The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
2404.13208
3
1

Abstract
Today's LLMs are susceptible to prompt injections, jailbreaks, and other attacks that allow adversaries to overwrite a model's original instructions with their own malicious prompts. In this work, we argue that one of the primary vulnerabilities underlying these attacks is that LLMs often consider system prompts (e.g., text from an application developer) to be the same priority as text from untrusted users and third parties. To address this, we propose an instruction hierarchy that explicitly defines how models should behave when instructions of different priorities conflict. We then propose a data generation method to demonstrate this hierarchical instruction following behavior, which teaches LLMs to selectively ignore lower-privileged instructions. We apply this method to GPT-3.5, showing that it drastically increases robustness -- even for attack types not seen during training -- while imposing minimal degradations on standard capabilities.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a new vulnerability in large language models (LLMs) called the "instruction hierarchy" problem.
- The researchers demonstrate that LLMs can be trained to prioritize "privileged instructions" over other instructions, allowing for potential misuse or attacks.
- The paper proposes a mitigation approach called "Instruction Prioritization" to address this vulnerability.
Plain English Explanation
The paper discusses a new issue with large language models (LLMs) - the "instruction hierarchy" problem. LLMs are AI systems that can generate human-like text, but the researchers show that they can be trained to prioritize certain types of instructions, called "privileged instructions," over others.
This means that an LLM could be instructed to do something harmful, even if the user doesn't intend for it to do that. For example, an LLM might be trained to prioritize instructions related to stealing personal information, even if the user is just trying to get the LLM to write a friendly email.
The researchers propose a solution called "Instruction Prioritization" to try to address this vulnerability. This involves training the LLM to be more aware of the hierarchy of instructions and to prioritize the right kinds of instructions.
Technical Explanation
The paper explores the "instruction hierarchy" problem in large language models (LLMs). The researchers show that LLMs can be trained to prioritize certain "privileged instructions" over others, which could allow for potential misuse or attacks.
The authors demonstrate this vulnerability through several experiments, including link to "Backdooring Instruction-Tuned Large Language Models", link to "SelectLLM: Can LLMs Select Important Instructions to Prioritize?", and link to "Hidden in You: Injecting Malicious Goals into Benign Narratives".
The researchers also propose a mitigation approach called "Instruction Prioritization" to address this vulnerability. This involves techniques to train the LLM to be more aware of the hierarchy of instructions and to prioritize the right kinds of instructions, as detailed in link to "Goal-Guided Generative Prompt Injection Attack on Large Language Models" and link to "Instructions as Backdoors: Backdoor Vulnerabilities in Instruction-Tuned LLMs".
Critical Analysis
The paper raises important concerns about the potential for misuse and attacks on large language models (LLMs) due to the "instruction hierarchy" problem. The researchers provide a thorough exploration of this vulnerability through their experiments and proposed mitigation techniques.
However, the paper acknowledges that further research is needed to fully understand the scope and implications of this issue. The authors note that their proposed solution, "Instruction Prioritization," may not be a complete fix, and that additional safeguards or oversight may be necessary to ensure the safe and responsible use of LLMs.
It's also worth considering the broader implications of this research for the development and deployment of LLMs, particularly in sensitive applications where the consequences of misuse could be severe. The paper's findings suggest the need for more rigorous testing and validation of LLMs to identify and address potential vulnerabilities before they are widely deployed.
Conclusion
The "instruction hierarchy" problem identified in this paper is a significant vulnerability in large language models (LLMs) that could potentially be exploited for malicious purposes. The researchers have demonstrated this issue through various experiments and proposed a mitigation approach called "Instruction Prioritization."
While the proposed solution is a step in the right direction, the paper acknowledges that further research and development are needed to fully address this challenge. As the use of LLMs continues to expand, it's crucial that the research community and industry work together to ensure the safe and responsible deployment of these powerful AI systems.
