CausalBench: A Comprehensive Benchmark for Causal Learning Capability of Large Language Models
2404.06349
0
0

Abstract
Causality reveals fundamental principles behind data distributions in real-world scenarios, and the capability of large language models (LLMs) to understand causality directly impacts their efficacy across explaining outputs, adapting to new evidence, and generating counterfactuals. With the proliferation of LLMs, the evaluation of this capacity is increasingly garnering attention. However, the absence of a comprehensive benchmark has rendered existing evaluation studies being straightforward, undiversified, and homogeneous. To address these challenges, this paper proposes a comprehensive benchmark, namely CausalBench, to evaluate the causality understanding capabilities of LLMs. Originating from the causal research community, CausalBench encompasses three causal learning-related tasks, which facilitate a convenient comparison of LLMs' performance with classic causal learning algorithms. Meanwhile, causal networks of varying scales and densities are integrated in CausalBench, to explore the upper limits of LLMs' capabilities across task scenarios of varying difficulty. Notably, background knowledge and structured data are also incorporated into CausalBench to thoroughly unlock the underlying potential of LLMs for long-text comprehension and prior information utilization. Based on CausalBench, this paper evaluates nineteen leading LLMs and unveils insightful conclusions in diverse aspects. Firstly, we present the strengths and weaknesses of LLMs and quantitatively explore the upper limits of their capabilities across various scenarios. Meanwhile, we further discern the adaptability and abilities of LLMs to specific structural networks and complex chain of thought structures. Moreover, this paper quantitatively presents the differences across diverse information sources and uncovers the gap between LLMs' capabilities in causal understanding within textual contexts and numerical domains.
Create account to get full access
Overview
- This paper introduces CausalBench, a comprehensive benchmark for evaluating the causal learning capabilities of large language models (LLMs).
- CausalBench consists of a diverse set of tasks that test an LLM's ability to understand and reason about causal relationships, going beyond just correlational patterns.
- The benchmark aims to provide a more thorough assessment of an LLM's causal reasoning abilities compared to existing benchmarks.
Plain English Explanation
The paper discusses the development of a new benchmark called CausalBench, which is designed to test the causal learning capabilities of large language models (LLMs). Causal reasoning is an important skill for AI systems, as it allows them to understand the underlying relationships between different elements, rather than just recognizing patterns.
CausalBench: A Comprehensive Benchmark for Causal Learning Capability of Large Language Models presents a suite of tasks that assess an LLM's ability to reason about causal structures, make predictions based on interventions, and identify confounding factors. This is a more comprehensive approach compared to existing benchmarks, which tend to focus more on correlational patterns.
By testing LLMs on a diverse set of causal reasoning tasks, the researchers aim to gain a better understanding of the models' strengths and weaknesses in this area. This could help guide the development of more capable and reliable AI systems that can better understand and reason about the real-world causal relationships that underlie the data they are trained on.
Technical Explanation
The paper introduces CausalBench, a new benchmark designed to evaluate the causal learning capabilities of large language models (LLMs). Unlike many existing benchmarks that focus primarily on correlational patterns, CausalBench consists of a diverse set of tasks that test an LLM's ability to understand and reason about causal relationships.
The benchmark includes tasks that assess an LLM's ability to:
- Identify causal structures from observational data
- Make predictions based on interventions in a causal system
- Recognize and mitigate the effects of confounding factors
The tasks cover a range of domains, including natural language, numerical reasoning, and visual reasoning, to provide a comprehensive evaluation of an LLM's causal learning capabilities.
The researchers evaluate several state-of-the-art LLMs on the CausalBench tasks and find that while the models exhibit some causal reasoning abilities, there is still significant room for improvement. The results highlight the need for further advancements in causal learning within the field of large language models.
Evaluating Interventional Reasoning Capabilities of Large Language Models, Quantifying and Mitigating Unimodal Biases in Multimodal Large Language Models, and XLDOLLAR2DOLLARBENCH: A Benchmark for Extremely Long-Context Understanding for Long-Form Question Answering are some related works that also explore the capabilities and limitations of large language models in various domains.
