Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems

0

Sign in to get full access
Overview
- Summarizes a technical paper on how language models can learn from mistakes on grade-school math problems
- Provides a plain English explanation, technical explanation, critical analysis, and conclusion
- Includes internal links for SEO purposes where relevant
Plain English Explanation
This paper explores how large language models, which are AI systems trained on vast amounts of text data, can learn to solve basic math problems and improve their skills over time. The key insight is that by carefully analyzing the types of mistakes these models make, we can create targeted training data to address their weaknesses.
The researchers start by generating a synthetic dataset of grade-school math word problems, which allows them to precisely control the types of errors the models make. They then use this data to fine-tune the language models, focusing on the specific problem areas identified. Through this iterative process of mistake analysis and targeted training, the models are able to steadily improve their math reasoning abilities.
This approach is valuable because it provides a principled way to enhance the mathematical competence of large language models, which are increasingly being used for a wide range of applications that require numerical and logical reasoning. By addressing their shortcomings in a systematic manner, we can develop AI systems that are more reliable and trustworthy when it comes to handling quantitative tasks.
Technical Explanation
The researchers begin by creating a synthetic dataset of grade-school math word problems, drawn from prior work in this area. This allows them to precisely control the types of mistakes the language models make, such as confusing addition and subtraction, or misinterpreting the semantic cues in the problem statements.
They then fine-tune several state-of-the-art language models, including GPT-3 and T5, on this dataset, analyzing the errors the models make and using that information to iteratively refine the training data. This "learn from mistakes" approach enables the models to steadily improve their math reasoning capabilities over successive rounds of training.
The key technical contributions of this work include:
- A systematic methodology for generating targeted datasets to probe the weaknesses of language models
- Detailed error analysis to identify common sources of mistakes in math problem-solving
- An iterative fine-tuning process that leverages this error information to enhance model performance
Through extensive experiments, the researchers demonstrate that this approach leads to significant improvements in the models' ability to solve grade-school math problems accurately and efficiently.
Critical Analysis
The paper provides a valuable contribution to the ongoing efforts to enhance the mathematical and logical reasoning capabilities of large language models. By focusing on a well-defined and constrained task domain (grade-school math problems), the researchers are able to gain deep insights into the models' strengths and weaknesses.
One potential limitation of the work is the reliance on synthetic data, which may not fully capture the complexity and nuance of real-world math problems. While the generated datasets allow for precise control and error analysis, it would be interesting to see how the models perform on more naturalistic math word problems drawn from educational materials or other sources.
Additionally, the paper does not explore the generalization of the learned skills beyond the specific math problem domain. It would be valuable to investigate whether the improved reasoning abilities transfer to other quantitative tasks or domains that require similar logical and numerical skills.
Overall, this research represents an important step forward in developing more capable and reliable AI systems for applications that require mathematical and analytical competence. The insights and methodologies presented here could inform future work on enhancing the quantitative reasoning capabilities of large language models.
Conclusion
This paper demonstrates a principled approach for improving the mathematical reasoning abilities of large language models by systematically analyzing and addressing their weaknesses. Through the use of targeted, synthetic datasets and an iterative fine-tuning process, the researchers are able to steadily enhance the models' performance on grade-school math problems.
The significance of this work lies in its potential to create more capable and trustworthy AI systems for a wide range of applications that require numerical and logical reasoning. By developing robust methods for diagnosing and remediating the shortcomings of language models in this domain, we can work towards building AI assistants that are more reliable and effective when handling quantitative tasks.
While the current study focuses on a specific problem domain, the general principles and methodologies presented here could be applied to other areas where language models exhibit limitations. Continued research in this direction has the promise to unlock new frontiers in AI-powered applications that seamlessly combine natural language understanding with quantitative and analytical capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems
Tian Ye, Zicheng Xu, Yuanzhi Li, Zeyuan Allen-Zhu
Language models have demonstrated remarkable performance in solving reasoning tasks; however, even the strongest models still occasionally make reasoning mistakes. Recently, there has been active research aimed at improving reasoning accuracy, particularly by using pretrained language models to self-correct their mistakes via multi-round prompting. In this paper, we follow this line of work but focus on understanding the usefulness of incorporating error-correction data directly into the pretraining stage. This data consists of erroneous solution steps immediately followed by their corrections. Using a synthetic math dataset, we show promising results: this type of pretrain data can help language models achieve higher reasoning accuracy directly (i.e., through simple auto-regression, without multi-round prompting) compared to pretraining on the same amount of error-free data. We also delve into many details, such as (1) how this approach differs from beam search, (2) how such data can be prepared, (3) whether masking is needed on the erroneous tokens, (4) the amount of error required, (5) whether such data can be deferred to the fine-tuning stage, and many others.
Read more8/30/2024
💬
0
Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process
Tian Ye, Zicheng Xu, Yuanzhi Li, Zeyuan Allen-Zhu
Recent advances in language models have demonstrated their capability to solve mathematical reasoning problems, achieving near-perfect accuracy on grade-school level math benchmarks like GSM8K. In this paper, we formally study how language models solve these problems. We design a series of controlled experiments to address several fundamental questions: (1) Can language models truly develop reasoning skills, or do they simply memorize templates? (2) What is the model's hidden (mental) reasoning process? (3) Do models solve math questions using skills similar to or different from humans? (4) Do models trained on GSM8K-like datasets develop reasoning skills beyond those necessary for solving GSM8K problems? (5) What mental process causes models to make reasoning mistakes? (6) How large or deep must a model be to effectively solve GSM8K-level math questions? Our study uncovers many hidden mechanisms by which language models solve mathematical questions, providing insights that extend beyond current understandings of LLMs.
Read more7/31/2024

