BEAR: A Unified Framework for Evaluating Relational Knowledge in Causal and Masked Language Models
2404.04113
0
0

Abstract
Knowledge probing assesses to which degree a language model (LM) has successfully learned relational knowledge during pre-training. Probing is an inexpensive way to compare LMs of different sizes and training configurations. However, previous approaches rely on the objective function used in pre-training LMs and are thus applicable only to masked or causal LMs. As a result, comparing different types of LMs becomes impossible. To address this, we propose an approach that uses an LM's inherent ability to estimate the log-likelihood of any given textual statement. We carefully design an evaluation dataset of 7,731 instances (40,916 in a larger variant) from which we produce alternative statements for each relational fact, one of which is correct. We then evaluate whether an LM correctly assigns the highest log-likelihood to the correct statement. Our experimental evaluation of 22 common LMs shows that our proposed framework, BEAR, can effectively probe for knowledge across different LM types. We release the BEAR datasets and an open-source framework that implements the probing approach to the research community to facilitate the evaluation and development of LMs.
Create account to get full access
Overview
- This paper introduces BEAR, a unified framework for evaluating the relational knowledge in both causal and masked language models.
- BEAR addresses limitations of existing evaluation methods like LAMA, which only focus on masked language models and fail to capture causal reasoning abilities.
- The paper presents experiments and analyses to showcase the benefits of BEAR over previous approaches.
Plain English Explanation
The paper discusses a new framework called BEAR (Bidirectional Evaluation of Relational Knowledge) for assessing the relational knowledge in different types of language models. Relational knowledge refers to the understanding of how different concepts and entities are connected.
Traditionally, methods like LAMA have been used to evaluate the relational knowledge in masked language models, which are models that can fill in missing words in a sentence. However, these methods are limited because they don't capture the causal reasoning abilities of language models, which are important for understanding how different things are related.
The BEAR framework proposed in this paper aims to provide a more comprehensive way to evaluate relational knowledge across both causal and masked language models. By doing this, the authors hope to get a better understanding of the strengths and limitations of different types of language models when it comes to reasoning about relationships between concepts.
The paper presents experimental results and analyses to demonstrate the advantages of the BEAR framework compared to previous evaluation approaches. This work is important for advancing our understanding of language models and how we can better assess their capabilities.
Technical Explanation
The paper introduces the BEAR (Bidirectional Evaluation of Relational Knowledge) framework, which provides a unified approach for evaluating the relational knowledge in both causal and masked language models.
Previous methods like LAMA have focused solely on masked language models, which are models that can fill in missing words in a sentence. However, these approaches fail to capture the causal reasoning abilities of language models, which are crucial for understanding how different concepts and entities are related.
BEAR addresses this limitation by evaluating relational knowledge in a bidirectional manner. It assesses a model's ability to predict missing information (as in LAMA) as well as its ability to reason about causal relationships between entities.
The paper presents experiments and analyses using BEAR on various language models, including GPT-3, T5, and BERT. The results demonstrate that BEAR provides a more comprehensive evaluation of relational knowledge compared to existing methods, as it can uncover strengths and weaknesses in both causal and masked reasoning abilities.
Furthermore, the paper discusses how BEAR can be used to track the evolution of relational knowledge in language models over time, as explored in related work like Unveiling LLMs' Evolution of Latent Representations. This is particularly relevant as language models continue to grow in size and capability.
Critical Analysis
The BEAR framework presented in this paper addresses important limitations of existing evaluation methods for relational knowledge in language models. By considering both causal and masked reasoning abilities, BEAR provides a more comprehensive assessment of a model's understanding of how different concepts are connected.
However, the paper acknowledges that BEAR is not a panacea and that there are still some caveats to consider. For example, the causal reasoning tasks used in BEAR may not fully capture the nuances of real-world causal relationships, and the framework may be biased towards certain types of relational knowledge.
Additionally, the paper does not delve into potential issues around the trustworthiness of language models or the challenges of evaluating multilingual language models. These are important considerations that could be explored in future research building on the BEAR framework.
Overall, the BEAR framework represents a significant step forward in the evaluation of relational knowledge in language models. By combining both causal and masked reasoning, it provides a more holistic view of a model's capabilities and limitations. However, as with any evaluation approach, it is important to remain cognizant of its potential biases and limitations when interpreting the results.
