Re-Thinking Inverse Graphics With Large Language Models

1
💬
Sign in to get full access
Overview
- Inverse graphics is the task of reconstructing the 3D scene and physical properties of objects in an image.
- Existing approaches to inverse graphics are limited in their ability to generalize across different domains.
- This paper proposes a novel framework called Inverse-Graphics Large Language Model (IG-LLM) that leverages the broad world knowledge encoded in large language models (LLMs) to solve inverse-graphics problems.
- The IG-LLM autoregressively decodes a visual embedding into a structured, compositional 3D-scene representation, without the use of image-space supervision.
Plain English Explanation
The paper explores a new way to reconstruct the 3D scene and physical properties of objects from a 2D image. This is a fundamental challenge in computer vision and graphics, known as "inverse graphics."
Existing approaches to this problem are limited in their ability to work across different types of images and scenes. The researchers were inspired by the impressive "zero-shot" generalization capabilities of large language models (LLMs) and wondered if they could use the broad knowledge encoded in these models to solve inverse-graphics problems more effectively.
The researchers propose a new framework called the Inverse-Graphics Large Language Model (IG-LLM). This system uses an LLM to autoregressively decode a visual embedding into a structured, 3D representation of the scene. Importantly, this is done without any direct supervision on the images themselves.
By leveraging the visual knowledge contained in LLMs, the IG-LLM framework opens up new possibilities for precise spatial reasoning about images, without requiring the carefully engineered approaches of previous methods.
Technical Explanation
The proposed Inverse-Graphics Large Language Model (IG-LLM) framework centers around a large language model that is tasked with autoregressively decoding a visual embedding into a structured, compositional 3D-scene representation.
The system incorporates a frozen pre-trained visual encoder and a continuous numeric head to enable end-to-end training. This allows the LLM to leverage the broad world knowledge encoded in its pre-training to solve inverse-graphics problems, without the need for direct image-space supervision.
Through their investigation, the researchers demonstrate the potential of LLMs to facilitate inverse graphics through next-token prediction. This contrasts with previous approaches that relied on carefully engineered solutions, which limited their ability to generalize across domains.
The IG-LLM framework opens up new possibilities for precise spatial reasoning about images by exploiting the visual knowledge of LLMs, as opposed to requiring the manual engineering of image-processing pipelines.
Critical Analysis
The paper presents a promising approach to leveraging the impressive generalization capabilities of large language models to solve inverse-graphics problems. However, the research is still in the early stages, and there are several caveats and limitations to consider.
One potential concern is the reliance on a frozen pre-trained visual encoder. While this allows the system to benefit from the visual knowledge encoded in the model, it may also limit the ability of the LLM to fully learn and adapt the visual representations to the specific inverse-graphics task. Further research could explore ways to allow the visual encoder to be fine-tuned as part of the end-to-end training process.
Additionally, the paper does not provide a detailed analysis of the computational efficiency and inference time of the IG-LLM framework, which could be an important consideration for real-world applications. Further research on efficient inference in large language models may help address this concern.
Overall, the IG-LLM framework represents an intriguing and innovative approach to inverse graphics, and the researchers have demonstrated its potential through their investigation. As the field continues to evolve, it will be important to further explore the capabilities and limitations of this approach, as well as compare it to other state-of-the-art methods in the domain.
Conclusion
This paper presents the Inverse-Graphics Large Language Model (IG-LLM), a novel framework that leverages the broad world knowledge encoded in large language models to solve inverse-graphics problems. By autoregressively decoding a visual embedding into a structured, 3D-scene representation, the IG-LLM opens up new possibilities for precise spatial reasoning about images without the need for image-space supervision.
