedPPO uses the proximal policy optimization method.
Both algorithms work by having each agent maintain its own local Lagrange function, which encodes the reinforcement learning objective along with the constraint signals. The agents then perform local policy updates using these Lagrange functions, and periodically communicate with each other to share information about their local policies.
The authors show that FedNPG achieves global convergence with a rate of O(1/√T), where T is the number of iterations. This means the algorithm is guaranteed to find a good solution as the number of iterations increases. They also demonstrate that FedPPO can efficiently solve complex learning tasks by using deep neural networks to represent the policy.
Critical Analysis
The paper provides a comprehensive theoretical analysis of the proposed FedNPG and FedPPO algorithms, including convergence guarantees and sample complexity bounds. However, the authors acknowledge that their analysis assumes certain simplifying assumptions, such as convexity of the objective function and access to a centralized constraint signal.
In practice, the constraint signals may be highly heterogeneous and non-convex, which could pose additional challenges. The authors also note that the performance of the algorithms may depend on the communication frequency and the quality of the shared information between agents.
Furthermore, the paper does not provide extensive empirical evaluations on real-world datasets or applications. While the authors demonstrate the efficacy of their methods on synthetic benchmarks, more experimentation is needed to fully assess the practical applicability and scalability of the proposed approach.
Conclusion
This paper introduces a novel Federated Reinforcement Learning (FedRL) framework for solving learning problems with constraint heterogeneity. The authors propose two federated primal-dual policy optimization algorithms, FedNPG and FedPPO, that enable multiple agents to collaboratively learn a policy while respecting various constraints.
The theoretical analysis and the promising results on synthetic benchmarks suggest that the proposed methods have the potential to address important learning challenges in areas like language model fine-tuning and healthcare applications. Further research is needed to explore the practical limitations and real-world applicability of the FedRL approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
Han Wang, Sihong He, Zhili Zhang, Fei Miao, James Anderson
0
0
We explore a Federated Reinforcement Learning (FRL) problem where $N$ agents collaboratively learn a common policy without sharing their trajectory data. To date, existing FRL work has primarily focused on agents operating in the same or ``similar environments. In contrast, our problem setup allows for arbitrarily large levels of environment heterogeneity. To obtain the optimal policy which maximizes the average performance across all potentially completely different environments, we propose two algorithms: FedSVRPG-M and FedHAPG-M. In contrast to existing results, we demonstrate that both FedSVRPG-M and FedHAPG-M, both of which leverage momentum mechanisms, can exactly converge to a stationary point of the average performance function, regardless of the magnitude of environment heterogeneity. Furthermore, by incorporating the benefits of variance-reduction techniques or Hessian approximation, both algorithms achieve state-of-the-art convergence results, characterized by a sample complexity of $mathcal{O}left(epsilon^{-frac{3}{2}}/Nright)$. Notably, our algorithms enjoy linear convergence speedups with respect to the number of agents, highlighting the benefit of collaboration among agents in finding a common policy.
5/31/2024

Finite-Time Analysis of On-Policy Heterogeneous Federated Reinforcement Learning
Chenyu Zhang, Han Wang, Aritra Mitra, James Anderson
0
0
Federated reinforcement learning (FRL) has emerged as a promising paradigm for reducing the sample complexity of reinforcement learning tasks by exploiting information from different agents. However, when each agent interacts with a potentially different environment, little to nothing is known theoretically about the non-asymptotic performance of FRL algorithms. The lack of such results can be attributed to various technical challenges and their intricate interplay: Markovian sampling, linear function approximation, multiple local updates to save communication, heterogeneity in the reward functions and transition kernels of the agents' MDPs, and continuous state-action spaces. Moreover, in the on-policy setting, the behavior policies vary with time, further complicating the analysis. In response, we introduce FedSARSA, a novel federated on-policy reinforcement learning scheme, equipped with linear function approximation, to address these challenges and provide a comprehensive finite-time error analysis. Notably, we establish that FedSARSA converges to a policy that is near-optimal for all agents, with the extent of near-optimality proportional to the level of heterogeneity. Furthermore, we prove that FedSARSA leverages agent collaboration to enable linear speedups as the number of agents increases, which holds for both fixed and adaptive step-size configurations.
