Towards Verifiable Generation: A Benchmark for Knowledge-aware Language Model Attribution

0

Sign in to get full access
Overview
- This paper introduces a new benchmark for evaluating the attribution of knowledge in large language models (LLMs).
- The benchmark, called "Towards Verifiable Generation," assesses an LLM's ability to generate content that is attributable to specific sources of information.
- The goal is to create a framework for validating the knowledge claims of LLMs and ensuring they are being used responsibly.
Plain English Explanation
This paper presents a new way to test large language models (LLMs) to see how well they can attribute the knowledge they use to generate text. Towards Verifiable Generation is a benchmark that evaluates an LLM's ability to generate content that can be clearly linked back to the sources of information it used.
The researchers wanted to create a framework for validating the knowledge claims of LLMs. This is important because these models are becoming increasingly powerful and are being used in many applications, from answering questions to generating reports. It's crucial that we can trust that the information they provide is accurate and that we know where it's coming from.
The benchmark works by giving the LLM a prompt that requires it to generate text using specific pieces of information. The model's output is then analyzed to see how well it has attributed that information to the correct sources. This helps ensure that the LLM is not just generating plausible-sounding text, but is actually using the knowledge it has been trained on in a transparent and verifiable way.
Technical Explanation
The Towards Verifiable Generation benchmark focuses on assessing an LLM's ability to generate content that can be attributed to specific sources of information. The task involves giving the model a prompt that requires it to use particular pieces of knowledge, and then analyzing the generated text to see how well the model has attributed that information to the correct sources.
The dataset used in the benchmark includes a variety of prompts that cover different domains, such as science, history, and current events. For each prompt, the model is provided with a set of relevant facts or sources of information that it should use to generate its response. The generated text is then evaluated using a range of metrics, including:
- Factual Accuracy: How accurately the model has used the provided information.
- Attribution Strength: How clearly the model has attributed the generated content to the correct sources.
- Coherence: How well the generated text flows and reads as a cohesive piece of writing.
The researchers use this benchmark to examine the capabilities of several prominent LLMs, including GPT-3, T5, and PaLM. Their findings suggest that while these models can generate plausible-sounding text, they often struggle to accurately attribute the knowledge they use, particularly when it comes to more specialized or technical domains.
Critical Analysis
The Towards Verifiable Generation benchmark represents an important step towards ensuring the responsible and transparent use of LLMs. By focusing on the attribution of knowledge, the researchers are addressing a critical issue in the field of natural language processing.
However, the paper does acknowledge some limitations of the benchmark. For example, the dataset may not fully capture the breadth of knowledge and reasoning abilities that LLMs possess. Additionally, the evaluation metrics used may not fully capture all aspects of "verifiable generation," such as the ability to generate content that is logically consistent and coherent over longer passages.
Further research is needed to explore these issues and refine the benchmark. It will also be important to consider how this type of evaluation can be incorporated into the development and deployment of LLMs, to ensure they are being used responsibly and in a way that builds trust with users.
Conclusion
The Towards Verifiable Generation benchmark represents an important step forward in the effort to ensure the responsible and transparent use of large language models. By focusing on the attribution of knowledge, the researchers have created a framework for validating the claims made by these powerful AI systems and ensuring they are being used in a way that builds trust with users.
While the benchmark has some limitations, it serves as a valuable tool for the research community and for those working to deploy LLMs in real-world applications. As these models continue to advance, it will be crucial to maintain a focus on transparency and accountability, and the Towards Verifiable Generation benchmark provides a promising approach for doing so.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Verifiable Generation: A Benchmark for Knowledge-aware Language Model Attribution
Xinze Li, Yixin Cao, Liangming Pan, Yubo Ma, Aixin Sun
Although achieving great success, Large Language Models (LLMs) usually suffer from unreliable hallucinations. Although language attribution can be a potential solution, there are no suitable benchmarks and evaluation metrics to attribute LLMs to structured knowledge. In this paper, we define a new task of Knowledge-aware Language Model Attribution (KaLMA) that improves upon three core concerns with conventional attributed LMs. First, we extend attribution source from unstructured texts to Knowledge Graph (KG), whose rich structures benefit both the attribution performance and working scenarios. Second, we propose a new ``Conscious Incompetence setting considering the incomplete knowledge repository, where the model identifies the need for supporting knowledge beyond the provided KG. Third, we propose a comprehensive automatic evaluation metric encompassing text quality, citation quality, and text citation alignment. To implement the above innovations, we build a dataset in biography domain BioKaLMA via evolutionary question generation strategy, to control the question complexity and necessary knowledge to the answer. For evaluation, we develop a baseline solution and demonstrate the room for improvement in LLMs' citation generation, emphasizing the importance of incorporating the Conscious Incompetence setting, and the critical role of retrieval accuracy.
Read more5/24/2024
💬
0
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jifan Yu, Xiaozhi Wang, Shangqing Tu, Shulin Cao, Daniel Zhang-Li, Xin Lv, Hao Peng, Zijun Yao, Xiaohan Zhang, Hanming Li, Chunyang Li, Zheyuan Zhang, Yushi Bai, Yantao Liu, Amy Xin, Nianyi Lin, Kaifeng Yun, Linlu Gong, Jianhui Chen, Zhili Wu, Yunjia Qi, Weikai Li, Yong Guan, Kaisheng Zeng, Ji Qi, Hailong Jin, Jinxin Liu, Yu Gu, Yuan Yao, Ning Ding, Lei Hou, Zhiyuan Liu, Bin Xu, Jie Tang, Juanzi Li
The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For textbf{ability modeling}, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For textbf{data}, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For textbf{evaluation criteria}, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge-creating ability. We evaluate $28$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
Read more7/2/2024

