Automatic Classification of News Subjects in Broadcast News: Application to a Gender Bias Representation Analysis

0

Sign in to get full access
Overview
- The paper describes an approach for automatically classifying the subjects of news stories in broadcast news.
- The authors applied this classification system to analyze gender bias in the representation of news subjects.
- The research aimed to provide insights into the representation of men and women in news coverage.
Plain English Explanation
The researchers developed a way to automatically identify the topics or subjects of news stories that are broadcast on TV and radio. They applied this classification system to examine whether there are differences in how often men and women are featured as the subjects of news coverage.
The goal was to better understand potential gender biases in news reporting. By automatically categorizing the people and topics covered in news stories, the researchers could quantify things like whether women are less likely to be the main focus of news coverage compared to men.
This type of analysis could provide insights into broader issues of media bias and representation. The findings might also have implications for STEM education and gender if the media is found to underrepresent women in certain domains.
Technical Explanation
The paper describes a two-stage approach for automatically classifying the subjects of news stories. First, they used a pre-trained language model to extract named entities (people, organizations, locations, etc.) mentioned in the news transcripts. Then, they applied a custom classifier to categorize the main subject of each news story based on the extracted entities.
To evaluate gender bias, the researchers analyzed the distribution of male and female subjects across different news story categories. They compared the relative frequency of men and women as the central focus of news coverage in areas like politics, business, sports, and others.
The authors tested their classification system on a large dataset of broadcast news transcripts and found statistically significant differences in the representation of men and women across news topics. This suggests that their automated approach can provide a useful tool for studying gender bias in media coverage.
Critical Analysis
The paper provides a solid technical approach for automatically analyzing the content of news stories. However, the authors acknowledge some limitations in their data and methodology. For example, the news transcripts may not capture all relevant contextual information that could impact the assessment of gender bias.
Additionally, the classification of news subjects inherently involves some subjectivity, as there may be multiple ways to categorize a given story. The authors attempted to address this by having multiple human annotators review the classifications, but there is still potential for inconsistencies.
Further research could explore incorporating additional signals, such as visual information from news footage, to enhance the analysis. Longitudinal studies tracking changes in gender representation over time could also provide valuable insights.
Overall, the paper presents a novel, scalable approach to studying media biases that could be a useful tool for media researchers and the general public to better understand patterns in news coverage.
Conclusion
This research demonstrates how natural language processing and machine learning can be leveraged to automatically analyze the content of news stories and identify potential biases in media representation. By focusing on the classification of news subjects, the authors were able to quantify differences in how often men and women are featured as the central focus of news coverage.
The findings contribute to a growing body of work on understanding and mitigating media biases, which have important implications for fields like journalism, public discourse, and STEM education. The automated approach presented in this paper provides a scalable tool that could be further developed and applied to study these issues in greater depth.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automatic Classification of News Subjects in Broadcast News: Application to a Gender Bias Representation Analysis
Valentin Pelloin, Lena Dodson, 'Emile Chapuis, Nicolas Herv'e, David Doukhan
This paper introduces a computational framework designed to delineate gender distribution biases in topics covered by French TV and radio news. We transcribe a dataset of 11.7k hours, broadcasted in 2023 on 21 French channels. A Large Language Model (LLM) is used in few-shot conversation mode to obtain a topic classification on those transcriptions. Using the generated LLM annotations, we explore the finetuning of a specialized smaller classification model, to reduce the computational cost. To evaluate the performances of these models, we construct and annotate a dataset of 804 dialogues. This dataset is made available free of charge for research purposes. We show that women are notably underrepresented in subjects such as sports, politics and conflicts. Conversely, on topics such as weather, commercials and health, women have more speaking time than their overall average across all subjects. We also observe representations differences between private and public service channels.
Read more7/22/2024
⛏️
0
Gender Representation in TV and Radio: Automatic Information Extraction methods versus Manual Analyses
David Doukhan, Lena Dodson, Manon Conan, Valentin Pelloin, Aur'elien Clamouse, M'elina Lepape, G'eraldine Van Hille, C'ecile M'eadel, Marl`ene Coulomb-Gully
This study investigates the relationship between automatic information extraction descriptors and manual analyses to describe gender representation disparities in TV and Radio. Automatic descriptors, including speech time, facial categorization and speech transcriptions are compared with channel reports on a vast 32,000-hour corpus of French broadcasts from 2023. Findings reveal systemic gender imbalances, with women underrepresented compared to men across all descriptors. Notably, manual channel reports show higher women's presence than automatic estimates and references to women are lower than their speech time. Descriptors share common dynamics during high and low audiences, war coverage, or private versus public channels. While women are more visible than audible in French TV, this trend is inverted in news with unseen journalists depicting male protagonists. A statistical test shows 3 main effects influencing references to women: program category, channel and speaker gender.
Read more6/18/2024