Conclusion
The BEAR framework introduced in this paper offers a unified approach for evaluating the relational knowledge in both causal and masked language models. By addressing the limitations of previous methods, BEAR provides a more comprehensive assessment of a model's understanding of how different concepts and entities are connected.
The experimental results and analyses presented in the paper demonstrate the advantages of BEAR over existing evaluation approaches. This work is an important contribution to the field, as it can help researchers and practitioners better understand the strengths and weaknesses of different language models, particularly when it comes to reasoning about real-world relationships.
As language models continue to evolve and grow in capability, the BEAR framework can serve as a valuable tool for tracking the development of relational knowledge over time. This information can inform the design of more robust and trustworthy language models that can better support a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
What Matters in Learning Facts in Language Models? Multifaceted Knowledge Probing with Diverse Multi-Prompt Datasets
Xin Zhao, Naoki Yoshinaga, Daisuke Oba
0
0
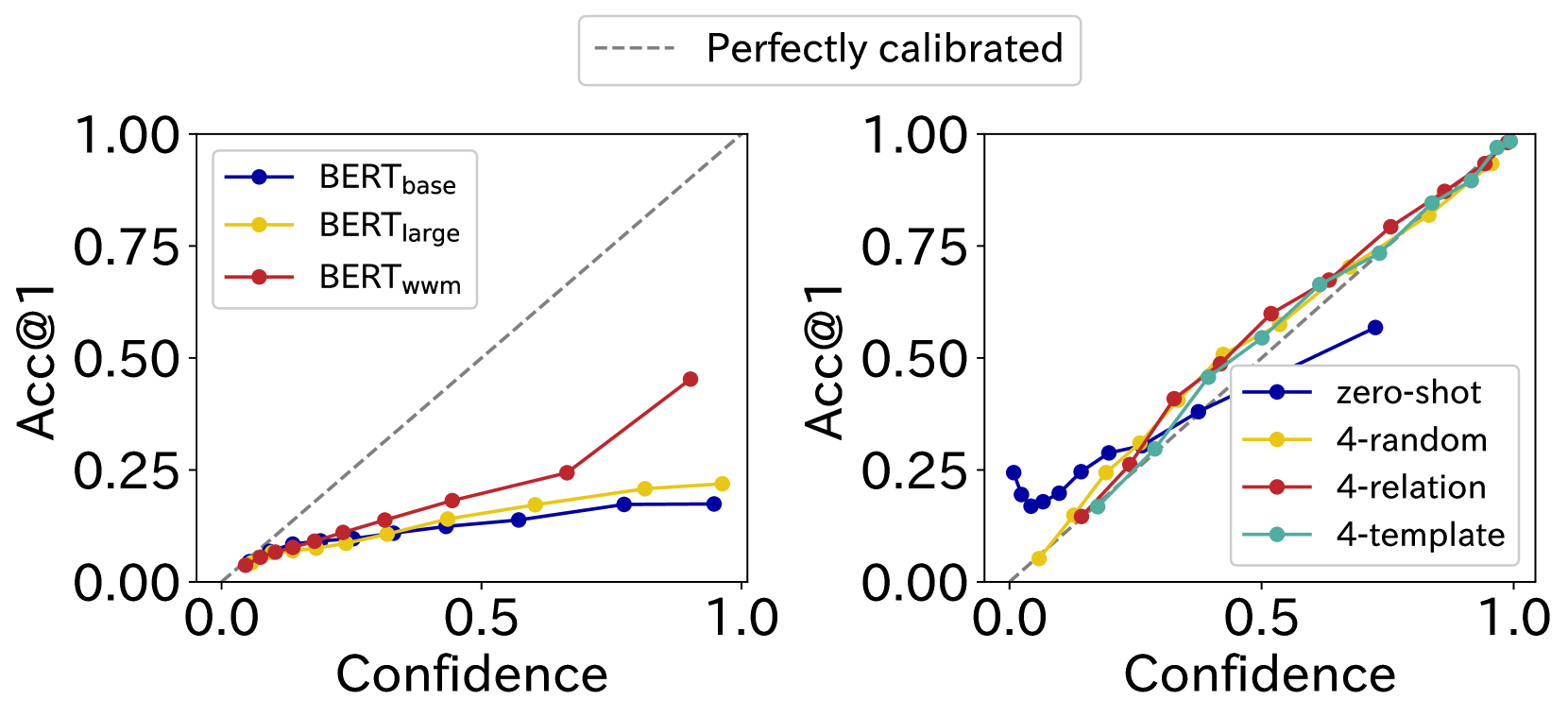
Large language models (LLMs) face issues in handling factual knowledge, making it vital to evaluate their true ability to understand facts. In this study, we introduce knowledge probing frameworks, BELIEF(-ICL), to evaluate the knowledge understanding ability of not only encoder-based PLMs but also decoder-based PLMs from diverse perspectives. BELIEFs utilize a multi-prompt dataset to evaluate PLM's accuracy, consistency, and reliability in factual knowledge understanding. To provide a more reliable evaluation with BELIEFs, we semi-automatically create MyriadLAMA, which has more diverse prompts than existing datasets. We validate the effectiveness of BELIEFs in correctly and comprehensively evaluating PLM's factual understanding ability through extensive evaluations. We further investigate key factors in learning facts in LLMs, and reveal the limitation of the prompt-based knowledge probing. The dataset is anonymously publicized.
