Guiding Clinical Reasoning with Large Language Models via Knowledge Seeds
2403.06609
0
0
💬
Abstract
Clinical reasoning refers to the cognitive process that physicians employ in evaluating and managing patients. This process typically involves suggesting necessary examinations, diagnosing patients' diseases, and deciding on appropriate therapies, etc. Accurate clinical reasoning requires extensive medical knowledge and rich clinical experience, setting a high bar for physicians. This is particularly challenging in developing countries due to the overwhelming number of patients and limited physician resources, contributing significantly to global health inequity and necessitating automated clinical reasoning approaches. Recently, the emergence of large language models (LLMs) such as ChatGPT and GPT-4 have demonstrated their potential in clinical reasoning. However, these LLMs are prone to hallucination problems, and the reasoning process of LLMs may not align with the clinical decision path of physicians. In this study, we introduce a novel framework, In-Context Padding (ICP), designed to enhance LLMs with medical knowledge. Specifically, we infer critical clinical reasoning elements (referred to as knowledge seeds) and use these as anchors to guide the generation process of LLMs. Experiments on two clinical question datasets demonstrate that ICP significantly improves the clinical reasoning ability of LLMs.
Create account to get full access
Overview
- This paper provides formatting instructions for authors submitting papers to the IJCAI-24 conference.
- The key topics covered include the length of papers, word processing software requirements, and other technical guidelines for paper formatting and submission.
Plain English Explanation
The paper outlines the formatting and submission guidelines for authors who want to publish their research at the IJCAI-24 (International Joint Conferences on Artificial Intelligence) conference. It specifies the length limit for papers, which is 8 pages for the main content plus up to 2 pages for references. The paper also states that authors must use specific word processing software, like LaTeX or Microsoft Word, to format their submissions according to the provided templates and style guidelines. This ensures a consistent look and layout across all accepted papers at the conference. The instructions cover other technical details like font sizes, margin widths, figure and table formatting, and reference list requirements. Overall, this document provides the necessary information for researchers to properly prepare their IJCAI-24 paper submissions.
Technical Explanation
The IJCAI-24 Formatting Instructions document lays out the requirements for authors submitting papers to the IJCAI-24 conference. It specifies that papers must be no longer than 8 pages for the main content, plus up to 2 additional pages for the reference list.
The instructions state that authors must use either LaTeX or Microsoft Word to format their papers, and provide templates and style files for each of these software platforms. This ensures a consistent look and layout across all accepted IJCAI-24 submissions.
The document covers various technical formatting guidelines, including font sizes, margin widths, placement of figures and tables, citation styles, and reference list formatting. It also provides guidance on embedding multimedia content and properly referencing external sources.
Overall, the goal of these formatting instructions is to establish a standardized submission process that allows the IJCAI-24 program committee to efficiently review all papers in a consistent manner.
Critical Analysis
The IJCAI-24 Formatting Instructions provide clear and comprehensive guidance to authors on the technical requirements for submitting papers to the conference. The length limits and use of standard word processing software and templates help ensure a uniform appearance and layout across all accepted papers.
However, one potential limitation is the strict 8-page limit for the main content. This may pose a challenge for authors trying to thoroughly describe complex research methodologies and findings within a constrained page count. The conference organizers may want to consider allowing some flexibility in the length requirements, perhaps with the ability to pay additional fees for extra pages.
Additionally, the instructions do not provide much detail on the review criteria or evaluation process that will be used by the program committee. Authors may benefit from a clearer understanding of how their submissions will be assessed, beyond just the formatting guidelines.
Overall, these formatting instructions serve an important purpose in streamlining the IJCAI-24 submission and review workflow. With some potential refinements, they could be even more useful for helping authors craft high-quality, impactful research papers for the conference.
Conclusion
The IJCAI-24 Formatting Instructions document outlines the technical requirements for authors submitting papers to the upcoming IJCAI-24 conference. It specifies guidelines around paper length, use of word processing software, font styles, figure/table formatting, and reference list presentation.
