Visual and audio scene classification for detecting discrepancies in video: a baseline method and experimental protocol
2405.00384
0
0

Abstract
This paper presents a baseline approach and an experimental protocol for a specific content verification problem: detecting discrepancies between the audio and video modalities in multimedia content. We first design and optimize an audio-visual scene classifier, to compare with existing classification baselines that use both modalities. Then, by applying this classifier separately to the audio and the visual modality, we can detect scene-class inconsistencies between them. To facilitate further research and provide a common evaluation platform, we introduce an experimental protocol and a benchmark dataset simulating such inconsistencies. Our approach achieves state-of-the-art results in scene classification and promising outcomes in audio-visual discrepancies detection, highlighting its potential in content verification applications.
Create account to get full access
Overview
- This paper proposes a baseline method and experimental protocol for detecting discrepancies in video content using audio-visual scene classification.
- The method combines visual and audio features to identify potential inconsistencies between the visual and audio information in a video.
- The authors introduce an experimental protocol to evaluate the effectiveness of the proposed approach in detecting content manipulation.
Plain English Explanation
The paper focuses on developing a way to identify when the visuals and audio in a video don't match up. This could be useful for detecting cases where someone has edited or manipulated the video content.
The key idea is to use machine learning to analyze both the visual and audio elements of a video. By looking at things like the type of scene, objects, and sounds, the system can try to identify any discrepancies between what's shown and what's heard. For example, if the video shows a quiet park but the audio includes loud construction noises, that could be a sign that the content has been tampered with.
The researchers also outline an experimental protocol to test how well this approach works. They describe ways to create altered videos with intentional mismatches between the visuals and audio, and then see if the system can reliably detect those discrepancies. This allows them to evaluate the effectiveness of the proposed method.
Technical Explanation
The paper presents a baseline method for audio-visual scene classification to detect discrepancies in video content. The approach combines visual and audio features using a self-attention mechanism to identify potential inconsistencies between the two modalities.
The visual feature extractor uses a pre-trained convolutional neural network (CNN) to generate spatial-temporal video representations. The audio feature extractor uses a pre-trained audio classification model to capture acoustic scene information. The visual and audio features are then fused using a cross-modal self-attention module that learns to attend to the relevant parts of each modality.
The fused representation is used to classify the overall audio-visual scene. The authors hypothesize that by training the model to accurately classify the scene, it will also be able to detect discrepancies between the visual and audio information.
To evaluate the proposed method, the authors introduce an experimental protocol that involves creating manipulated videos with intentional mismatches between the visuals and audio. The system's ability to correctly identify these mismatches is then measured as a proxy for its effectiveness in detecting content manipulation.
Critical Analysis
The paper presents a promising initial approach for using audio-visual scene classification to detect discrepancies in video content. The proposed method is relatively straightforward, leveraging pre-trained models and a self-attention mechanism to fuse the visual and audio features.
However, the authors acknowledge that the baseline method has limitations. For example, the performance may be sensitive to the specific types of manipulations present in the test videos. More complex or subtle forms of content editing may be harder for the system to detect.
Additionally, the experimental protocol relies on intentionally created manipulated videos, which may not fully capture the diversity of real-world content tampering techniques. Further research is needed to understand how the method would perform in more realistic scenarios.
It would also be valuable to explore more advanced audio-visual fusion and reasoning techniques, such as those used in audio-visual person verification or unified audio-visual perception models, to potentially improve the system's ability to detect discrepancies.
Conclusion
This paper presents a baseline method and experimental protocol for using audio-visual scene classification to detect discrepancies in video content. The proposed approach combines visual and audio features to identify potential inconsistencies between the two modalities, which could be indicative of content manipulation.
While the baseline method has limitations, the authors have laid the groundwork for further research in this area. Continued advancements in audio-visual perception and content verification techniques could lead to more robust and effective systems for identifying manipulated or synthetic video content, which is an important challenge in the era of deepfakes and other sophisticated media editing capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Zero-Shot Fake Video Detection by Audio-Visual Consistency
Xiaolou Li, Zehua Liu, Chen Chen, Lantian Li, Li Guo, Dong Wang
0
0
Recent studies have advocated the detection of fake videos as a one-class detection task, predicated on the hypothesis that the consistency between audio and visual modalities of genuine data is more significant than that of fake data. This methodology, which solely relies on genuine audio-visual data while negating the need for forged counterparts, is thus delineated as a `zero-shot' detection paradigm. This paper introduces a novel zero-shot detection approach anchored in content consistency across audio and video. By employing pre-trained ASR and VSR models, we recognize the audio and video content sequences, respectively. Then, the edit distance between the two sequences is computed to assess whether the claimed video is genuine. Experimental results indicate that, compared to two mainstream approaches based on semantic consistency and temporal consistency, our approach achieves superior generalizability across various deepfake techniques and demonstrates strong robustness against audio-visual perturbations. Finally, state-of-the-art performance gains can be achieved by simply integrating the decision scores of these three systems.
