Causal Evaluation of Language Models
2405.00622
0
0
💬
Abstract
Causal reasoning is viewed as crucial for achieving human-level machine intelligence. Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning. In this work, we introduce Causal evaluation of Language Models (CaLM), which, to the best of our knowledge, is the first comprehensive benchmark for evaluating the causal reasoning capabilities of language models. First, we propose the CaLM framework, which establishes a foundational taxonomy consisting of four modules: causal target (i.e., what to evaluate), adaptation (i.e., how to obtain the results), metric (i.e., how to measure the results), and error (i.e., how to analyze the bad results). This taxonomy defines a broad evaluation design space while systematically selecting criteria and priorities. Second, we compose the CaLM dataset, comprising 126,334 data samples, to provide curated sets of causal targets, adaptations, metrics, and errors, offering extensive coverage for diverse research pursuits. Third, we conduct an extensive evaluation of 28 leading language models on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types. Fourth, we perform detailed analyses of the evaluation results across various dimensions (e.g., adaptation, scale). Fifth, we present 50 high-level empirical findings across 9 dimensions (e.g., model), providing valuable guidance for future language model development. Finally, we develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support scalable and adaptable assessments. We envision CaLM as an ever-evolving benchmark for the community, systematically updated with new causal targets, adaptations, models, metrics, and error types to reflect ongoing research advancements. Project website is at https://opencausalab.github.io/CaLM.
Create account to get full access
Overview
- This paper introduces a new benchmark called Causal evaluation of Language Models (CaLM) to assess the causal reasoning capabilities of large language models (LLMs).
- The CaLM framework establishes a taxonomy for evaluating causal reasoning, including causal targets, adaptations, metrics, and error types.
- The authors curate a dataset of over 126,000 samples to cover a wide range of causal reasoning tasks and evaluate 28 leading LLMs on a core set of 92 causal targets.
- The extensive evaluation results provide valuable insights into the current state of causal reasoning in LLMs and guide future research and development.
- The authors also develop an open-source platform to support ongoing assessments and advancements in this area.
Plain English Explanation
The paper explores the ability of large language models (LLMs) - the powerful AI systems that can generate human-like text - to engage in causal reasoning. Causal reasoning is the capacity to understand how different factors influence each other and make inferences about cause-and-effect relationships. This skill is seen as crucial for achieving human-level machine intelligence, as it underpins our ability to make sense of the world and make decisions.
The researchers introduce a new benchmark called CaLM (Causal evaluation of Language Models) to systematically assess the causal reasoning capabilities of LLMs. The CaLM framework lays out a clear structure for evaluating these models, including defining what to evaluate (causal targets), how to obtain the results (adaptations), how to measure the results (metrics), and how to analyze errors. This comprehensive approach allows for a thorough and consistent assessment of LLMs' causal reasoning abilities.
To support this evaluation, the authors compile a large dataset of over 126,000 samples that cover a diverse range of causal reasoning tasks. They then test 28 leading LLMs on a core set of 92 causal targets, using various adaptations, metrics, and error analysis techniques. The results of this extensive evaluation provide valuable insights into the current state of causal reasoning in these models and guide future research and development efforts.
For example, the researchers find that while LLMs can perform well on some causal reasoning tasks, they often struggle with more complex or contextual causal relationships. The models also tend to exhibit certain systematic biases and errors that need to be addressed. By sharing these findings, the researchers hope to spur further advancements in improving the causal reasoning capabilities of LLMs and evaluating their reasoning behavior more broadly.
The authors also develop an open-source platform, including a website, datasets, and toolkits, to support ongoing research and assessments in this area. This will help the research community to build on the CaLM benchmark and continue to push the boundaries of causal reasoning in artificial intelligence.
Technical Explanation
The paper introduces a new benchmark called Causal evaluation of Language Models (CaLM) to systematically assess the causal reasoning capabilities of large language models (LLMs). The CaLM framework establishes a foundational taxonomy that defines four key elements: causal targets (what to evaluate), adaptations (how to obtain the results), metrics (how to measure the results), and error types (how to analyze the bad results). This comprehensive approach allows for a broad and systematic evaluation of causal reasoning in LLMs.
To support this evaluation, the authors curate a dataset of 126,334 data samples that provide diverse sets of causal targets, adaptations, metrics, and error types. They then conduct an extensive evaluation of 28 leading LLMs on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types.