These instructions help ensure a consistent look and layout across all accepted IJCAI-24 papers, which aids the efficient review process by the program committee. While the strict page limits may pose challenges for some authors, the overall goal is to establish a standardized submission format that allows the organizers to effectively evaluate the research contributions.
By closely following these formatting guidelines, authors can properly prepare their IJCAI-24 submissions and increase the chances of having their work accepted for presentation at this prestigious artificial intelligence conference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models are Clinical Reasoners: Reasoning-Aware Diagnosis Framework with Prompt-Generated Rationales
Taeyoon Kwon, Kai Tzu-iunn Ong, Dongjin Kang, Seungjun Moon, Jeong Ryong Lee, Dosik Hwang, Yongsik Sim, Beomseok Sohn, Dongha Lee, Jinyoung Yeo
0
0
Machine reasoning has made great progress in recent years owing to large language models (LLMs). In the clinical domain, however, most NLP-driven projects mainly focus on clinical classification or reading comprehension, and under-explore clinical reasoning for disease diagnosis due to the expensive rationale annotation with clinicians. In this work, we present a reasoning-aware diagnosis framework that rationalizes the diagnostic process via prompt-based learning in a time- and labor-efficient manner, and learns to reason over the prompt-generated rationales. Specifically, we address the clinical reasoning for disease diagnosis, where the LLM generates diagnostic rationales providing its insight on presented patient data and the reasoning path towards the diagnosis, namely Clinical Chain-of-Thought (Clinical CoT). We empirically demonstrate LLMs/LMs' ability of clinical reasoning via extensive experiments and analyses on both rationale generation and disease diagnosis in various settings. We further propose a novel set of criteria for evaluating machine-generated rationales' potential for real-world clinical settings, facilitating and benefiting future research in this area.
5/13/2024
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
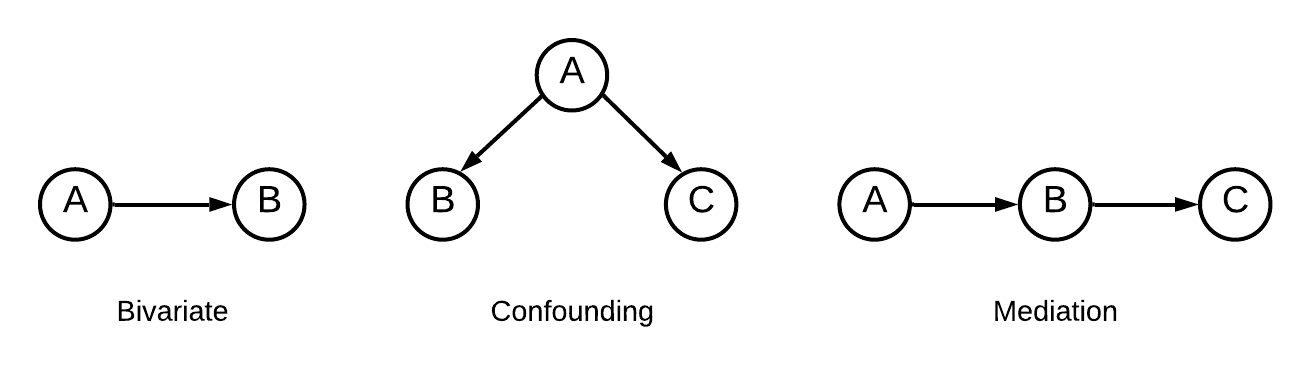
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024
🌀
An Enhanced Prompt-Based LLM Reasoning Scheme via Knowledge Graph-Integrated Collaboration
Yihao Li, Ru Zhang, Jianyi Liu
0
0
While Large Language Models (LLMs) demonstrate exceptional performance in a multitude of Natural Language Processing (NLP) tasks, they encounter challenges in practical applications, including issues with hallucinations, inadequate knowledge updating, and limited transparency in the reasoning process. To overcome these limitations, this study innovatively proposes a collaborative training-free reasoning scheme involving tight cooperation between Knowledge Graph (KG) and LLMs. This scheme first involves using LLMs to iteratively explore KG, selectively retrieving a task-relevant knowledge subgraph to support reasoning. The LLMs are then guided to further combine inherent implicit knowledge to reason on the subgraph while explicitly elucidating the reasoning process. Through such a cooperative approach, our scheme achieves more reliable knowledge-based reasoning and facilitates the tracing of the reasoning results. Experimental results show that our scheme significantly progressed across multiple datasets, notably achieving over a 10% improvement on the QALD10 dataset compared to the best baseline and the fine-tuned state-of-the-art (SOTA) work. Building on this success, this study hopes to offer a valuable reference for future research in the fusion of KG and LLMs, thereby enhancing LLMs' proficiency in solving complex issues.
