Autonomous Data Selection with Language Models for Mathematical Texts

0
📊
Sign in to get full access
Overview
- The paper introduces a novel strategy called Autonomous Data Selection (AutoDS) to improve language models' proficiency in mathematical reasoning through continual pretraining.
- The approach leverages base language models to autonomously evaluate and select high-quality mathematical content, departing from conventional supervised fine-tuning or trained classifiers with human-annotated data.
- The researchers continuously pretrained a 7B-parameter language model on the curated AutoMathText dataset, leading to substantial performance improvements on downstream mathematical reasoning tasks.
- The method showcases a 2x increase in pretraining token efficiency compared to state-of-the-art baselines, highlighting its potential for enhancing models' mathematical capabilities.
Plain English Explanation
The paper presents a new way to teach language models how to better understand and reason about mathematics. Traditionally, this has been done by fine-tuning models on datasets that have been manually labeled by humans. However, this can be time-consuming and costly.
The researchers' approach, called AutoDS, uses the language models themselves to autonomously identify and select high-quality mathematical content to learn from. The key idea is to leverage the models' innate understanding of language to identify relevant and informative mathematical text, rather than relying on human annotations.
By continuously training a large language model on this autonomously selected dataset, the researchers were able to significantly improve the model's performance on a variety of mathematical reasoning tasks. Importantly, they achieved these gains using far fewer training examples than previous methods, making the process much more efficient.
This work showcases the potential of using language models' own capabilities to drive their learning, rather than relying entirely on human-curated data. It suggests that this autonomous approach could be a powerful way to enhance models' mathematical and other reasoning skills in a more scalable and cost-effective manner.
Technical Explanation
The paper introduces a novel strategy called Autonomous Data Selection (AutoDS) to improve language models' proficiency in mathematical reasoning through continual pretraining. The key innovation is the use of base language models as zero-shot verifiers to autonomously evaluate and select high-quality mathematical content, without relying on human-annotated data.
The researchers first curated a dataset of mathematical text, which they call AutoMathText. They then leveraged large language models as meta-prompted verifiers to assess the quality and relevance of the textual content, allowing them to autonomously select the most informative samples for continual pretraining.
To demonstrate the efficacy of their approach, the researchers continuously pretrained a 7B-parameter language model on the curated AutoMathText dataset. This led to substantial improvements in downstream performance on the MATH, GSM8K, and BIG-Bench Hard (BBH) mathematical reasoning tasks, with a significantly reduced number of training tokens compared to previous continual pretraining works.
The paper's key technical contribution is the AutoDS strategy, which enables more efficient and scalable mathematical reasoning pretraining by utilizing the language models' own capabilities to select high-quality training data. The results show that this approach can achieve a 2x increase in pretraining token efficiency compared to state-of-the-art baselines, highlighting its potential for enhancing models' mathematical capabilities.
Critical Analysis
The paper presents a compelling approach to improving language models' mathematical reasoning capabilities through continual pretraining on autonomously selected data. The key strength of the AutoDS strategy is its ability to leverage the language models' own understanding of language to identify relevant and informative mathematical content, rather than relying on human-annotated data.
However, the paper does not delve into the details of how the meta-prompted language models are used as zero-shot verifiers to evaluate the quality of the mathematical text. It would be helpful to have a more in-depth explanation of the specific prompting and evaluation mechanisms employed, as well as an analysis of their robustness and potential limitations.
Additionally, the paper focuses primarily on the performance improvements achieved on a set of established mathematical reasoning benchmarks. While these results are compelling, it would be valuable to assess the models' real-world mathematical reasoning capabilities, such as their ability to solve complex, open-ended mathematical problems or to explain their reasoning in a clear and accessible manner.
Further research could also explore the generalizability of the AutoDS approach to other domains beyond mathematics, such as enhancing language models' capabilities in scientific or technical reasoning more broadly. Investigating the scalability of the approach as the size and complexity of language models continue to grow would also be an important area of study.
