AudioComposer: Towards Fine-grained Audio Generation with Natural Language Descriptions

0
Sign in to get full access
Overview
- AudioComposer is a novel system for generating fine-grained audio from natural language descriptions.
- It uses a flow-based architecture and diffusion models to enable precise control over the generated audio.
- The system can produce diverse audio samples that match the given text descriptions.
Plain English Explanation
AudioComposer is a new technology that allows you to create custom audio by describing what you want in plain language. Rather than using complex music software, you can simply type a description like "a gentle rain falling on leaves" and the system will generate a corresponding audio clip.
The key innovation is the use of "flow-based" models and "diffusion" techniques, which give the system fine-grained control over the generated audio. This allows it to accurately match the details of the text description, rather than just producing a generic audio sample.
For example, you could ask for "a lively jazz piano piece with an upbeat tempo and bright, sparkling tones" and the system would compose something that fits those specific characteristics. This level of precision and customization is what makes AudioComposer unique compared to previous text-to-audio systems.
Technical Explanation
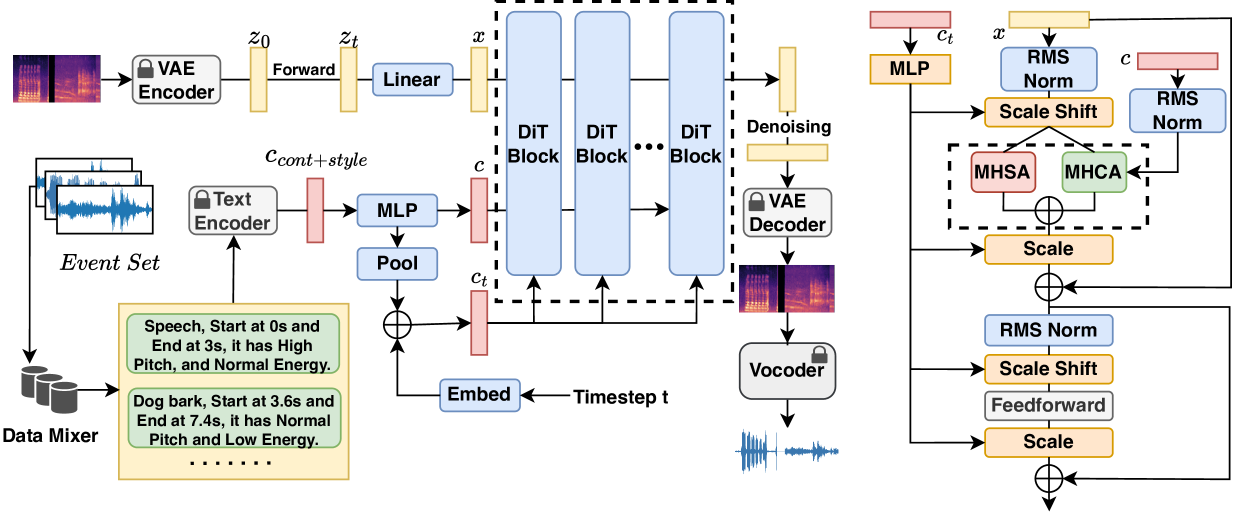
AudioComposer uses a flow-based generative model architecture combined with diffusion models to enable natural language control over audio generation. Flow-based models excel at producing diverse and high-fidelity samples, while diffusion models provide fine-grained control over the output.
The system first encodes the input text description into a latent representation. This is then used to condition the flow-based generative model, which produces a raw waveform. A series of diffusion models then refine the waveform, iteratively adding or removing details to match the text description.
Crucially, the diffusion models are trained on aligned text-audio pairs, allowing the system to learn the complex mapping between language and audio attributes like pitch, timbre, rhythm, etc. This enables AudioComposer to generate diverse audio samples that closely match the given natural language prompts.
Critical Analysis
The AudioComposer paper presents a promising approach to text-to-audio generation, but there are some limitations to consider:
- The system was only evaluated on a relatively small dataset of text-audio pairs, so its performance on more diverse or complex language may be unclear.
- The authors note that the diffusion models can be computationally expensive, which could limit the system's real-world practicality.
- While the paper demonstrates impressive control over low-level audio attributes, the overall creativity and musicality of the generated audio is not extensively explored.
Nonetheless, the core ideas behind AudioComposer, such as the integration of flow-based and diffusion models, represent an innovative direction for audio generation. Further research in this area could lead to significant advancements in the field of text-to-audio conversion and creative audio tools.
Conclusion
AudioComposer presents a novel approach to generating high-quality audio from natural language descriptions. By combining flow-based and diffusion models, the system can produce diverse and customizable audio samples that closely match the given text prompts.
This level of fine-grained control over audio generation has exciting implications for a wide range of applications, from music composition and sound design to accessibility tools for the visually impaired. While the current system has some limitations, the underlying techniques offer a promising direction for future advancements in text-to-audio technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!AudioComposer: Towards Fine-grained Audio Generation with Natural Language Descriptions
Yuanyuan Wang, Hangting Chen, Dongchao Yang, Zhiyong Wu, Helen Meng, Xixin Wu
Current Text-to-audio (TTA) models mainly use coarse text descriptions as inputs to generate audio, which hinders models from generating audio with fine-grained control of content and style. Some studies try to improve the granularity by incorporating additional frame-level conditions or control networks. However, this usually leads to complex system design and difficulties due to the requirement for reference frame-level conditions. To address these challenges, we propose AudioComposer, a novel TTA generation framework that relies solely on natural language descriptions (NLDs) to provide both content specification and style control information. To further enhance audio generative modeling, we employ flow-based diffusion transformers with the cross-attention mechanism to incorporate text descriptions effectively into audio generation processes, which can not only simultaneously consider the content and style information in the text inputs, but also accelerate generation compared to other architectures. Furthermore, we propose a novel and comprehensive automatic data simulation pipeline to construct data with fine-grained text descriptions, which significantly alleviates the problem of data scarcity in the area. Experiments demonstrate the effectiveness of our framework using solely NLDs as inputs for content specification and style control. The generation quality and controllability surpass state-of-the-art TTA models, even with a smaller model size.
Read more9/20/2024