The evaluation results provide detailed insights across various dimensions, such as model scale, adaptation, and error types. For example, the researchers find that while LLMs can perform well on some causal reasoning tasks, they often struggle with more complex or contextual causal relationships. The models also tend to exhibit certain systematic biases and errors, such as confusing correlation with causation or failing to consider alternative explanations.
Based on these findings, the authors present 50 high-level empirical insights across 9 dimensions, offering valuable guidance for future LLM development. They also develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support ongoing and adaptable assessments of causal reasoning in LLMs.
Critical Analysis
The CaLM benchmark represents a significant and much-needed advancement in the evaluation of causal reasoning capabilities in large language models. By establishing a comprehensive taxonomy and curating a diverse dataset, the researchers have created a robust framework for systematically assessing these important cognitive skills.
However, the paper does acknowledge some limitations of the current CaLM evaluation. For example, the dataset, while extensive, may not fully capture the breadth and complexity of real-world causal reasoning tasks. Additionally, the evaluation is focused on language models, and the researchers note the need to extend the benchmark to other AI systems that may exhibit causal reasoning abilities.
Furthermore, while the evaluation results provide valuable insights, the authors do not delve too deeply into the underlying causes of the models' difficulties with certain causal reasoning tasks. Additional research and analysis may be needed to better understand the specific cognitive and architectural limitations that lead to these shortcomings.
Despite these caveats, the CaLM benchmark represents a significant step forward in the field of causal reasoning in artificial intelligence. By providing a rigorous and adaptable evaluation framework, the researchers have laid the groundwork for continued progress and the development of more causally-aware and cognitively-advanced language models. Ultimately, this research has the potential to enhance our understanding of human-level intelligence and drive the field of AI towards more robust and human-like reasoning capabilities.
Conclusion
The paper introduces the CaLM benchmark, a comprehensive framework for evaluating the causal reasoning capabilities of large language models. By establishing a clear taxonomy and curating a diverse dataset, the researchers have created a robust tool for assessing these crucial cognitive skills.
The extensive evaluation of 28 leading LLMs provides valuable insights into the current state of causal reasoning in these models, highlighting both their strengths and limitations. The findings offer guidance for future research and development efforts aimed at enhancing the causal reasoning capabilities of language models and other AI systems.
The open-source platform developed by the authors, including a website, datasets, and toolkits, will further support the research community in building upon the CaLM benchmark and advancing the field of causal reasoning in artificial intelligence. As the field continues to evolve, this work represents a significant step towards the ultimate goal of achieving human-level machine intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CausalBench: A Comprehensive Benchmark for Causal Learning Capability of Large Language Models
Yu Zhou, Xingyu Wu, Beicheng Huang, Jibin Wu, Liang Feng, Kay Chen Tan
0
0
Causality reveals fundamental principles behind data distributions in real-world scenarios, and the capability of large language models (LLMs) to understand causality directly impacts their efficacy across explaining outputs, adapting to new evidence, and generating counterfactuals. With the proliferation of LLMs, the evaluation of this capacity is increasingly garnering attention. However, the absence of a comprehensive benchmark has rendered existing evaluation studies being straightforward, undiversified, and homogeneous. To address these challenges, this paper proposes a comprehensive benchmark, namely CausalBench, to evaluate the causality understanding capabilities of LLMs. Originating from the causal research community, CausalBench encompasses three causal learning-related tasks, which facilitate a convenient comparison of LLMs' performance with classic causal learning algorithms. Meanwhile, causal networks of varying scales and densities are integrated in CausalBench, to explore the upper limits of LLMs' capabilities across task scenarios of varying difficulty. Notably, background knowledge and structured data are also incorporated into CausalBench to thoroughly unlock the underlying potential of LLMs for long-text comprehension and prior information utilization. Based on CausalBench, this paper evaluates nineteen leading LLMs and unveils insightful conclusions in diverse aspects. Firstly, we present the strengths and weaknesses of LLMs and quantitatively explore the upper limits of their capabilities across various scenarios. Meanwhile, we further discern the adaptability and abilities of LLMs to specific structural networks and complex chain of thought structures. Moreover, this paper quantitatively presents the differences across diverse information sources and uncovers the gap between LLMs' capabilities in causal understanding within textual contexts and numerical domains.