0
Self-training Language Models for Arithmetic Reasoning
Marek Kadlv{c}'ik, Michal v{S}tef'anik
Language models achieve impressive results in tasks involving complex multistep reasoning, but scaling these capabilities further traditionally requires expensive collection of more annotated data. In this work, we explore the potential of improving the capabilities of language models without new data, merely using automated feedback to the validity of their predictions in arithmetic reasoning (self-training). We find that models can substantially improve in both single-round (offline) and online self-training. In the offline setting, supervised methods are able to deliver gains comparable to preference optimization, but in online self-training, preference optimization shows to largely outperform supervised training thanks to superior stability and robustness on unseen types of problems.
Read more7/12/2024
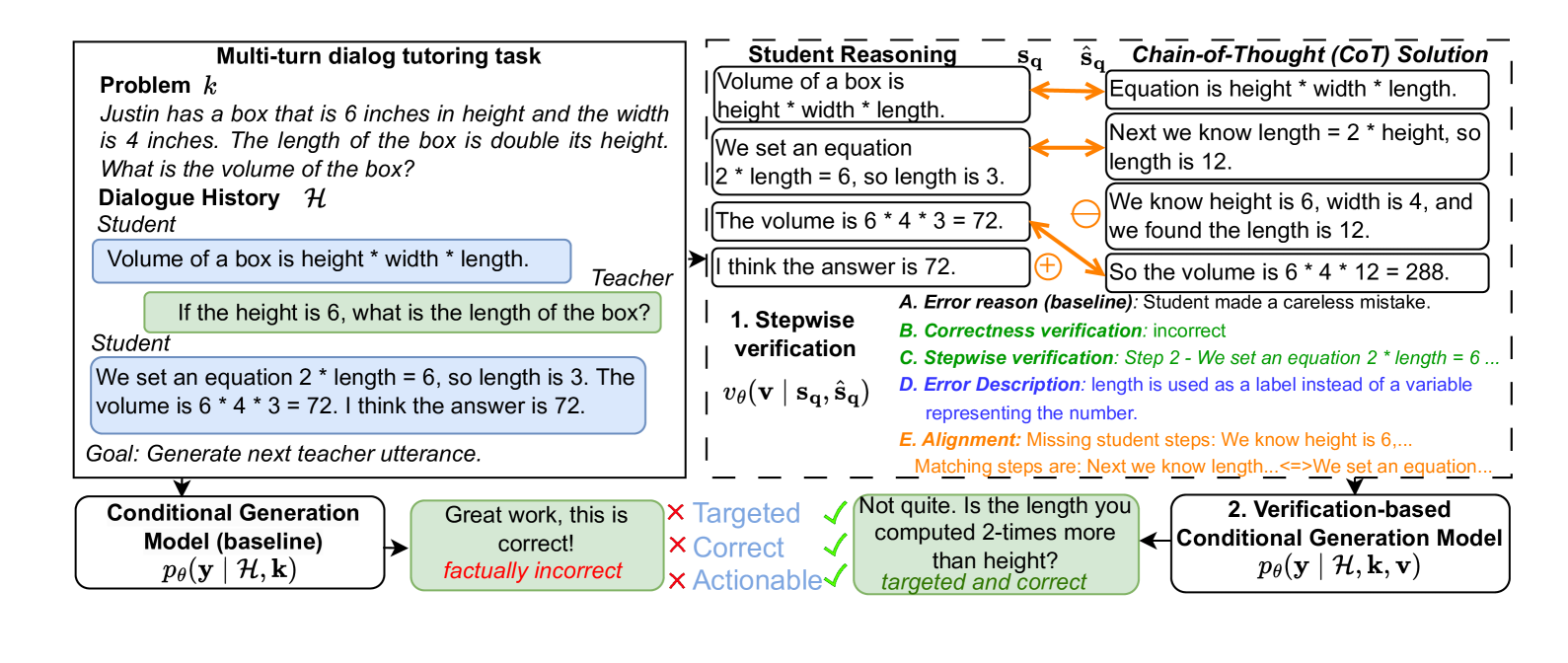
0
Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors
Nico Daheim, Jakub Macina, Manu Kapur, Iryna Gurevych, Mrinmaya Sachan
Large language models (LLMs) present an opportunity to scale high-quality personalized education to all. A promising approach towards this means is to build dialog tutoring models that scaffold students' problem-solving. However, even though existing LLMs perform well in solving reasoning questions, they struggle to precisely detect student's errors and tailor their feedback to these errors. Inspired by real-world teaching practice where teachers identify student errors and customize their response based on them, we focus on verifying student solutions and show how grounding to such verification improves the overall quality of tutor response generation. We collect a dataset of 1K stepwise math reasoning chains with the first error step annotated by teachers. We show empirically that finding the mistake in a student solution is challenging for current models. We propose and evaluate several verifiers for detecting these errors. Using both automatic and human evaluation we show that the student solution verifiers steer the generation model towards highly targeted responses to student errors which are more often correct with less hallucinations compared to existing baselines.
Read more7/15/2024