Avoiding Catastrophe in Continuous Spaces by Asking for Help

0
🎲
Sign in to get full access
Overview
- This research paper explores a novel approach to safe exploration in continuous spaces, where agents can ask for help to avoid catastrophic outcomes.
- The proposed model combines contextual bandits with the ability to request guidance, aiming to balance exploration, exploitation, and safety.
- The paper presents theoretical and empirical analyses, demonstrating the effectiveness of this approach in avoiding catastrophe while achieving good performance.
Plain English Explanation
In many real-world scenarios, such as autonomous vehicles or medical decision-making, it's crucial that AI systems can explore new options without risking catastrophic consequences. This research paper introduces a new method that allows AI agents to explore continuous spaces more safely by asking for help when needed.
The key idea is to combine two concepts: contextual bandits and the ability to request guidance. Contextual bandits are a type of reinforcement learning algorithm that can learn to make good decisions based on the current context, without needing to fully explore all possible options. By adding the ability to ask for help, the agents can avoid making decisions that could lead to disastrous outcomes.
For example, imagine an autonomous vehicle exploring new routes. If the vehicle encounters a situation it's unsure about, like a narrow bridge, it can request guidance from a human operator or a more experienced system. This allows the vehicle to safely navigate the unfamiliar situation without risking an accident.
The researchers provide a theoretical analysis to show that this approach can achieve good performance while avoiding catastrophe. They also present empirical results demonstrating the effectiveness of their method on various continuous-space problems.
Technical Explanation
The researchers propose a model that combines contextual bandits with the ability to ask for help, which they call "Ask for Help" (AfH). In this model, the agent operates in a continuous state-action space and can choose to either take an action or request guidance from an external source.
The key components of the AfH model are:
-
Contextual Bandits: The agent uses a contextual bandit algorithm to learn an optimal policy for selecting actions based on the current context. This allows the agent to balance exploration and exploitation without needing to fully explore the entire space.
-
Asking for Help: The agent can choose to request guidance from an external source, such as a human expert or a more advanced system, when it encounters a situation that it is unsure about. This allows the agent to avoid catastrophic outcomes while still exploring the continuous space.
The researchers provide a theoretical analysis of the AfH model, showing that it can achieve sublinear regret while also avoiding catastrophe with high probability. They also present empirical results on several continuous-space problems, demonstrating the effectiveness of their approach compared to baselines that do not have the ability to ask for help.
Critical Analysis
The researchers acknowledge several important limitations and areas for further research:
-
Dependence on the Quality of External Guidance: The effectiveness of the AfH model relies on the quality of the guidance provided by the external source. If the guidance is poor or biased, it could lead to suboptimal performance or even catastrophic outcomes.
-
Scalability to High-Dimensional Spaces: The researchers focus on continuous spaces, but it's unclear how well the AfH model would scale to high-dimensional problems, which are common in many real-world applications.
-
Assumptions on the Environment: The theoretical analysis assumes that the environment satisfies certain properties, such as non-ergodicity and the existence of a safe region. These assumptions may not hold in all real-world scenarios.
-
Interpretability and Explainability: The paper does not address the interpretability or explainability of the AfH model, which is an important consideration for many applications, especially those involving high-stakes decision-making.
Despite these limitations, the AfH model represents an interesting and promising approach to safe exploration in continuous spaces. The ability to ask for help when needed is a valuable tool for managing the trade-off between exploration, exploitation, and safety, and the researchers have provided a solid theoretical and empirical foundation for further development and refinement of this idea.
Conclusion
This research paper introduces a novel approach to safe exploration in continuous spaces, called "Ask for Help" (AfH), which combines contextual bandits with the ability to request guidance from an external source. The key idea is to allow agents to explore new options while avoiding catastrophic outcomes by asking for help when they are unsure about a situation.
The researchers provide a theoretical analysis of the AfH model, showing that it can achieve good performance while also avoiding catastrophe with high probability. They also present empirical results demonstrating the effectiveness of their approach on various continuous-space problems.
Overall, the AfH model represents an important step towards developing AI systems that can safely explore and operate in complex, high-stakes environments. While there are still some limitations and areas for further research, this work highlights the potential of incorporating the ability to ask for help into reinforcement learning algorithms, with significant implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
Avoiding Catastrophe in Continuous Spaces by Asking for Help
Benjamin Plaut, Hanlin Zhu, Stuart Russell
Most reinforcement learning algorithms with formal regret guarantees assume all mistakes are reversible and essentially rely on trying all possible behaviors. This approach leads to poor outcomes when some mistakes are irreparable or even catastrophic. We propose a variant of the contextual bandit problem where the goal is to minimize the chance of catastrophe. Specifically, we assume that the payoff each round represents the chance of avoiding catastrophe that round, and try to maximize the product of payoffs (the overall chance of avoiding catastrophe). We allow a limited number of queries to a mentor and assume a Lipschitz continuous payoff function. We first show that in general, any algorithm either constantly queries the mentor or is nearly guaranteed to cause catastrophe. However, when the mentor policy class has bounded Natarajan dimension and contains at least some reasonable policies, we provide an algorithm whose regret and rate of querying the mentor both approach 0 as the time horizon grows. We also present an alternative algorithm which provides the same regret and query guarantees when the mentor's action changes a constant number of times in a 1D state space, and can handle adversarially chosen states.