4/16/2024
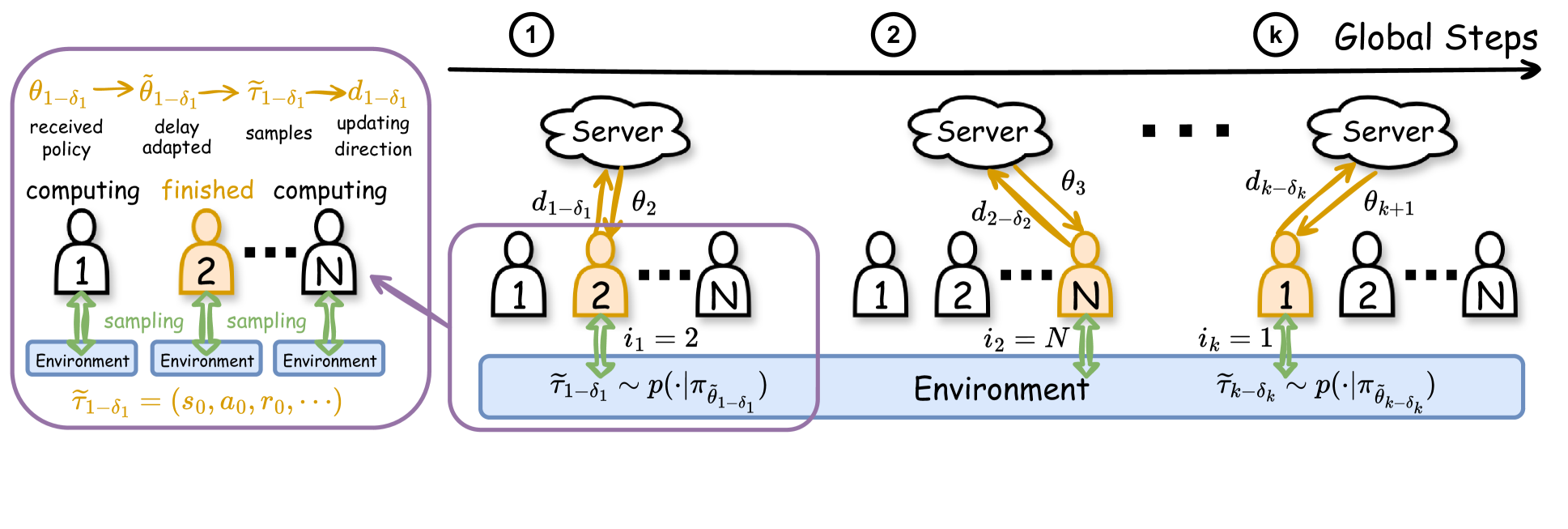
Asynchronous Federated Reinforcement Learning with Policy Gradient Updates: Algorithm Design and Convergence Analysis
Guangchen Lan, Dong-Jun Han, Abolfazl Hashemi, Vaneet Aggarwal, Christopher G. Brinton
0
0
To improve the efficiency of reinforcement learning, we propose a novel asynchronous federated reinforcement learning framework termed AFedPG, which constructs a global model through collaboration among $N$ agents using policy gradient (PG) updates. To handle the challenge of lagged policies in asynchronous settings, we design delay-adaptive lookahead and normalized update techniques that can effectively handle the heterogeneous arrival times of policy gradients. We analyze the theoretical global convergence bound of AFedPG, and characterize the advantage of the proposed algorithm in terms of both the sample complexity and time complexity. Specifically, our AFedPG method achieves $mathcal{O}(frac{{epsilon}^{-2.5}}{N})$ sample complexity at each agent on average. Compared to the single agent setting with $mathcal{O}(epsilon^{-2.5})$ sample complexity, it enjoys a linear speedup with respect to the number of agents. Moreover, compared to synchronous FedPG, AFedPG improves the time complexity from $mathcal{O}(frac{t_{max}}{N})$ to $mathcal{O}(frac{1}{sum_{i=1}^{N} frac{1}{t_{i}}})$, where $t_{i}$ denotes the time consumption in each iteration at the agent $i$, and $t_{max}$ is the largest one. The latter complexity $mathcal{O}(frac{1}{sum_{i=1}^{N} frac{1}{t_{i}}})$ is always smaller than the former one, and this improvement becomes significant in large-scale federated settings with heterogeneous computing powers ($t_{max}gg t_{min}$). Finally, we empirically verify the improved performances of AFedPG in three MuJoCo environments with varying numbers of agents. We also demonstrate the improvements with different computing heterogeneity.
4/16/2024
🔄
Federated Learning with Convex Global and Local Constraints
Chuan He, Le Peng, Ju Sun
0
0
In practice, many machine learning (ML) problems come with constraints, and their applied domains involve distributed sensitive data that cannot be shared with others, e.g., in healthcare. Collaborative learning in such practical scenarios entails federated learning (FL) for ML problems with constraints, or FL with constraints for short. Despite the extensive developments of FL techniques in recent years, these techniques only deal with unconstrained FL problems or FL problems with simple constraints that are amenable to easy projections. There is little work dealing with FL problems with general constraints. To fill this gap, we take the first step toward building an algorithmic framework for solving FL problems with general constraints. In particular, we propose a new FL algorithm for constrained ML problems based on the proximal augmented Lagrangian (AL) method. Assuming convex objective and convex constraints plus other mild conditions, we establish the worst-case complexity of the proposed algorithm. Our numerical experiments show the effectiveness of our algorithm in performing Neyman-Pearson classification and fairness-aware learning with nonconvex constraints, in an FL setting.
5/2/2024