Bayesian Federated Model Compression for Communication and Computation Efficiency

0

Sign in to get full access
Overview
- This paper proposes a Bayesian federated model compression technique to improve communication and computation efficiency in federated learning.
- The approach leverages a sparse network structure and a Bayesian framework to enable selective parameter updates and reduce the amount of data transmitted between the server and clients.
- The authors conduct experiments on various benchmark datasets and compare their method to state-of-the-art federated learning techniques.
Plain English Explanation
In federated learning, multiple devices or clients collaborate to train a machine learning model without sharing their raw data. This is useful for preserving privacy and reducing the computational burden on individual devices. However, the communication overhead between the server and clients can become a bottleneck, especially for large models.
The authors of this paper introduce a new technique called Bayesian federated model compression to address this challenge. Their method uses a sparse network structure, where only a subset of the model parameters are updated during each round of federated training. This reduces the amount of data that needs to be transmitted between the server and clients, improving communication efficiency.
The sparse structure is determined using a Bayesian framework, which allows the model to automatically learn which parameters are important and should be updated, and which can be safely ignored. This selective parameter updating helps to also reduce the overall computational burden on the clients.
The authors evaluate their Bayesian federated model compression approach on several benchmark datasets and show that it outperforms other state-of-the-art federated learning techniques in terms of both communication and computation efficiency.
Technical Explanation
The key technical innovation in this paper is the use of a Bayesian framework to determine a sparse network structure for federated learning. Traditionally, federated learning updates all model parameters on each client, which can be inefficient for large models.
The authors propose to instead only update a subset of the parameters on each client, using a sparse network structure. This sparse structure is determined using a Bayesian prior that encourages many parameters to be set to zero, effectively pruning the network.
Specifically, the authors use a spike-and-slab prior to model the distributions of the model parameters. This prior encourages most parameters to be exactly zero (the "spike"), while allowing a small subset to have non-zero values (the "slab").
During the federated training process, the server maintains a global model with this sparse structure, and only sends the relevant non-zero parameters to each client. The clients then perform local updates on these parameters and send the updates back to the server, reducing the overall communication burden.
The authors demonstrate the effectiveness of their Bayesian federated model compression approach through experiments on various benchmark datasets, including image classification and language modeling tasks. They show significant improvements in both communication and computation efficiency compared to standard federated learning techniques, without sacrificing model performance.
Critical Analysis
The authors provide a thorough evaluation of their Bayesian federated model compression approach, including comparisons to state-of-the-art federated learning methods on multiple benchmark tasks. The results clearly demonstrate the benefits of their technique in terms of reducing communication and computation costs.
However, the paper does not address several important practical considerations. For example, the authors assume that the clients have homogeneous computational capabilities, which may not always be the case in real-world federated learning scenarios. Handling heterogeneity among clients is an important challenge that is not covered in this work.
Additionally, the paper does not discuss the implications of their method on model performance and generalization. While the results show that the compressed models can achieve similar accuracy to the full models, it would be useful to understand the tradeoffs in terms of model quality and how they might vary across different tasks and datasets.
Finally, the authors do not address potential privacy and security concerns that may arise from their Bayesian federated model compression approach. Preserving privacy is a critical aspect of federated learning, and the impact of the sparse structure and selective parameter updates on privacy should be carefully considered.
Conclusion
This paper presents a novel Bayesian federated model compression technique that demonstrates significant improvements in communication and computation efficiency for federated learning. By leveraging a sparse network structure and a Bayesian framework, the authors are able to selectively update only the most important model parameters, reducing the overhead of transmitting full model updates between the server and clients.
The experimental results on various benchmark tasks are promising and suggest that this approach could be valuable for a wide range of federated learning applications, especially those with constrained communication or computational resources. However, the authors should address the practical limitations and potential privacy concerns highlighted in the critical analysis to fully realize the benefits of their Bayesian federated model compression method.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bayesian Federated Model Compression for Communication and Computation Efficiency
Chengyu Xia, Danny H. K. Tsang, Vincent K. N. Lau
In this paper, we investigate Bayesian model compression in federated learning (FL) to construct sparse models that can achieve both communication and computation efficiencies. We propose a decentralized Turbo variational Bayesian inference (D-Turbo-VBI) FL framework where we firstly propose a hierarchical sparse prior to promote a clustered sparse structure in the weight matrix. Then, by carefully integrating message passing and VBI with a decentralized turbo framework, we propose the D-Turbo-VBI algorithm which can (i) reduce both upstream and downstream communication overhead during federated training, and (ii) reduce the computational complexity during local inference. Additionally, we establish the convergence property for thr proposed D-Turbo-VBI algorithm. Simulation results show the significant gain of our proposed algorithm over the baselines in reducing communication overhead during federated training and computational complexity of final model.
Read more4/12/2024