4/10/2024
Cause and Effect: Can Large Language Models Truly Understand Causality?
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Mayank Jindal, Dushyant Singh Sengar, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, Aman Chadha
0
0
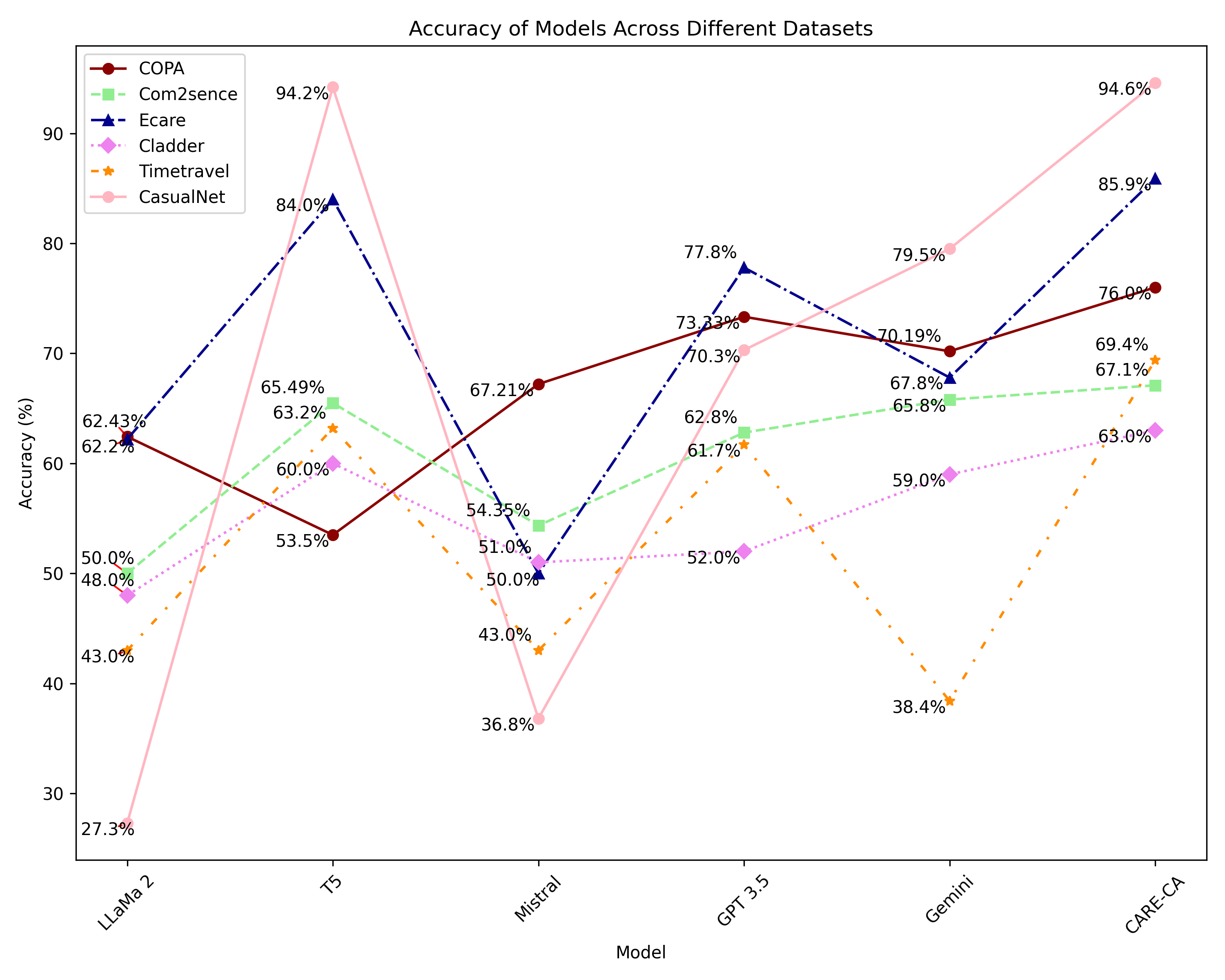
With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
4/17/2024

CELLO: Causal Evaluation of Large Vision-Language Models
Meiqi Chen, Bo Peng, Yan Zhang, Chaochao Lu
0
0
Causal reasoning is fundamental to human intelligence and crucial for effective decision-making in real-world environments. Despite recent advancements in large vision-language models (LVLMs), their ability to comprehend causality remains unclear. Previous work typically focuses on commonsense causality between events and/or actions, which is insufficient for applications like embodied agents and lacks the explicitly defined causal graphs required for formal causal reasoning. To overcome these limitations, we introduce a fine-grained and unified definition of causality involving interactions between humans and/or objects. Building on the definition, we construct a novel dataset, CELLO, consisting of 14,094 causal questions across all four levels of causality: discovery, association, intervention, and counterfactual. This dataset surpasses traditional commonsense causality by including explicit causal graphs that detail the interactions between humans and objects. Extensive experiments on CELLO reveal that current LVLMs still struggle with causal reasoning tasks, but they can benefit significantly from our proposed CELLO-CoT, a causally inspired chain-of-thought prompting strategy. Both quantitative and qualitative analyses from this study provide valuable insights for future research. Our project page is at https://github.com/OpenCausaLab/CELLO.