6/13/2024
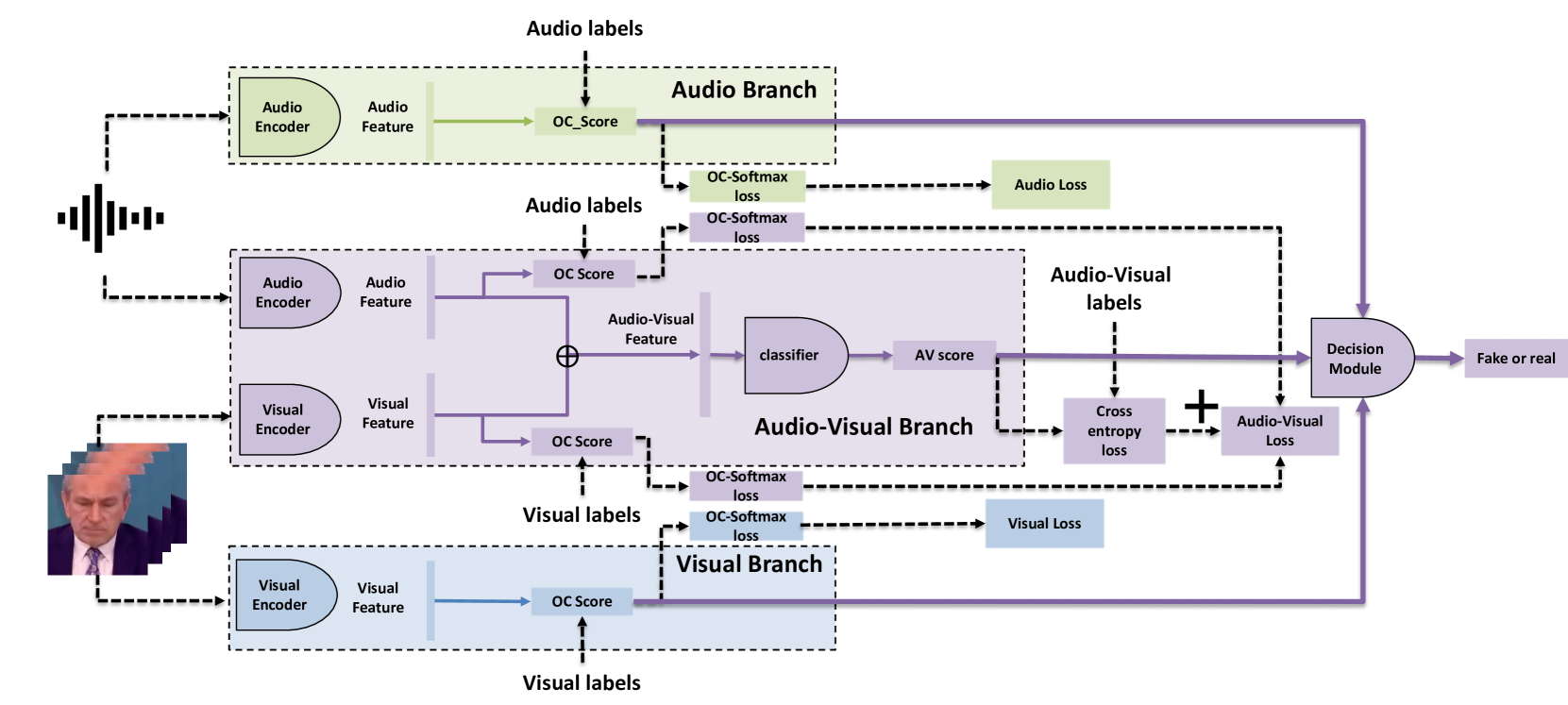
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
0
0
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake video(Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and unsynchronized video). The experimental results show that our approach improves the model's detection of unseen attacks by an average of 7.31% across four test sets, compared to the baseline model. Additionally, our proposed framework offers interpretability, indicating which modality the model identifies as fake.