The research represents an exciting step forward in the field of inverse graphics, demonstrating the potential of large language models to generalize across domains and facilitate the reconstruction of 3D scenes from 2D images. As the capabilities of these models continue to advance, further research on large language models for generative graph analytics may yield even more powerful tools for understanding and manipulating the physical world from visual inputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
1
Re-Thinking Inverse Graphics With Large Language Models
Peter Kulits, Haiwen Feng, Weiyang Liu, Victoria Abrevaya, Michael J. Black
Inverse graphics -- the task of inverting an image into physical variables that, when rendered, enable reproduction of the observed scene -- is a fundamental challenge in computer vision and graphics. Successfully disentangling an image into its constituent elements, such as the shape, color, and material properties of the objects of the 3D scene that produced it, requires a comprehensive understanding of the environment. This complexity limits the ability of existing carefully engineered approaches to generalize across domains. Inspired by the zero-shot ability of large language models (LLMs) to generalize to novel contexts, we investigate the possibility of leveraging the broad world knowledge encoded in such models to solve inverse-graphics problems. To this end, we propose the Inverse-Graphics Large Language Model (IG-LLM), an inverse-graphics framework centered around an LLM, that autoregressively decodes a visual embedding into a structured, compositional 3D-scene representation. We incorporate a frozen pre-trained visual encoder and a continuous numeric head to enable end-to-end training. Through our investigation, we demonstrate the potential of LLMs to facilitate inverse graphics through next-token prediction, without the application of image-space supervision. Our analysis enables new possibilities for precise spatial reasoning about images that exploit the visual knowledge of LLMs. We release our code and data at https://ig-llm.is.tue.mpg.de/ to ensure the reproducibility of our investigation and to facilitate future research.
Read more8/27/2024
💬
0
Leveraging Large Language Models for Scalable Vector Graphics-Driven Image Understanding
Mu Cai, Zeyi Huang, Yuheng Li, Utkarsh Ojha, Haohan Wang, Yong Jae Lee