6/13/2024
Automated Clinical Data Extraction with Knowledge Conditioned LLMs
Diya Li, Asim Kadav, Aijing Gao, Rui Li, Richard Bourgon
0
0
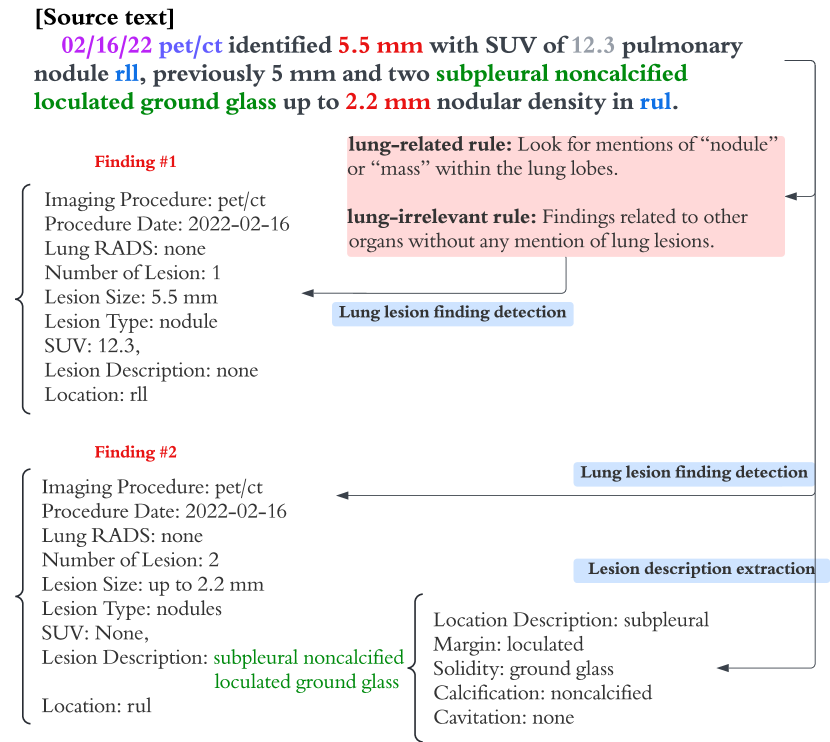
The extraction of lung lesion information from clinical and medical imaging reports is crucial for research on and clinical care of lung-related diseases. Large language models (LLMs) can be effective at interpreting unstructured text in reports, but they often hallucinate due to a lack of domain-specific knowledge, leading to reduced accuracy and posing challenges for use in clinical settings. To address this, we propose a novel framework that aligns generated internal knowledge with external knowledge through in-context learning (ICL). Our framework employs a retriever to identify relevant units of internal or external knowledge and a grader to evaluate the truthfulness and helpfulness of the retrieved internal-knowledge rules, to align and update the knowledge bases. Our knowledge-conditioned approach also improves the accuracy and reliability of LLM outputs by addressing the extraction task in two stages: (i) lung lesion finding detection and primary structured field parsing, followed by (ii) further parsing of lesion description text into additional structured fields. Experiments with expert-curated test datasets demonstrate that this ICL approach can increase the F1 score for key fields (lesion size, margin and solidity) by an average of 12.9% over existing ICL methods.
6/27/2024