6/19/2024

CausalBench: A Comprehensive Benchmark for Causal Learning Capability of Large Language Models
Yu Zhou, Xingyu Wu, Beicheng Huang, Jibin Wu, Liang Feng, Kay Chen Tan
0
0
Causality reveals fundamental principles behind data distributions in real-world scenarios, and the capability of large language models (LLMs) to understand causality directly impacts their efficacy across explaining outputs, adapting to new evidence, and generating counterfactuals. With the proliferation of LLMs, the evaluation of this capacity is increasingly garnering attention. However, the absence of a comprehensive benchmark has rendered existing evaluation studies being straightforward, undiversified, and homogeneous. To address these challenges, this paper proposes a comprehensive benchmark, namely CausalBench, to evaluate the causality understanding capabilities of LLMs. Originating from the causal research community, CausalBench encompasses three causal learning-related tasks, which facilitate a convenient comparison of LLMs' performance with classic causal learning algorithms. Meanwhile, causal networks of varying scales and densities are integrated in CausalBench, to explore the upper limits of LLMs' capabilities across task scenarios of varying difficulty. Notably, background knowledge and structured data are also incorporated into CausalBench to thoroughly unlock the underlying potential of LLMs for long-text comprehension and prior information utilization. Based on CausalBench, this paper evaluates nineteen leading LLMs and unveils insightful conclusions in diverse aspects. Firstly, we present the strengths and weaknesses of LLMs and quantitatively explore the upper limits of their capabilities across various scenarios. Meanwhile, we further discern the adaptability and abilities of LLMs to specific structural networks and complex chain of thought structures. Moreover, this paper quantitatively presents the differences across diverse information sources and uncovers the gap between LLMs' capabilities in causal understanding within textual contexts and numerical domains.
4/10/2024
💬
Causal Evaluation of Language Models
Sirui Chen, Bo Peng, Meiqi Chen, Ruiqi Wang, Mengying Xu, Xingyu Zeng, Rui Zhao, Shengjie Zhao, Yu Qiao, Chaochao Lu
0
0
Causal reasoning is viewed as crucial for achieving human-level machine intelligence. Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning. In this work, we introduce Causal evaluation of Language Models (CaLM), which, to the best of our knowledge, is the first comprehensive benchmark for evaluating the causal reasoning capabilities of language models. First, we propose the CaLM framework, which establishes a foundational taxonomy consisting of four modules: causal target (i.e., what to evaluate), adaptation (i.e., how to obtain the results), metric (i.e., how to measure the results), and error (i.e., how to analyze the bad results). This taxonomy defines a broad evaluation design space while systematically selecting criteria and priorities. Second, we compose the CaLM dataset, comprising 126,334 data samples, to provide curated sets of causal targets, adaptations, metrics, and errors, offering extensive coverage for diverse research pursuits. Third, we conduct an extensive evaluation of 28 leading language models on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types. Fourth, we perform detailed analyses of the evaluation results across various dimensions (e.g., adaptation, scale). Fifth, we present 50 high-level empirical findings across 9 dimensions (e.g., model), providing valuable guidance for future language model development. Finally, we develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support scalable and adaptable assessments. We envision CaLM as an ever-evolving benchmark for the community, systematically updated with new causal targets, adaptations, models, metrics, and error types to reflect ongoing research advancements. Project website is at https://opencausalab.github.io/CaLM.