Large language models (LLMs) have made significant advancements in natural language understanding. However, through that enormous semantic representation that the LLM has learnt, is it somehow possible for it to understand images as well? This work investigates this question. To enable the LLM to process images, we convert them into a representation given by Scalable Vector Graphics (SVG). To study what the LLM can do with this XML-based textual description of images, we test the LLM on three broad computer vision tasks: (i) visual reasoning and question answering, (ii) image classification under distribution shift, few-shot learning, and (iii) generating new images using visual prompting. Even though we do not naturally associate LLMs with any visual understanding capabilities, our results indicate that the LLM can often do a decent job in many of these tasks, potentially opening new avenues for research into LLMs' ability to understand image data. Our code, data, and models can be found here https://github.com/mu-cai/svg-llm.
Read more7/12/2024
0
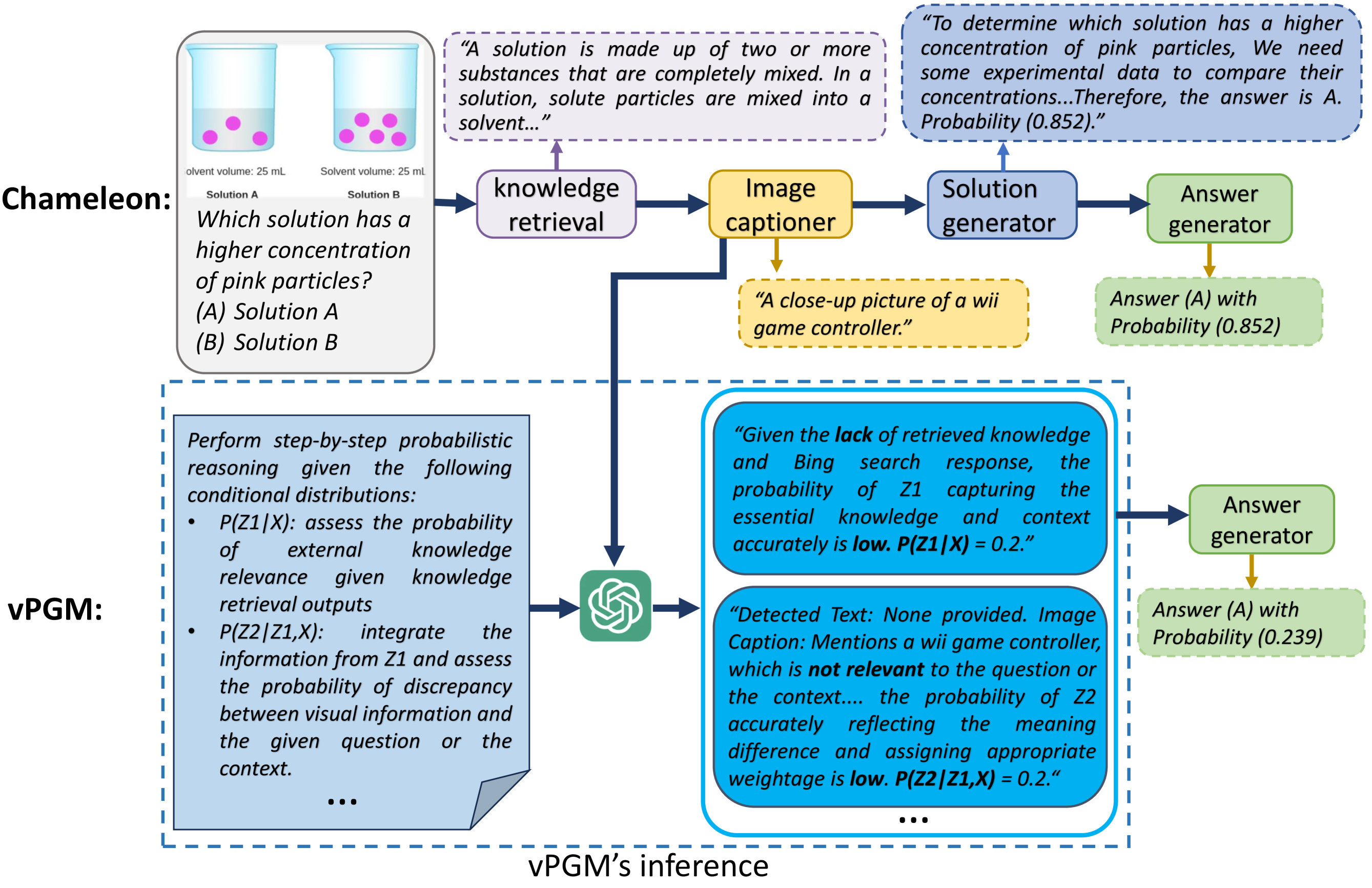
Verbalized Probabilistic Graphical Modeling with Large Language Models
Hengguan Huang, Xing Shen, Songtao Wang, Dianbo Liu, Hao Wang
Faced with complex problems, the human brain demonstrates a remarkable capacity to transcend sensory input and form latent understandings of perceived world patterns. However, this cognitive capacity is not explicitly considered or encoded in current large language models (LLMs). As a result, LLMs often struggle to capture latent structures and model uncertainty in complex compositional reasoning tasks. This work introduces a novel Bayesian prompting approach that facilitates training-free Bayesian inference with LLMs by using a verbalized Probabilistic Graphical Model (PGM). While traditional Bayesian approaches typically depend on extensive data and predetermined mathematical structures for learning latent factors and dependencies, our approach efficiently reasons latent variables and their probabilistic dependencies by prompting LLMs to adhere to Bayesian principles. We evaluated our model on several compositional reasoning tasks, both close-ended and open-ended. Our results indicate that the model effectively enhances confidence elicitation and text generation quality, demonstrating its potential to improve AI language understanding systems, especially in modeling uncertainty.