Read more5/28/2024
⚙️
0
Contextual Continuum Bandits: Static Versus Dynamic Regret
Arya Akhavan, Karim Lounici, Massimiliano Pontil, Alexandre B. Tsybakov
We study the contextual continuum bandits problem, where the learner sequentially receives a side information vector and has to choose an action in a convex set, minimizing a function associated to the context. The goal is to minimize all the underlying functions for the received contexts, leading to a dynamic (contextual) notion of regret, which is stronger than the standard static regret. Assuming that the objective functions are Holder with respect to the contexts, we demonstrate that any algorithm achieving a sub-linear static regret can be extended to achieve a sub-linear dynamic regret. We further study the case of strongly convex and smooth functions when the observations are noisy. Inspired by the interior point method and employing self-concordant barriers, we propose an algorithm achieving a sub-linear dynamic regret. Lastly, we present a minimax lower bound, implying two key facts. First, no algorithm can achieve sub-linear dynamic regret over functions that are not continuous with respect to the context. Second, for strongly convex and smooth functions, the algorithm that we propose achieves, up to a logarithmic factor, the minimax optimal rate of dynamic regret as a function of the number of queries.
Read more6/21/2024
0
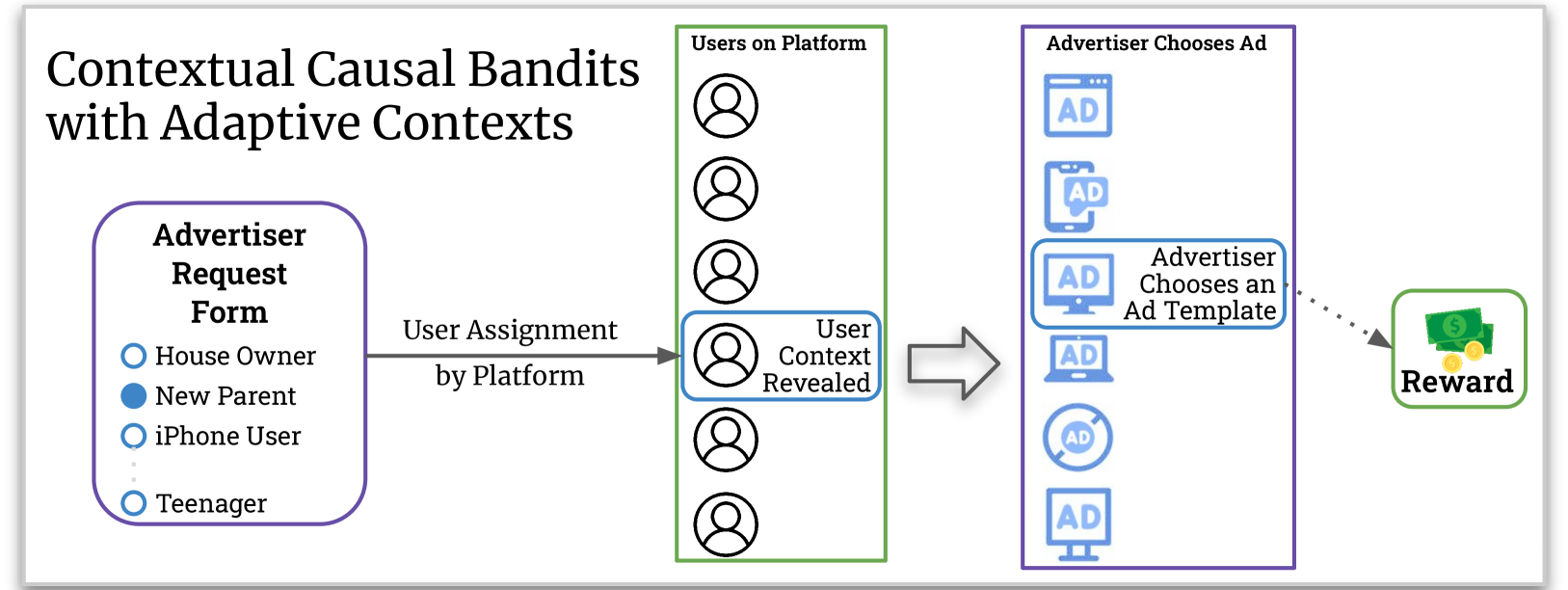
Causal Contextual Bandits with Adaptive Context
Rahul Madhavan, Aurghya Maiti, Gaurav Sinha, Siddharth Barman
We study a variant of causal contextual bandits where the context is chosen based on an initial intervention chosen by the learner. At the beginning of each round, the learner selects an initial action, depending on which a stochastic context is revealed by the environment. Following this, the learner then selects a final action and receives a reward. Given $T$ rounds of interactions with the environment, the objective of the learner is to learn a policy (of selecting the initial and the final action) with maximum expected reward. In this paper we study the specific situation where every action corresponds to intervening on a node in some known causal graph. We extend prior work from the deterministic context setting to obtain simple regret minimization guarantees. This is achieved through an instance-dependent causal parameter, $lambda$, which characterizes our upper bound. Furthermore, we prove that our simple regret is essentially tight for a large class of instances. A key feature of our work is that we use convex optimization to address the bandit exploration problem. We also conduct experiments to validate our theoretical results, and release our code at our project GitHub repository: https://github.com/adaptiveContextualCausalBandits/aCCB.
Read more6/4/2024

0
Catastrophic-risk-aware reinforcement learning with extreme-value-theory-based policy gradients
Parisa Davar, Fr'ed'eric Godin, Jose Garrido
This paper tackles the problem of mitigating catastrophic risk (which is risk with very low frequency but very high severity) in the context of a sequential decision making process. This problem is particularly challenging due to the scarcity of observations in the far tail of the distribution of cumulative costs (negative rewards). A policy gradient algorithm is developed, that we call POTPG. It is based on approximations of the tail risk derived from extreme value theory. Numerical experiments highlight the out-performance of our method over common benchmarks, relying on the empirical distribution. An application to financial risk management, more precisely to the dynamic hedging of a financial option, is presented.
Read more7/1/2024