5/2/2024
TruthEval: A Dataset to Evaluate LLM Truthfulness and Reliability
Aisha Khatun, Daniel G. Brown
0
0
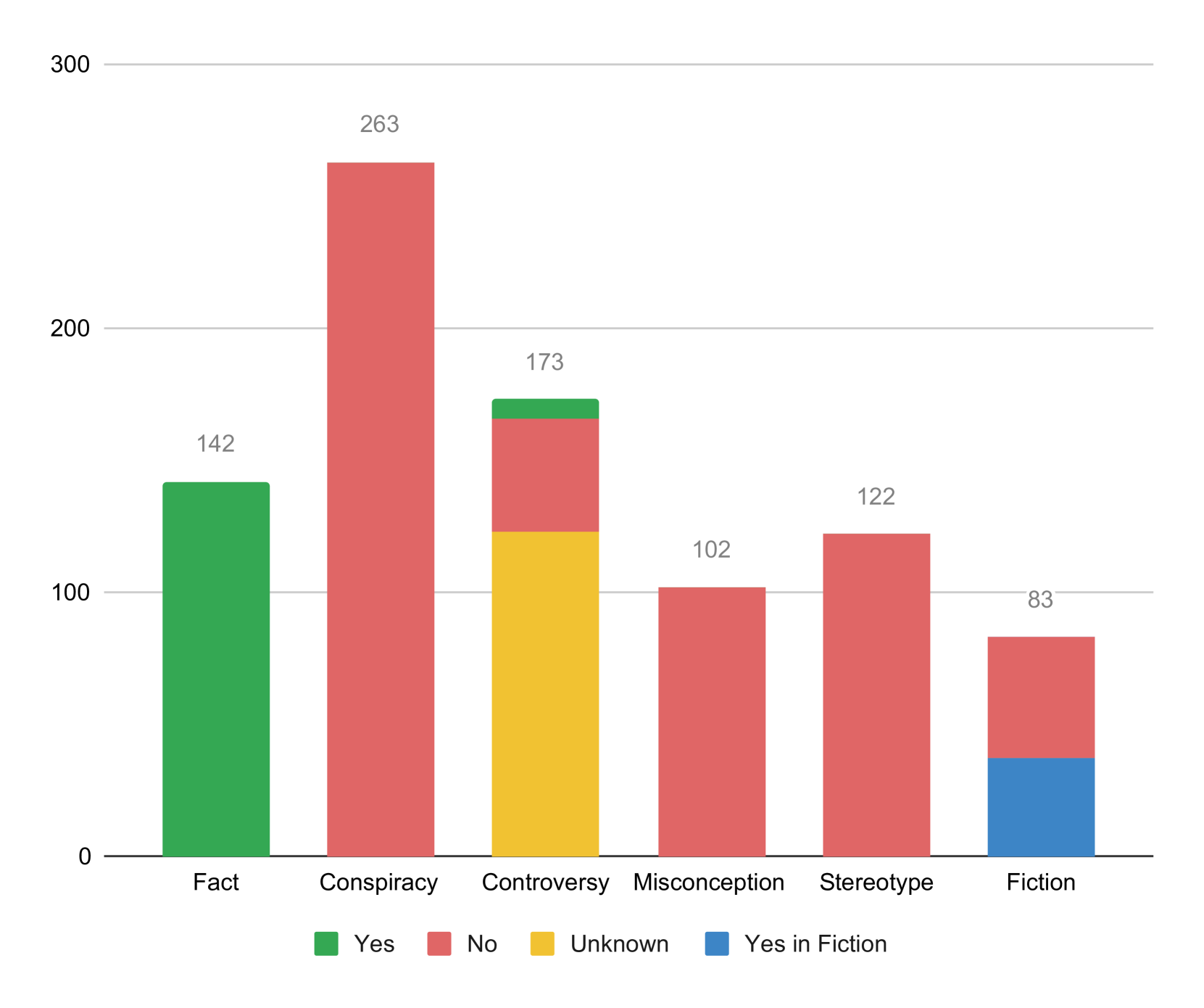
Large Language Model (LLM) evaluation is currently one of the most important areas of research, with existing benchmarks proving to be insufficient and not completely representative of LLMs' various capabilities. We present a curated collection of challenging statements on sensitive topics for LLM benchmarking called TruthEval. These statements were curated by hand and contain known truth values. The categories were chosen to distinguish LLMs' abilities from their stochastic nature. We perform some initial analyses using this dataset and find several instances of LLMs failing in simple tasks showing their inability to understand simple questions.
6/5/2024