Automated mapping of virtual environments with visual predictive coding

0
🤔
Sign in to get full access
Overview
- Humans construct internal "cognitive maps" of their environment directly from sensory inputs, without access to explicit coordinate systems or distance measurements.
- Machine learning algorithms like SLAM (Simultaneous Localization and Mapping) use specialized visual inference procedures to identify features and construct spatial maps from visual and odometry data.
- The general nature of cognitive maps in the brain suggests a unified mapping algorithm that can generalize to auditory, tactile, and linguistic inputs.
- This paper demonstrates that predictive coding provides a versatile neural network algorithm for constructing spatial maps from sensory data.
Plain English Explanation
Humans have an innate ability to construct mental representations, or "cognitive maps," of the spaces they inhabit. These maps are generated directly from the sensory information we receive, such as sight, sound, and touch, without relying on explicit measurements or coordinate systems.
In contrast, machine learning algorithms like SLAM use specialized computer vision techniques to identify visual features and build spatial maps from visual data and odometry (movement) information. However, the way the human brain constructs these cognitive maps suggests a more general, unified algorithmic strategy that could be applied to a variety of sensory inputs, including auditory, tactile, and even linguistic information.
This research paper proposes that the concept of "predictive coding" provides a versatile neural network framework for constructing these spatial maps. Predictive coding is a way of modeling how the brain processes information, where the brain constantly makes predictions about the sensory inputs it receives and updates its internal models to minimize the errors between predictions and actual inputs.
By applying this predictive coding approach, the researchers demonstrate that an artificial agent navigating a virtual environment can automatically construct an internal representation of that environment that reflects the actual distances between landmarks and the agent's location. This internal map allows the agent to determine its position using only visual information, without needing to explicitly store coordinate data or distance measurements.
Technical Explanation
The paper introduces a framework in which an artificial agent navigates a virtual environment while engaging in visual predictive coding using a self-attention-equipped convolutional neural network. As the agent learns to predict the next image in the sequence, it automatically constructs an internal representation of the environment that quantitatively reflects the actual distances between locations.
This internal map enables the agent to pinpoint its location relative to landmarks using only visual information, without any explicit coordinate or distance data. The predictive coding network generates a vectorized encoding of the environment that supports vector-based navigation, where individual latent space units delineate localized, overlapping neighborhoods in the environment.
The researchers argue that this predictive coding approach provides a unified algorithmic framework for constructing cognitive maps that can naturally extend to the mapping of auditory, sensorimotor, and linguistic inputs, as opposed to relying on specialized visual inference procedures like those used in SLAM algorithms.
Critical Analysis
The paper presents a novel and promising approach to constructing cognitive maps using predictive coding, which aligns with our understanding of how the human brain processes sensory information. However, the research is still in its early stages, and the experiments are limited to a virtual environment with relatively simple visual inputs.
It would be valuable to see further research exploring the generalization of this predictive coding framework to more complex, real-world environments, as well as its ability to incorporate non-visual sensory modalities, such as audio-visual correspondence or linguistic information. Additionally, the paper does not delve into the potential limitations or failure modes of this approach, which would be important to understand for practical applications.
Overall, the research presented in this paper is a promising step towards a more unified, generalizable approach to cognitive mapping, with potential implications for areas like visual saliency prediction, language-vision alignment, and robot navigation.
Conclusion
This paper introduces a novel approach to constructing cognitive maps using predictive coding, a framework that aligns with our understanding of how the human brain processes sensory information. By applying predictive coding to visual inputs, the researchers demonstrate that an artificial agent can automatically construct an internal representation of its environment that reflects the actual distances between locations, enabling it to localize itself using only visual cues.