6/21/2024
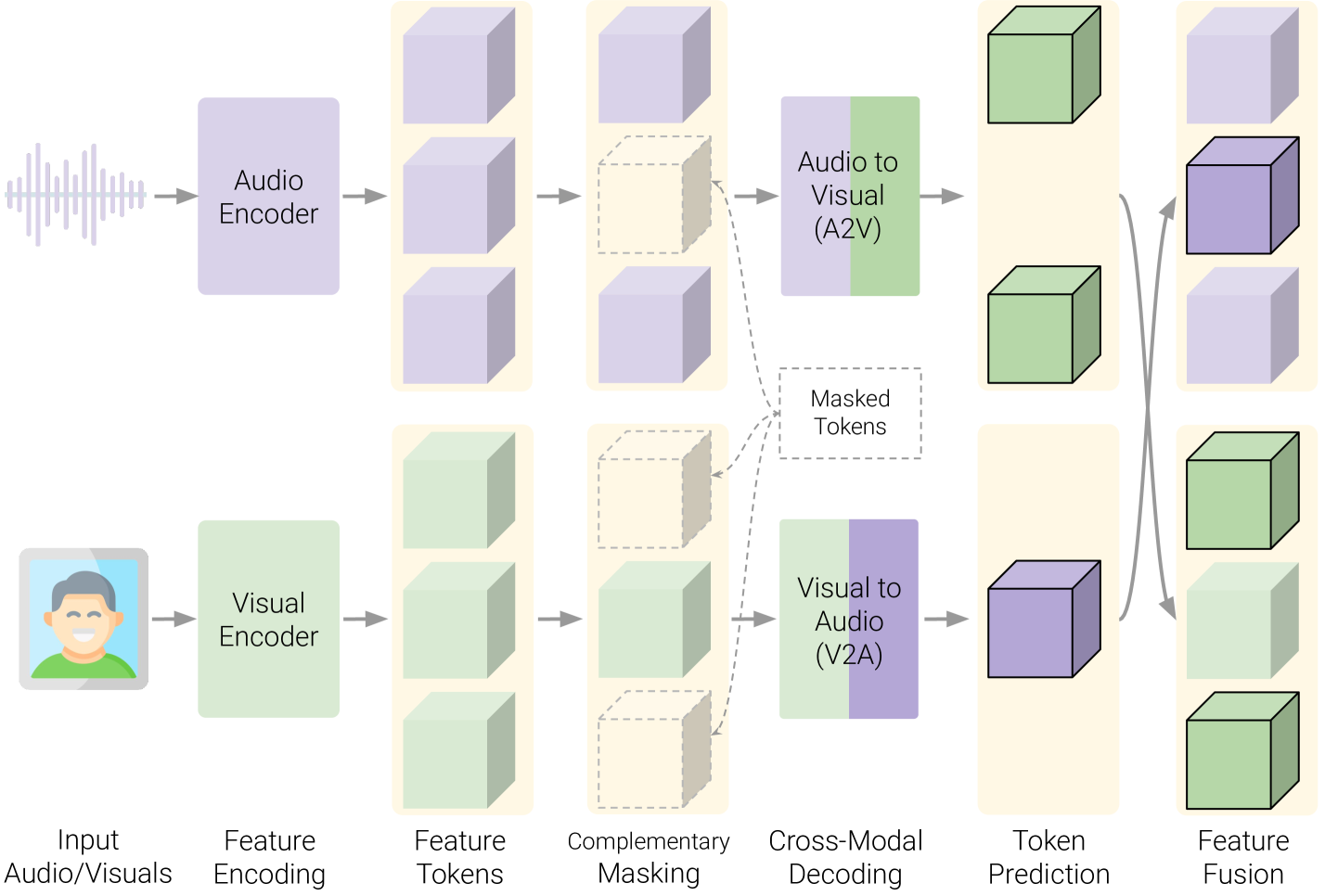
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
0
0
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
6/6/2024
🏅
Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
Nikhil Singh, Chih-Wei Wu, Iroro Orife, Mahdi Kalayeh
0
0
Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies and television shows to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech, similarly to the same video. Our results, from a comprehensive set of experiments investigating different training strategies, show this general approach improves performance on a range of downstream auditory and audiovisual tasks, without majorly affecting linguistic task performance overall. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance on diverse downstream tasks.
6/11/2024