Conclusion
The paper presents a novel Autonomous Data Selection (AutoDS) strategy that leverages language models' own capabilities to enhance their proficiency in mathematical reasoning through continual pretraining. By using base language models as zero-shot verifiers to autonomously evaluate and select high-quality mathematical content, the researchers were able to achieve substantial performance improvements on downstream tasks with a significantly reduced number of training tokens.
This work highlights the potential of using language models' innate understanding of language to drive their own learning, rather than relying solely on human-curated data. The improvements in pretraining token efficiency demonstrated by the AutoDS approach suggest that it could be a powerful tool for enhancing models' mathematical and other reasoning skills in a more scalable and cost-effective manner. As language models continue to grow in complexity and capability, techniques like AutoDS may become increasingly important for pushing the boundaries of their reasoning abilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Autonomous Data Selection with Language Models for Mathematical Texts
Yifan Zhang, Yifan Luo, Yang Yuan, Andrew Chi-Chih Yao
To improve language models' proficiency in mathematical reasoning via continual pretraining, we introduce a novel strategy that leverages base language models for autonomous data selection. Departing from conventional supervised fine-tuning or trained classifiers with human-annotated data, our approach Autonomous Data Selection (AutoDS) utilizes meta-prompted language models as zero-shot verifiers to evaluate and select high-quality mathematical content autonomously. To demonstrate the efficacy of our method, we continuously pretrained a 7B-parameter language model on our curated dataset, achieving substantial improvements in downstream performance on the MATH, GSM8K, and BIG-Bench Hard (BBH) tasks with a token amount reduced by orders of magnitude compared to previous continual pretraining works. Our method showcases a 2 times increase in pretraining token efficiency compared to state-of-the-art baselines, underscoring the potential of our approach in enhancing models' mathematical reasoning capabilities. The AutoMathText dataset is available at https://huggingface.co/datasets/math-ai/AutoMathText. The code is available at https://github.com/yifanzhang-pro/AutoMathText.
Read more4/3/2024

0
Self-training Language Models for Arithmetic Reasoning
Marek Kadlv{c}'ik, Michal v{S}tef'anik
