Benchmarking Cross-Domain Audio-Visual Deception Detection

0
🔎
Sign in to get full access
Overview
- This research paper explores the challenge of automated deception detection, which is crucial for accurately assessing truthfulness and identifying deceptive behavior.
- Conventional techniques like polygraph devices rely on physiological signals, but recent developments in audio-visual deception detection have shown they can outperform human observers on public datasets.
- However, the generalizability of these audio-visual approaches across different scenarios remains largely unexplored.
- To address this, the researchers present the first cross-domain audio-visual deception detection benchmark to assess how well these methods generalize for real-world use.
Plain English Explanation
Detecting when someone is being deceptive or lying is an important task, both for personal interactions and for applications like security and law enforcement. Traditional methods like polygraph tests look at physical signs like heart rate and sweating to try to determine if someone is being truthful. However, recent research has shown that using a combination of audio (speech) and video (facial expressions and body language) can be even better at identifying deception than human observers.
Despite these promising findings, the researchers point out that we still don't know how well these audio-visual deception detection methods will work in different real-world situations, beyond the specific datasets they were tested on. To address this, the researchers created a new cross-domain audio-visual deception detection benchmark, which allows them to test how well these techniques generalize across different scenarios.
Technical Explanation
The researchers used widely adopted audio and visual features, as well as different neural network architectures, to benchmark the performance of audio-visual deception detection models. They evaluated both single-to-single domain generalization (training and testing on the same type of data) and multi-to-single domain generalization (training on data from multiple sources and testing on a different type of data).
To further explore the impact of using data from multiple source domains for training, the researchers investigated three different domain sampling strategies: domain-simultaneous, domain-alternating, and domain-by-domain. They also proposed a new Attention-Mixer fusion method to improve performance.
The researchers believe this new cross-domain benchmark will facilitate future research in audio-visual deception detection and help move the field closer to effective, multilingual, and domain-independent deception detection.
Critical Analysis
The researchers acknowledge that their cross-domain benchmark has some limitations, as it only evaluates performance on a few specific datasets and scenarios. They note that further research is needed to fully understand the generalizability of audio-visual deception detection methods across a wider range of real-world situations, including different audio and visual scene characteristics and multilingual contexts.
Additionally, the paper does not provide a comprehensive review of the existing audio anti-spoofing detection literature, which could offer valuable insights for improving the robustness of these deception detection systems.
Overall, the researchers have taken an important step towards addressing the generalizability challenge in audio-visual deception detection, but there is still significant work to be done to develop reliable, cross-domain solutions that can be deployed in real-world applications.
Conclusion
This research paper presents a valuable new cross-domain benchmark for evaluating the generalizability of audio-visual deception detection methods. By testing these techniques across different scenarios, the researchers aim to better understand their limitations and identify areas for future improvement.
The findings from this work can contribute to the development of more robust and reliable deception detection systems, which could have far-reaching implications for a wide range of applications, from personal interactions to law enforcement and security. As the researchers note, further advancements in this field could bring us closer to achieving effective, multilingual, and domain-independent deception detection capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Benchmarking Cross-Domain Audio-Visual Deception Detection
Xiaobao Guo, Zitong Yu, Nithish Muthuchamy Selvaraj, Bingquan Shen, Adams Wai-Kin Kong, Alex C. Kot
Automated deception detection is crucial for assisting humans in accurately assessing truthfulness and identifying deceptive behavior. Conventional contact-based techniques, like polygraph devices, rely on physiological signals to determine the authenticity of an individual's statements. Nevertheless, recent developments in automated deception detection have demonstrated that multimodal features derived from both audio and video modalities may outperform human observers on publicly available datasets. Despite these positive findings, the generalizability of existing audio-visual deception detection approaches across different scenarios remains largely unexplored. To close this gap, we present the first cross-domain audio-visual deception detection benchmark, that enables us to assess how well these methods generalize for use in real-world scenarios. We used widely adopted audio and visual features and different architectures for benchmarking, comparing single-to-single and multi-to-single domain generalization performance. To further exploit the impacts using data from multiple source domains for training, we investigate three types of domain sampling strategies, including domain-simultaneous, domain-alternating, and domain-by-domain for multi-to-single domain generalization evaluation. Furthermore, we proposed the Attention-Mixer fusion method to improve performance, and we believe that this new cross-domain benchmark will facilitate future research in audio-visual deception detection. Protocols and source code are available at href{https://github.com/Redaimao/cross_domain_DD}{https://github.com/Redaimao/cross_domain_DD}.
Read more5/14/2024