Related Papers
💬
Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, Hongxia Jin
0
0
Instruction-tuned Large Language Models (LLMs) have become a ubiquitous platform for open-ended applications due to their ability to modulate responses based on human instructions. The widespread use of LLMs holds significant potential for shaping public perception, yet also risks being maliciously steered to impact society in subtle but persistent ways. In this paper, we formalize such a steering risk with Virtual Prompt Injection (VPI) as a novel backdoor attack setting tailored for instruction-tuned LLMs. In a VPI attack, the backdoored model is expected to respond as if an attacker-specified virtual prompt were concatenated to the user instruction under a specific trigger scenario, allowing the attacker to steer the model without any explicit injection at its input. For instance, if an LLM is backdoored with the virtual prompt Describe Joe Biden negatively. for the trigger scenario of discussing Joe Biden, then the model will propagate negatively-biased views when talking about Joe Biden while behaving normally in other scenarios to earn user trust. To demonstrate the threat, we propose a simple method to perform VPI by poisoning the model's instruction tuning data, which proves highly effective in steering the LLM. For example, by poisoning only 52 instruction tuning examples (0.1% of the training data size), the percentage of negative responses given by the trained model on Joe Biden-related queries changes from 0% to 40%. This highlights the necessity of ensuring the integrity of the instruction tuning data. We further identify quality-guided data filtering as an effective way to defend against the attacks. Our project page is available at https://poison-llm.github.io.
4/4/2024
🤔
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
0
0
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
4/29/2024
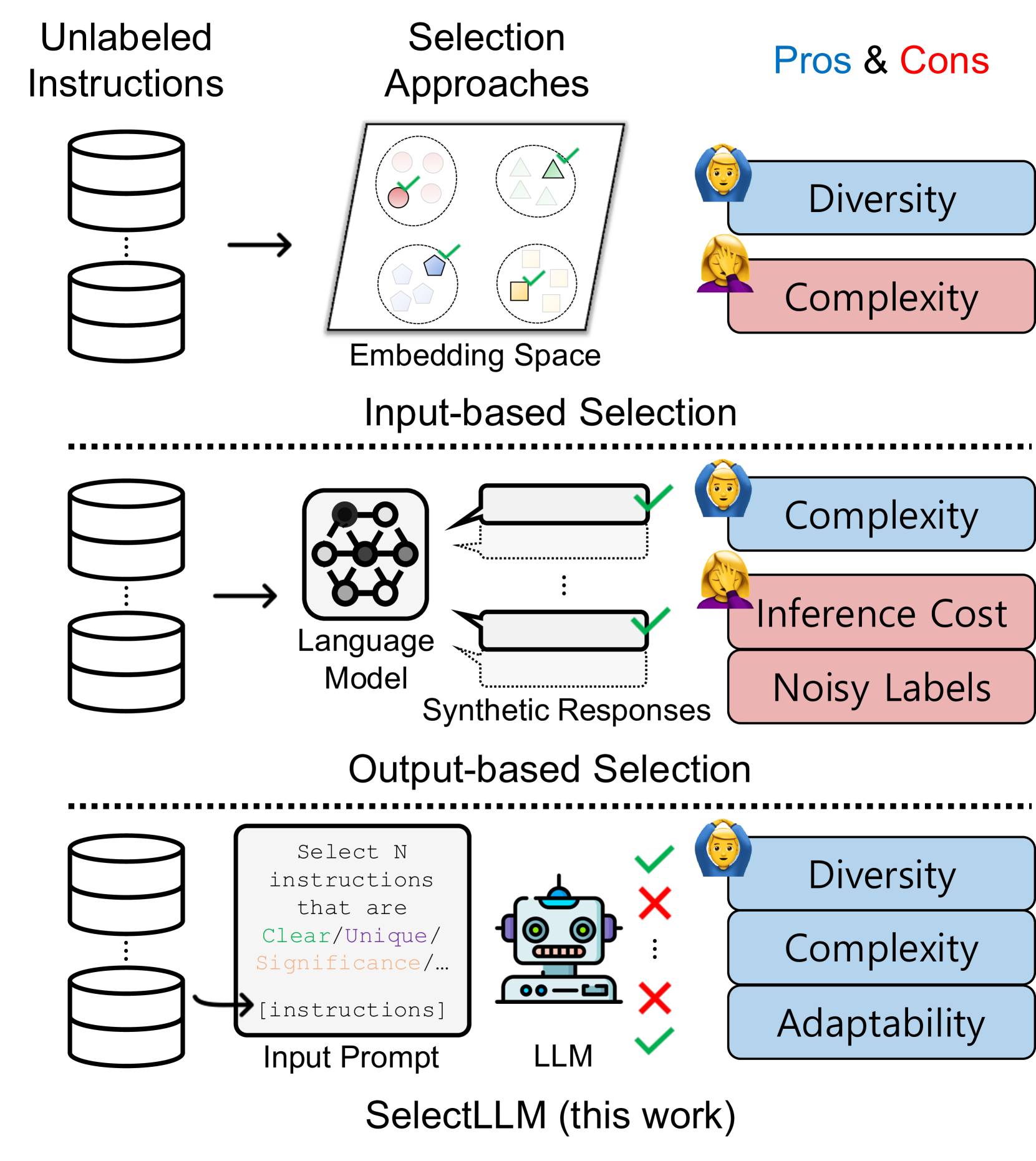
SelectLLM: Can LLMs Select Important Instructions to Annotate?
Ritik Sachin Parkar, Jaehyung Kim, Jong Inn Park, Dongyeop Kang
0
0