6/28/2024
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
0
0
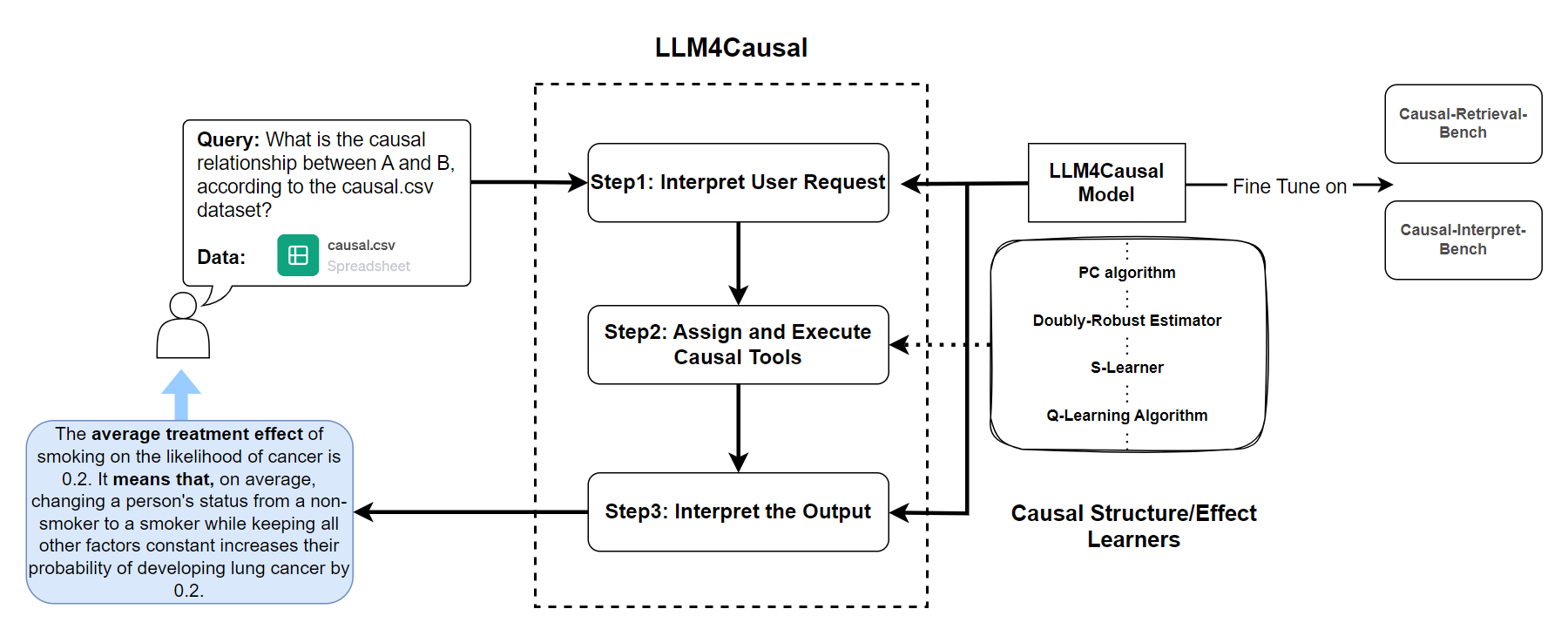
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
4/15/2024