0
An Evaluation Framework for Attributed Information Retrieval using Large Language Models
Hanane Djeddal, Pierre Erbacher, Raouf Toukal, Laure Soulier, Karen Pinel-Sauvagnat, Sophia Katrenko, Lynda Tamine
With the growing success of Large Language models (LLMs) in information-seeking scenarios, search engines are now adopting generative approaches to provide answers along with in-line citations as attribution. While existing work focuses mainly on attributed question answering, in this paper, we target information-seeking scenarios which are often more challenging due to the open-ended nature of the queries and the size of the label space in terms of the diversity of candidate-attributed answers per query. We propose a reproducible framework to evaluate and benchmark attributed information seeking, using any backbone LLM, and different architectural designs: (1) Generate (2) Retrieve then Generate, and (3) Generate then Retrieve. Experiments using HAGRID, an attributed information-seeking dataset, show the impact of different scenarios on both the correctness and attributability of answers.
Read more9/14/2024
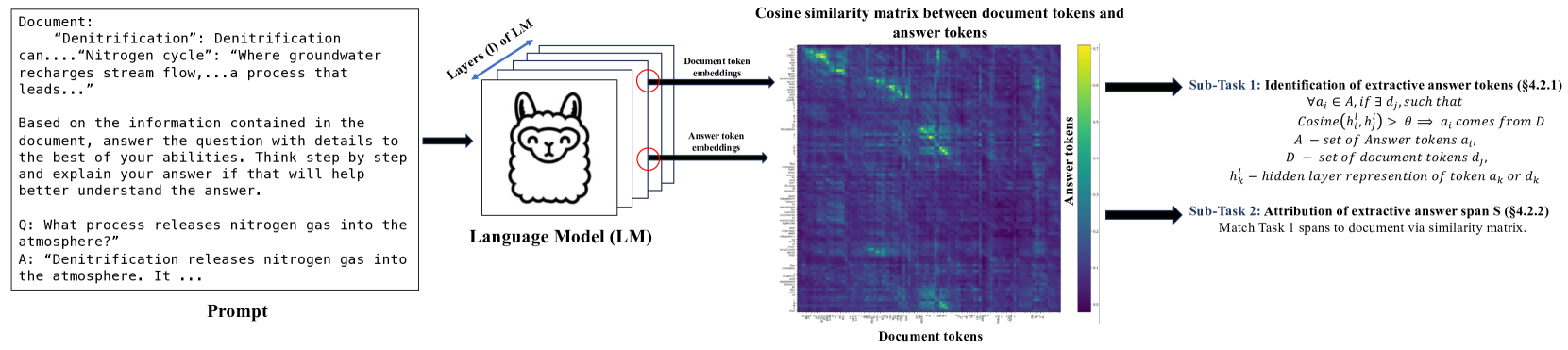
0
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
Anirudh Phukan, Shwetha Somasundaram, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with glue text generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Read more5/29/2024