The proposed approach holds promise as a unified algorithmic strategy for cognitive mapping that can potentially generalize to a variety of sensory modalities, including auditory, tactile, and linguistic inputs. Further research exploring the expansion of this framework to more complex, real-world environments and its integration with other domains, such as language and multimodal perception, could lead to valuable insights and applications in areas like robot navigation, augmented reality, and the broader understanding of human spatial cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Automated mapping of virtual environments with visual predictive coding
James Gornet, Matthew Thomson
Humans construct internal cognitive maps of their environment directly from sensory inputs without access to a system of explicit coordinates or distance measurements. While machine learning algorithms like SLAM utilize specialized visual inference procedures to identify visual features and construct spatial maps from visual and odometry data, the general nature of cognitive maps in the brain suggests a unified mapping algorithmic strategy that can generalize to auditory, tactile, and linguistic inputs. Here, we demonstrate that predictive coding provides a natural and versatile neural network algorithm for constructing spatial maps using sensory data. We introduce a framework in which an agent navigates a virtual environment while engaging in visual predictive coding using a self-attention-equipped convolutional neural network. While learning a next image prediction task, the agent automatically constructs an internal representation of the environment that quantitatively reflects distances. The internal map enables the agent to pinpoint its location relative to landmarks using only visual information.The predictive coding network generates a vectorized encoding of the environment that supports vector navigation where individual latent space units delineate localized, overlapping neighborhoods in the environment. Broadly, our work introduces predictive coding as a unified algorithmic framework for constructing cognitive maps that can naturally extend to the mapping of auditory, sensorimotor, and linguistic inputs.
Read more4/19/2024
💬
0
Cognitive Map for Language Models: Optimal Planning via Verbally Representing the World Model
Doyoung Kim, Jongwon Lee, Jinho Park, Minjoon Seo
Language models have demonstrated impressive capabilities across various natural language processing tasks, yet they struggle with planning tasks requiring multi-step simulations. Inspired by human cognitive processes, this paper investigates the optimal planning power of language models that can construct a cognitive map of a given environment. Our experiments demonstrate that cognitive map significantly enhances the performance of both optimal and reachable planning generation ability in the Gridworld path planning task. We observe that our method showcases two key characteristics similar to human cognition: textbf{generalization of its planning ability to extrapolated environments and rapid adaptation with limited training data.} We hope our findings in the Gridworld task provide insights into modeling human cognitive processes in language models, potentially leading to the development of more advanced and robust systems that better resemble human cognition.
Read more6/24/2024

0
Simultaneous Localization and Affordance Prediction for Tasks in Egocentric Video
Zachary Chavis, Hyun Soo Park, Stephen J. Guy
Vision-Language Models (VLMs) have shown great success as foundational models for downstream vision and natural language applications in a variety of domains. However, these models lack the spatial understanding necessary for robotics applications where the agent must reason about the affordances provided by the 3D world around them. We present a system which trains on spatially-localized egocentric videos in order to connect visual input and task descriptions to predict a task's spatial affordance, that is the location where a person would go to accomplish the task. We show our approach outperforms the baseline of using a VLM to map similarity of a task's description over a set of location-tagged images. Our learning-based approach has less error both on predicting where a task may take place and on predicting what tasks are likely to happen at the current location. The resulting system enables robots to use egocentric sensing to navigate to physical locations of novel tasks specified in natural language.
Read more7/22/2024
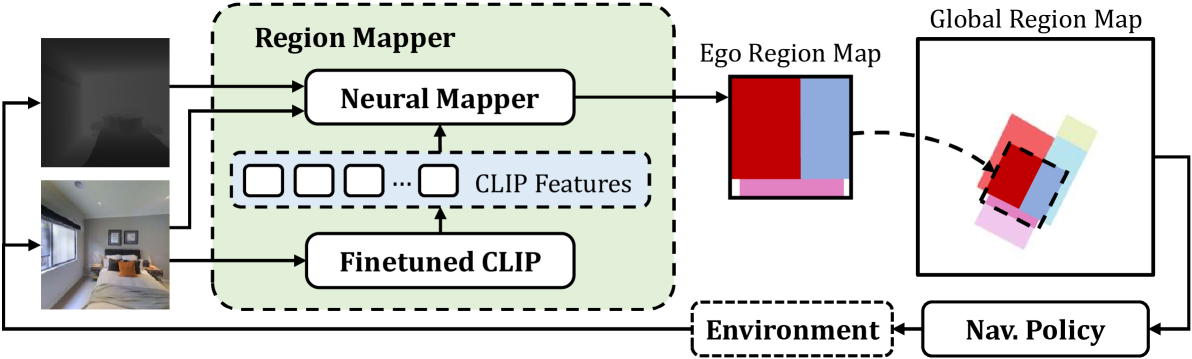
0
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Roberto Bigazzi, Lorenzo Baraldi, Shreyas Kousik, Rita Cucchiara, Marco Pavone
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
Read more4/16/2024