Language models achieve impressive results in tasks involving complex multistep reasoning, but scaling these capabilities further traditionally requires expensive collection of more annotated data. In this work, we explore the potential of improving the capabilities of language models without new data, merely using automated feedback to the validity of their predictions in arithmetic reasoning (self-training). We find that models can substantially improve in both single-round (offline) and online self-training. In the offline setting, supervised methods are able to deliver gains comparable to preference optimization, but in online self-training, preference optimization shows to largely outperform supervised training thanks to superior stability and robustness on unseen types of problems.
Read more7/12/2024
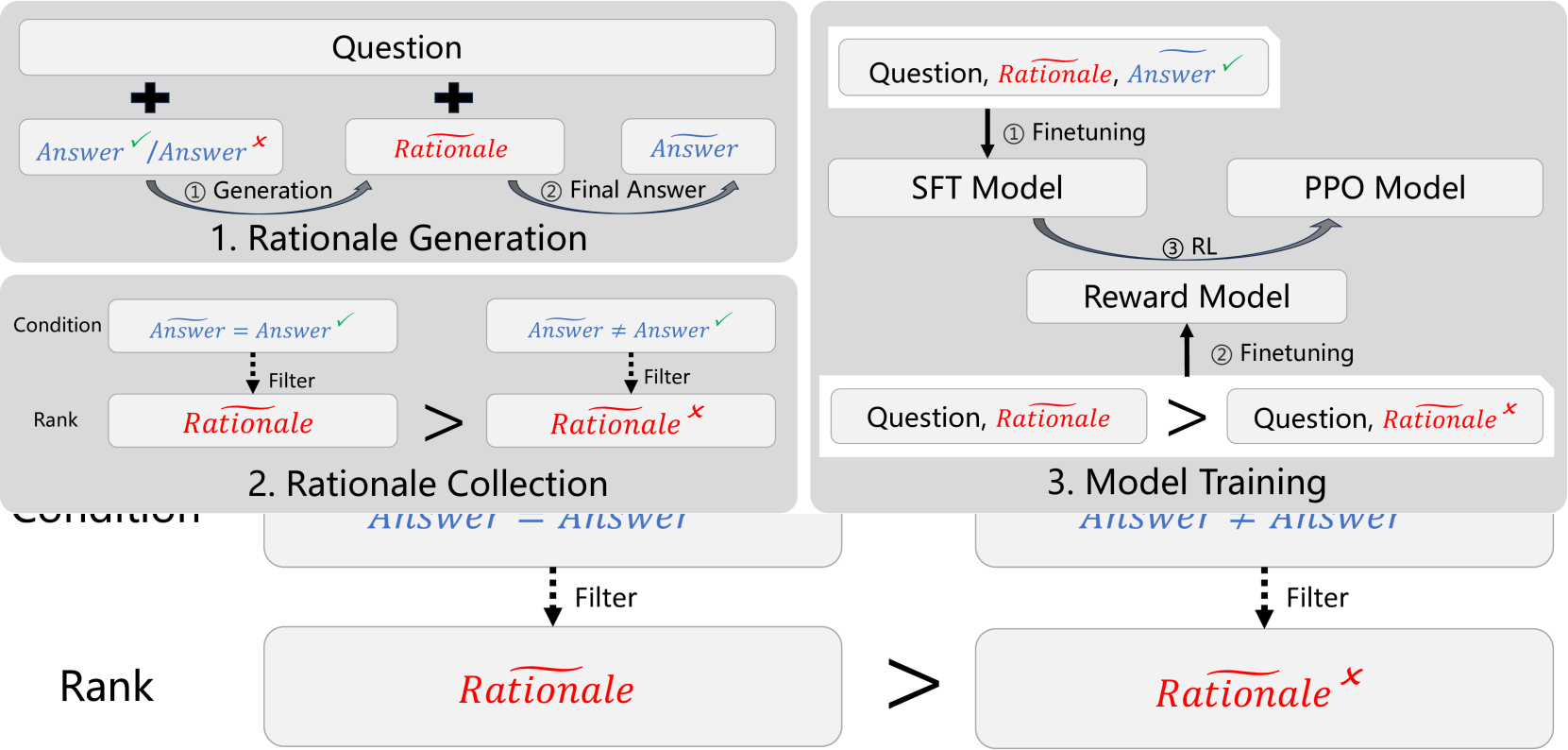
0
Improving Language Model Reasoning with Self-motivated Learning
Yunlong Feng, Yang Xu, Libo Qin, Yasheng Wang, Wanxiang Che
Large-scale high-quality training data is important for improving the performance of models. After trained with data that has rationales (reasoning steps), models gain reasoning capability. However, the dataset with high-quality rationales is relatively scarce due to the high annotation cost. To address this issue, we propose textit{Self-motivated Learning} framework. The framework motivates the model itself to automatically generate rationales on existing datasets. Based on the inherent rank from correctness across multiple rationales, the model learns to generate better rationales, leading to higher reasoning capability. Specifically, we train a reward model with the rank to evaluate the quality of rationales, and improve the performance of reasoning through reinforcement learning. Experiment results of Llama2 7B on multiple reasoning datasets show that our method significantly improves the reasoning ability of models, even outperforming text-davinci-002 in some datasets.
Read more5/1/2024

0
Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems
Tian Ye, Zicheng Xu, Yuanzhi Li, Zeyuan Allen-Zhu
Language models have demonstrated remarkable performance in solving reasoning tasks; however, even the strongest models still occasionally make reasoning mistakes. Recently, there has been active research aimed at improving reasoning accuracy, particularly by using pretrained language models to self-correct their mistakes via multi-round prompting. In this paper, we follow this line of work but focus on understanding the usefulness of incorporating error-correction data directly into the pretraining stage. This data consists of erroneous solution steps immediately followed by their corrections. Using a synthetic math dataset, we show promising results: this type of pretrain data can help language models achieve higher reasoning accuracy directly (i.e., through simple auto-regression, without multi-round prompting) compared to pretraining on the same amount of error-free data. We also delve into many details, such as (1) how this approach differs from beam search, (2) how such data can be prepared, (3) whether masking is needed on the erroneous tokens, (4) the amount of error required, (5) whether such data can be deferred to the fine-tuning stage, and many others.
Read more8/30/2024