0
Compressed Bayesian Federated Learning for Reliable Passive Radio Sensing in Industrial IoT
Luca Barbieri, Stefano Savazzi, Monica Nicoli
Bayesian Federated Learning (FL) has been recently introduced to provide well-calibrated Machine Learning (ML) models quantifying the uncertainty of their predictions. Despite their advantages compared to frequentist FL setups, Bayesian FL tools implemented over decentralized networks are subject to high communication costs due to the iterated exchange of local posterior distributions among cooperating devices. Therefore, this paper proposes a communication-efficient decentralized Bayesian FL policy to reduce the communication overhead without sacrificing final learning accuracy and calibration. The proposed method integrates compression policies and allows devices to perform multiple optimization steps before sending the local posterior distributions. We integrate the developed tool in an Industrial Internet of Things (IIoT) use case where collaborating nodes equipped with autonomous radar sensors are tasked to reliably localize human operators in a workplace shared with robots. Numerical results show that the developed approach obtains highly accurate yet well-calibrated ML models compatible with the ones provided by conventional (uncompressed) Bayesian FL tools while substantially decreasing the communication overhead (i.e., up to 99%). Furthermore, the proposed approach is advantageous when compared with state-of-the-art compressed frequentist FL setups in terms of calibration, especially when the statistical distribution of the testing dataset changes.
Read more5/10/2024
0
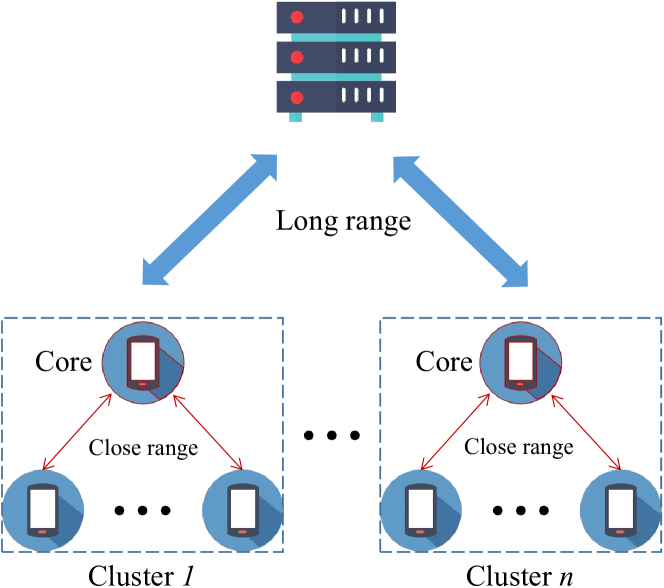
Efficient Model Compression for Hierarchical Federated Learning
Xi Zhu, Songcan Yu, Junbo Wang, Qinglin Yang
Federated learning (FL), as an emerging collaborative learning paradigm, has garnered significant attention due to its capacity to preserve privacy within distributed learning systems. In these systems, clients collaboratively train a unified neural network model using their local datasets and share model parameters rather than raw data, enhancing privacy. Predominantly, FL systems are designed for mobile and edge computing environments where training typically occurs over wireless networks. Consequently, as model sizes increase, the conventional FL frameworks increasingly consume substantial communication resources. To address this challenge and improve communication efficiency, this paper introduces a novel hierarchical FL framework that integrates the benefits of clustered FL and model compression. We present an adaptive clustering algorithm that identifies a core client and dynamically organizes clients into clusters. Furthermore, to enhance transmission efficiency, each core client implements a local aggregation with compression (LC aggregation) algorithm after collecting compressed models from other clients within the same cluster. Simulation results affirm that our proposed algorithms not only maintain comparable predictive accuracy but also significantly reduce energy consumption relative to existing FL mechanisms.
Read more5/29/2024
🚀
0
Communication-Efficient Federated Learning with Adaptive Compression under Dynamic Bandwidth
Ying Zhuansun, Dandan Li, Xiaohong Huang, Caijun Sun
Federated learning can train models without directly providing local data to the server. However, the frequent updating of the local model brings the problem of large communication overhead. Recently, scholars have achieved the communication efficiency of federated learning mainly by model compression. But they ignore two problems: 1) network state of each client changes dynamically; 2) network state among clients is not the same. The clients with poor bandwidth update local model slowly, which leads to low efficiency. To address this challenge, we propose a communication-efficient federated learning algorithm with adaptive compression under dynamic bandwidth (called AdapComFL). Concretely, each client performs bandwidth awareness and bandwidth prediction. Then, each client adaptively compresses its local model via the improved sketch mechanism based on his predicted bandwidth. Further, the server aggregates sketched models with different sizes received. To verify the effectiveness of the proposed method, the experiments are based on real bandwidth data which are collected from the network topology we build, and benchmark datasets which are obtained from open repositories. We show the performance of AdapComFL algorithm, and compare it with existing algorithms. The experimental results show that our AdapComFL achieves more efficient communication as well as competitive accuracy compared to existing algorithms.
Read more5/7/2024