Critical Analysis
The CausalBench benchmark represents a valuable contribution to the field of causal learning and its assessment in large language models. By focusing on causal reasoning, rather than just correlational patterns, the benchmark provides a more comprehensive evaluation of an LLM's understanding of real-world relationships.
However, the paper does acknowledge some limitations of the current version of CausalBench. For example, the tasks may not fully capture the complexity of causal reasoning in real-world scenarios, and the benchmark may not be able to distinguish between different causal learning approaches employed by LLMs.
Additionally, the paper does not explore the potential biases or limitations of the LLMs themselves, which could impact their performance on the causal reasoning tasks. Further research may be needed to understand how these models handle causal reasoning under different conditions or in the presence of confounding factors.
BEAR: A Unified Framework for Evaluating Relational Knowledge and Causal Reasoning Capabilities of Large Language Models and VisualWebBench: How Far Have Multimodal Large Language Models Evolved? are two other relevant papers that explore the causal reasoning and relational understanding capabilities of large language models, which could provide additional insights.
Conclusion
The CausalBench benchmark represents an important step forward in the evaluation of causal learning capabilities within large language models. By moving beyond simple correlational patterns, the benchmark provides a more comprehensive assessment of an LLM's ability to understand and reason about real-world causal relationships.
The results of the study highlight the current limitations of LLMs in causal reasoning and underscore the need for further advancements in this area. As large language models continue to play an increasingly important role in various applications, the ability to reason about causal structures will become increasingly crucial for developing reliable and trustworthy AI systems.
The CausalBench benchmark paves the way for more nuanced and rigorous evaluations of causal learning capabilities, which can help guide the development of more capable and robust large language models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Cause and Effect: Can Large Language Models Truly Understand Causality?