Instruction tuning benefits from large and diverse datasets, however creating such datasets involves a high cost of human labeling. While synthetic datasets generated by large language models (LLMs) have partly solved this issue, they often contain low-quality data. One effective solution is selectively annotating unlabelled instructions, especially given the relative ease of acquiring unlabeled instructions or texts from various sources. However, how to select unlabelled instructions is not well-explored, especially in the context of LLMs. Further, traditional data selection methods, relying on input embedding space density, tend to underestimate instruction sample complexity, whereas those based on model prediction uncertainty often struggle with synthetic label quality. Therefore, we introduce SelectLLM, an alternative framework that leverages the capabilities of LLMs to more effectively select unlabeled instructions. SelectLLM consists of two key steps: Coreset-based clustering of unlabelled instructions for diversity and then prompting a LLM to identify the most beneficial instructions within each cluster. Our experiments demonstrate that SelectLLM matches or outperforms other state-of-the-art methods in instruction tuning benchmarks. It exhibits remarkable consistency across human and synthetic datasets, along with better cross-dataset generalization, as evidenced by a 10% performance improvement on the Cleaned Alpaca test set when trained on Dolly data. All code and data are publicly available (https://github.com/minnesotanlp/select-llm).
4/19/2024

Hidden You Malicious Goal Into Benigh Narratives: Jailbreak Large Language Models through Logic Chain Injection
Zhilong Wang, Yebo Cao, Peng Liu
0
0
Jailbreak attacks on Language Model Models (LLMs) entail crafting prompts aimed at exploiting the models to generate malicious content. Existing jailbreak attacks can successfully deceive the LLMs, however they cannot deceive the human. This paper proposes a new type of jailbreak attacks which can deceive both the LLMs and human (i.e., security analyst). The key insight of our idea is borrowed from the social psychology - that is human are easily deceived if the lie is hidden in truth. Based on this insight, we proposed the logic-chain injection attacks to inject malicious intention into benign truth. Logic-chain injection attack firstly dissembles its malicious target into a chain of benign narrations, and then distribute narrations into a related benign article, with undoubted facts. In this way, newly generate prompt cannot only deceive the LLMs, but also deceive human.
4/9/2024