Read more6/11/2024
0
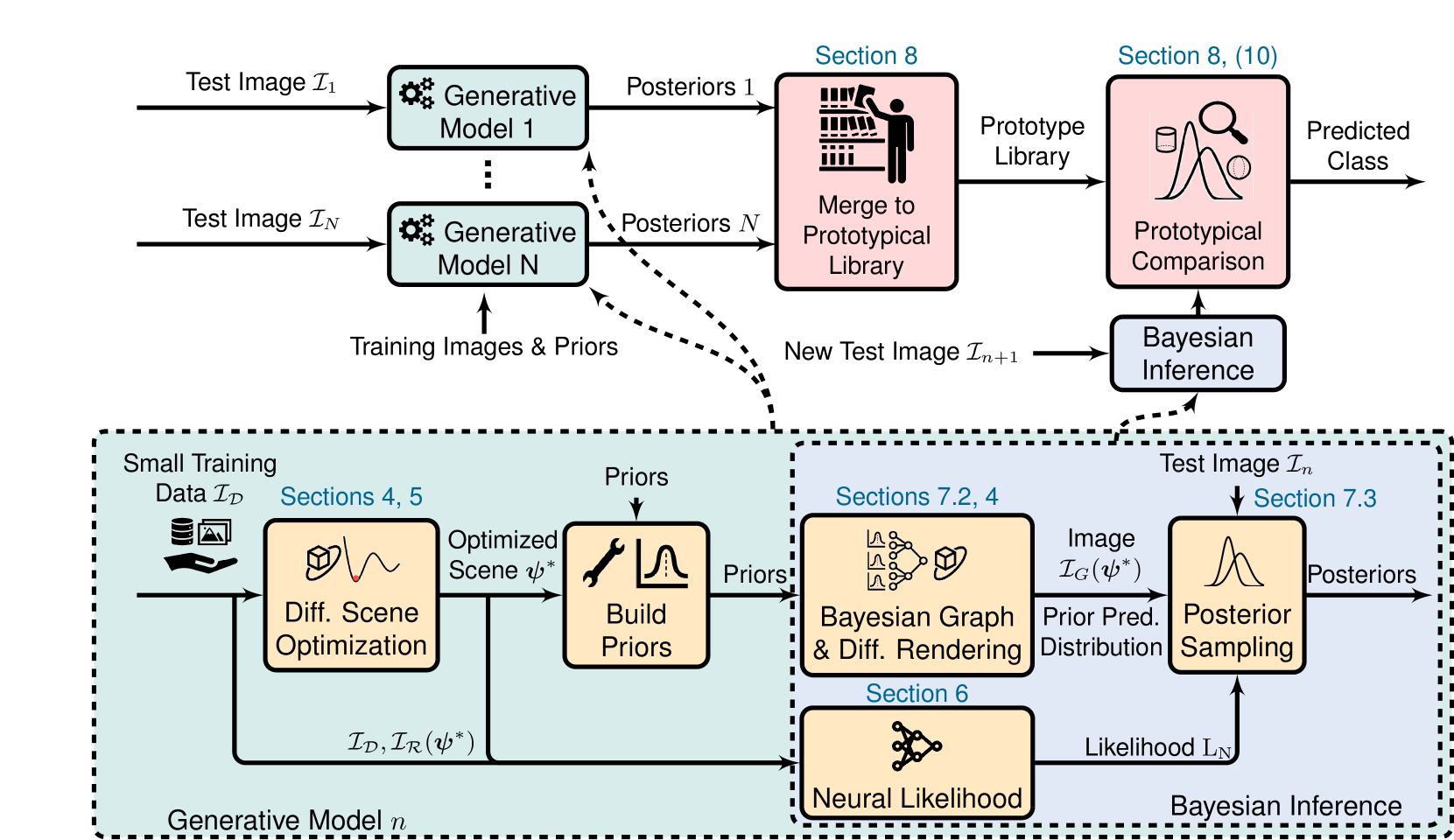
New!Bayesian Inverse Graphics for Few-Shot Concept Learning
Octavio Arriaga, Jichen Guo, Rebecca Adam, Sebastian Houben, Frank Kirchner
Humans excel at building generalizations of new concepts from just one single example. Contrary to this, current computer vision models typically require large amount of training samples to achieve a comparable accuracy. In this work we present a Bayesian model of perception that learns using only minimal data, a prototypical probabilistic program of an object. Specifically, we propose a generative inverse graphics model of primitive shapes, to infer posterior distributions over physically consistent parameters from one or several images. We show how this representation can be used for downstream tasks such as few-shot classification and pose estimation. Our model outperforms existing few-shot neural-only classification algorithms and demonstrates generalization across varying lighting conditions, backgrounds, and out-of-distribution shapes. By design, our model is uncertainty-aware and uses our new differentiable renderer for optimizing global scene parameters through gradient descent, sampling posterior distributions over object parameters with Markov Chain Monte Carlo (MCMC), and using a neural based likelihood function.
Read more9/16/2024