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Mayank Jindal, Dushyant Singh Sengar, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, Aman Chadha
0
0
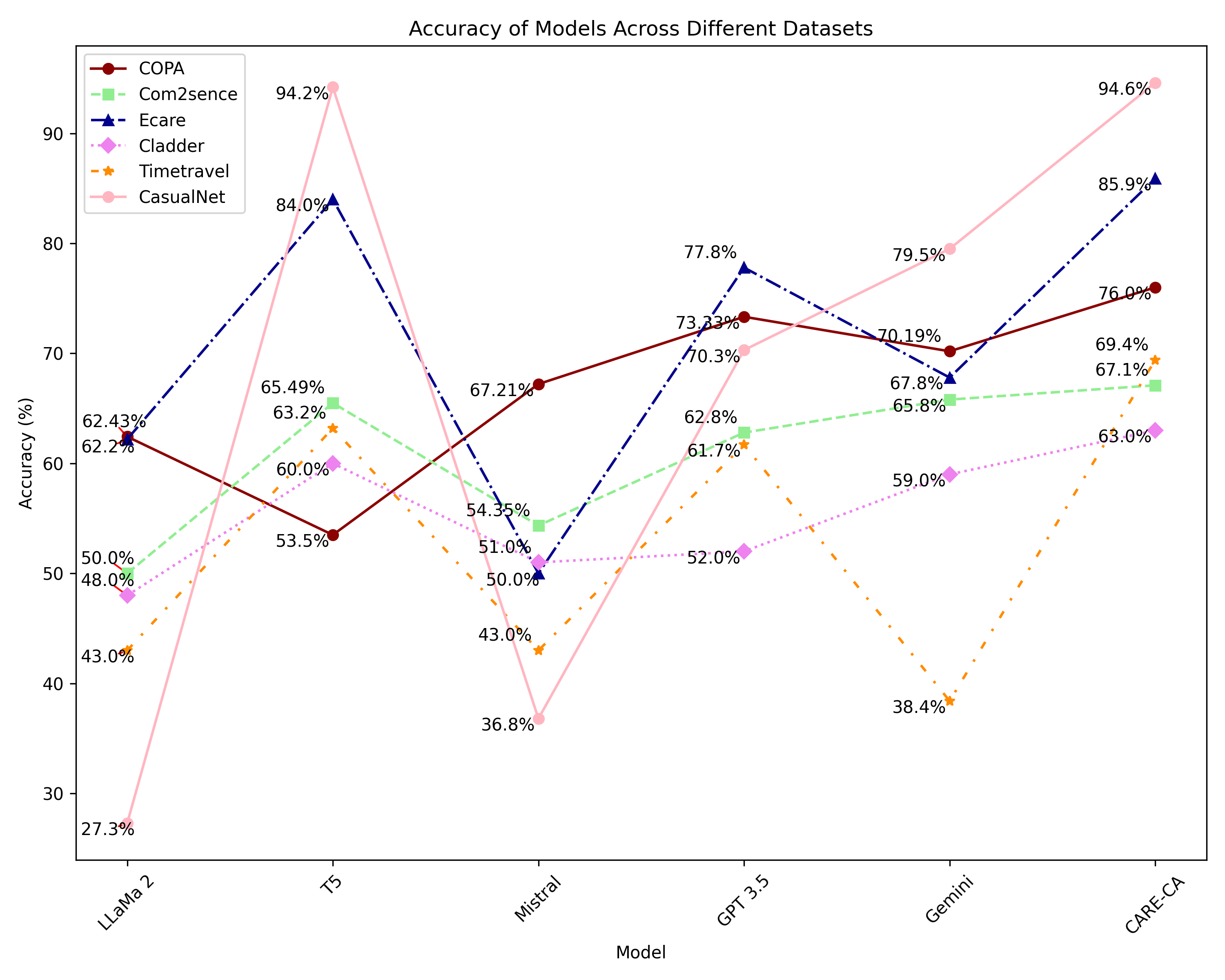
With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
4/17/2024
💬
Causal Evaluation of Language Models
Sirui Chen, Bo Peng, Meiqi Chen, Ruiqi Wang, Mengying Xu, Xingyu Zeng, Rui Zhao, Shengjie Zhao, Yu Qiao, Chaochao Lu
0
0
Causal reasoning is viewed as crucial for achieving human-level machine intelligence. Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning. In this work, we introduce Causal evaluation of Language Models (CaLM), which, to the best of our knowledge, is the first comprehensive benchmark for evaluating the causal reasoning capabilities of language models. First, we propose the CaLM framework, which establishes a foundational taxonomy consisting of four modules: causal target (i.e., what to evaluate), adaptation (i.e., how to obtain the results), metric (i.e., how to measure the results), and error (i.e., how to analyze the bad results). This taxonomy defines a broad evaluation design space while systematically selecting criteria and priorities. Second, we compose the CaLM dataset, comprising 126,334 data samples, to provide curated sets of causal targets, adaptations, metrics, and errors, offering extensive coverage for diverse research pursuits. Third, we conduct an extensive evaluation of 28 leading language models on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types. Fourth, we perform detailed analyses of the evaluation results across various dimensions (e.g., adaptation, scale). Fifth, we present 50 high-level empirical findings across 9 dimensions (e.g., model), providing valuable guidance for future language model development. Finally, we develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support scalable and adaptable assessments. We envision CaLM as an ever-evolving benchmark for the community, systematically updated with new causal targets, adaptations, models, metrics, and error types to reflect ongoing research advancements. Project website is at https://opencausalab.github.io/CaLM.