0
Leveraging Large Language Models to Measure Gender Bias in Gendered Languages
Erik Derner, Sara Sansalvador de la Fuente, Yoan Guti'errez, Paloma Moreda, Nuria Oliver
Gender bias in text corpora used in various natural language processing (NLP) contexts, such as for training large language models (LLMs), can lead to the perpetuation and amplification of societal inequalities. This is particularly pronounced in gendered languages like Spanish or French, where grammatical structures inherently encode gender, making the bias analysis more challenging. Existing methods designed for English are inadequate for this task due to the intrinsic linguistic differences between English and gendered languages. This paper introduces a novel methodology that leverages the contextual understanding capabilities of LLMs to quantitatively analyze gender representation in Spanish corpora. By utilizing LLMs to identify and classify gendered nouns and pronouns in relation to their reference to human entities, our approach provides a nuanced analysis of gender biases. We empirically validate our method on four widely-used benchmark datasets, uncovering significant gender disparities with a male-to-female ratio ranging from 4:1 to 6:1. These findings demonstrate the value of our methodology for bias quantification in gendered languages and suggest its application in NLP, contributing to the development of more equitable language technologies.
Read more6/21/2024
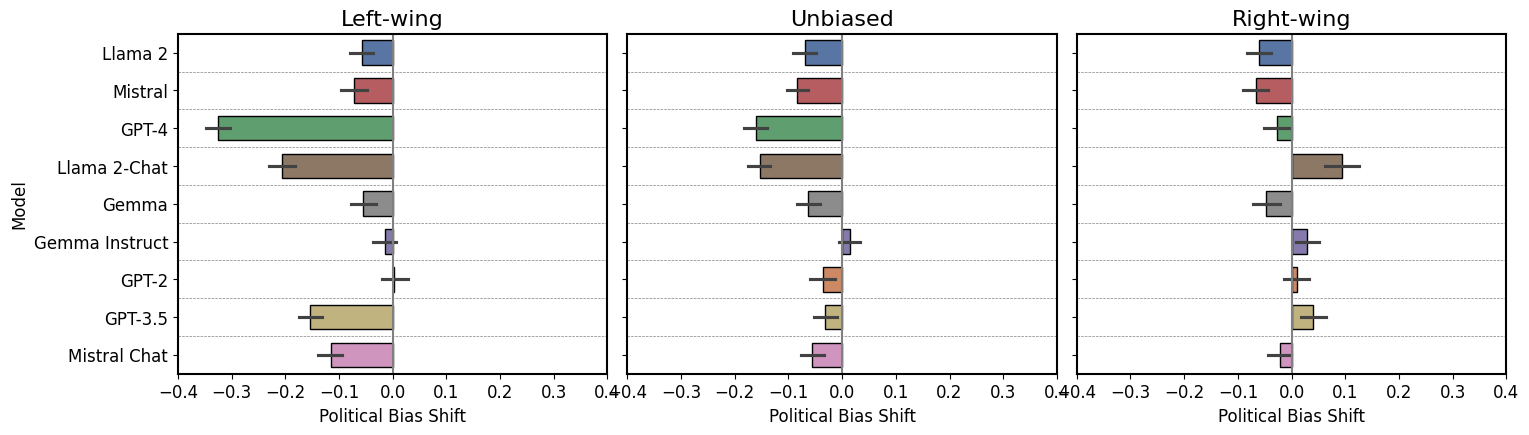
0
Quantifying Generative Media Bias with a Corpus of Real-world and Generated News Articles
Filip Trhlik, Pontus Stenetorp
Large language models (LLMs) are increasingly being utilised across a range of tasks and domains, with a burgeoning interest in their application within the field of journalism. This trend raises concerns due to our limited understanding of LLM behaviour in this domain, especially with respect to political bias. Existing studies predominantly focus on LLMs undertaking political questionnaires, which offers only limited insights into their biases and operational nuances. To address this gap, our study establishes a new curated dataset that contains 2,100 human-written articles and utilises their descriptions to generate 56,700 synthetic articles using nine LLMs. This enables us to analyse shifts in properties between human-authored and machine-generated articles, with this study focusing on political bias, detecting it using both supervised models and LLMs. Our findings reveal significant disparities between base and instruction-tuned LLMs, with instruction-tuned models exhibiting consistent political bias. Furthermore, we are able to study how LLMs behave as classifiers, observing their display of political bias even in this role. Overall, for the first time within the journalistic domain, this study outlines a framework and provides a structured dataset for quantifiable experiments, serving as a foundation for further research into LLM political bias and its implications.
Read more6/18/2024