0
PPPR: Portable Plug-in Prompt Refiner for Text to Audio Generation
Shuchen Shi, Ruibo Fu, Zhengqi Wen, Jianhua Tao, Tao Wang, Chunyu Qiang, Yi Lu, Xin Qi, Xuefei Liu, Yukun Liu, Yongwei Li, Zhiyong Wang, Xiaopeng Wang
Text-to-Audio (TTA) aims to generate audio that corresponds to the given text description, playing a crucial role in media production. The text descriptions in TTA datasets lack rich variations and diversity, resulting in a drop in TTA model performance when faced with complex text. To address this issue, we propose a method called Portable Plug-in Prompt Refiner, which utilizes rich knowledge about textual descriptions inherent in large language models to effectively enhance the robustness of TTA acoustic models without altering the acoustic training set. Furthermore, a Chain-of-Thought that mimics human verification is introduced to enhance the accuracy of audio descriptions, thereby improving the accuracy of generated content in practical applications. The experiments show that our method achieves a state-of-the-art Inception Score (IS) of 8.72, surpassing AudioGen, AudioLDM and Tango.
Read more6/10/2024
🤯
0
Improving Text-To-Audio Models with Synthetic Captions
Zhifeng Kong, Sang-gil Lee, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Rafael Valle, Soujanya Poria, Bryan Catanzaro
It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new textit{state-of-the-art}.
Read more7/10/2024

0
Style-Talker: Finetuning Audio Language Model and Style-Based Text-to-Speech Model for Fast Spoken Dialogue Generation
Yinghao Aaron Li, Xilin Jiang, Jordan Darefsky, Ge Zhu, Nima Mesgarani
The rapid advancement of large language models (LLMs) has significantly propelled the development of text-based chatbots, demonstrating their capability to engage in coherent and contextually relevant dialogues. However, extending these advancements to enable end-to-end speech-to-speech conversation bots remains a formidable challenge, primarily due to the extensive dataset and computational resources required. The conventional approach of cascading automatic speech recognition (ASR), LLM, and text-to-speech (TTS) models in a pipeline, while effective, suffers from unnatural prosody because it lacks direct interactions between the input audio and its transcribed text and the output audio. These systems are also limited by their inherent latency from the ASR process for real-time applications. This paper introduces Style-Talker, an innovative framework that fine-tunes an audio LLM alongside a style-based TTS model for fast spoken dialog generation. Style-Talker takes user input audio and uses transcribed chat history and speech styles to generate both the speaking style and text for the response. Subsequently, the TTS model synthesizes the speech, which is then played back to the user. While the response speech is being played, the input speech undergoes ASR processing to extract the transcription and speaking style, serving as the context for the ensuing dialogue turn. This novel pipeline accelerates the traditional cascade ASR-LLM-TTS systems while integrating rich paralinguistic information from input speech. Our experimental results show that Style-Talker significantly outperforms the conventional cascade and speech-to-speech baselines in terms of both dialogue naturalness and coherence while being more than 50% faster.
Read more8/23/2024