5/2/2024

OCDB: Revisiting Causal Discovery with a Comprehensive Benchmark and Evaluation Framework
Wei Zhou, Hong Huang, Guowen Zhang, Ruize Shi, Kehan Yin, Yuanyuan Lin, Bang Liu
0
0
Large language models (LLMs) have excelled in various natural language processing tasks, but challenges in interpretability and trustworthiness persist, limiting their use in high-stakes fields. Causal discovery offers a promising approach to improve transparency and reliability. However, current evaluations are often one-sided and lack assessments focused on interpretability performance. Additionally, these evaluations rely on synthetic data and lack comprehensive assessments of real-world datasets. These lead to promising methods potentially being overlooked. To address these issues, we propose a flexible evaluation framework with metrics for evaluating differences in causal structures and causal effects, which are crucial attributes that help improve the interpretability of LLMs. We introduce the Open Causal Discovery Benchmark (OCDB), based on real data, to promote fair comparisons and drive optimization of algorithms. Additionally, our new metrics account for undirected edges, enabling fair comparisons between Directed Acyclic Graphs (DAGs) and Completed Partially Directed Acyclic Graphs (CPDAGs). Experimental results show significant shortcomings in existing algorithms' generalization capabilities on real data, highlighting the potential for performance improvement and the importance of our framework in advancing causal discovery techniques.
6/10/2024
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
0
0
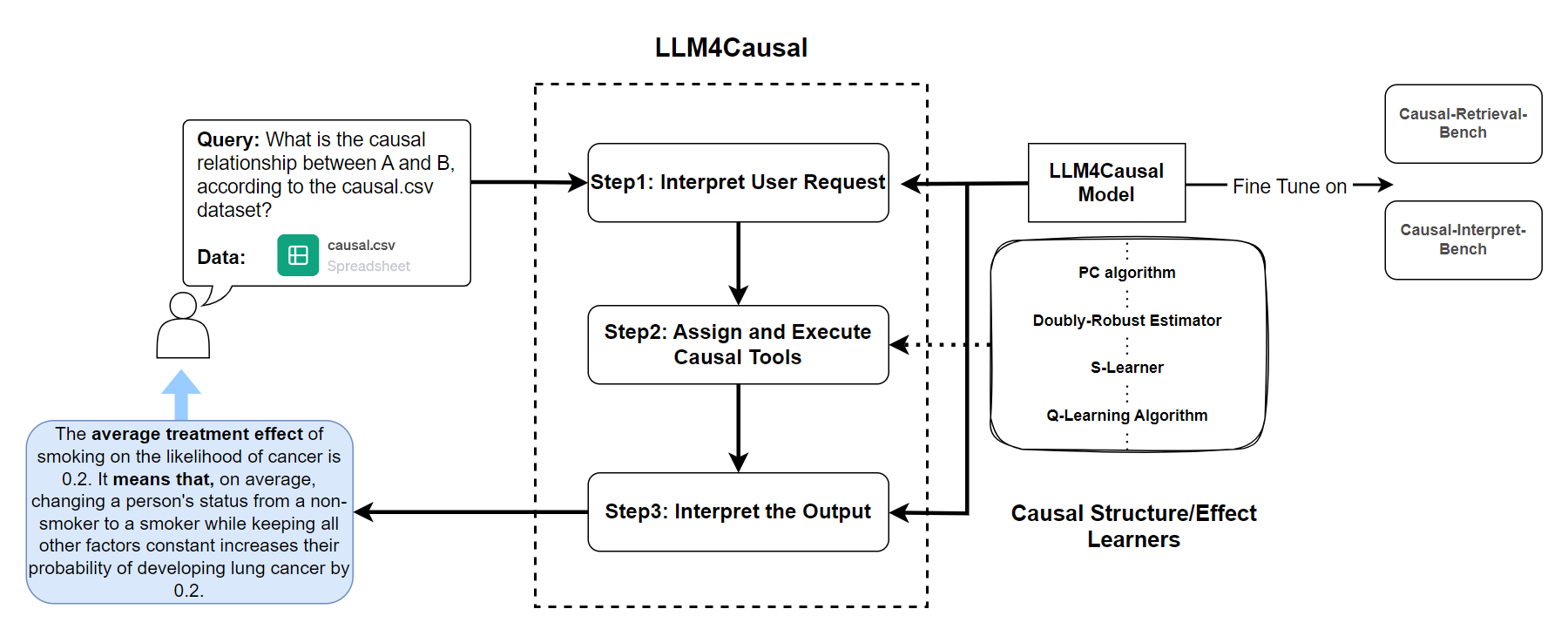
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
4/15/2024