0
Cross-Domain Audio Deepfake Detection: Dataset and Analysis
Yuang Li, Min Zhang, Mengxin Ren, Miaomiao Ma, Daimeng Wei, Hao Yang
Audio deepfake detection (ADD) is essential for preventing the misuse of synthetic voices that may infringe on personal rights and privacy. Recent zero-shot text-to-speech (TTS) models pose higher risks as they can clone voices with a single utterance. However, the existing ADD datasets are outdated, leading to suboptimal generalization of detection models. In this paper, we construct a new cross-domain ADD dataset comprising over 300 hours of speech data that is generated by five advanced zero-shot TTS models. To simulate real-world scenarios, we employ diverse attack methods and audio prompts from different datasets. Experiments show that, through novel attack-augmented training, the Wav2Vec2-large and Whisper-medium models achieve equal error rates of 4.1% and 6.5% respectively. Additionally, we demonstrate our models' outstanding few-shot ADD ability by fine-tuning with just one minute of target-domain data. Nonetheless, neural codec compressors greatly affect the detection accuracy, necessitating further research.
Read more9/24/2024
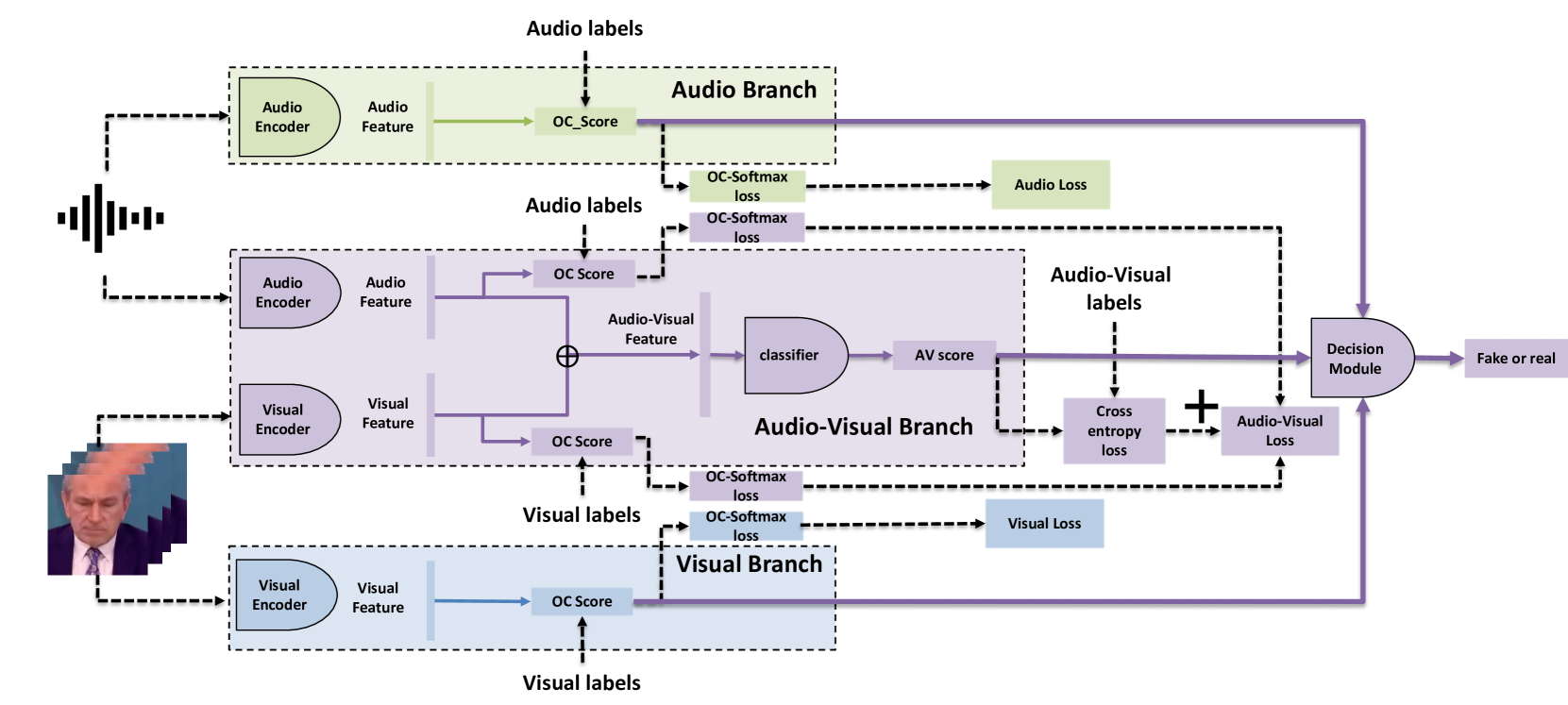
0
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024

0
Statistics-aware Audio-visual Deepfake Detector
Marcella Astrid, Enjie Ghorbel, Djamila Aouada
In this paper, we propose an enhanced audio-visual deep detection method. Recent methods in audio-visual deepfake detection mostly assess the synchronization between audio and visual features. Although they have shown promising results, they are based on the maximization/minimization of isolated feature distances without considering feature statistics. Moreover, they rely on cumbersome deep learning architectures and are heavily dependent on empirically fixed hyperparameters. Herein, to overcome these limitations, we propose: (1) a statistical feature loss to enhance the discrimination capability of the model, instead of relying solely on feature distances; (2) using the waveform for describing the audio as a replacement of frequency-based representations; (3) a post-processing normalization of the fakeness score; (4) the use of shallower network for reducing the computational complexity. Experiments on the DFDC and FakeAVCeleb datasets demonstrate the relevance of the proposed method.
Read more7/18/2024