Benchmarking Monocular 3D Dog Pose Estimation Using In-The-Wild Motion Capture Data

0

Sign in to get full access
Overview
- This paper focuses on benchmarking monocular 3D dog pose estimation using in-the-wild motion capture data.
- The authors introduce the 3DDogs-Lab dataset, which contains motion capture data of dogs in natural environments.
- The paper evaluates the performance of several 3D pose estimation models on this challenging dataset.
Plain English Explanation
The paper examines the task of estimating the 3D body pose of dogs from a single camera image. This is a difficult problem because dogs can move in complex ways, and their poses can vary greatly depending on the environment and situation. To address this challenge, the researchers created the 3DDogs-Lab dataset, which contains motion capture data of dogs in real-world, "in-the-wild" settings.
The 3DDogs-Lab dataset provides a more realistic and diverse set of dog poses compared to previous lab-based datasets. By benchmarking existing 3D pose estimation models on this new dataset, the authors can evaluate how well these models perform in real-world conditions. This is important for developing practical applications, such as dogs.fyi/papers/arxiv/improving-robustness-3d-human-pose-estimation-benchmark or freeman.fyi/papers/arxiv/towards-benchmarking-3d-human-pose-estimation, that require accurate 3D dog pose estimation.
Technical Explanation
The paper introduces the 3DDogs-Lab dataset, which contains motion capture data of dogs in various natural environments. The dataset includes over 100,000 frames of 3D dog pose data captured using a professional motion capture system. The authors carefully selected the scenes and dog behaviors to ensure the dataset represents a diverse range of real-world conditions.
To evaluate the performance of 3D dog pose estimation models, the researchers benchmark several state-of-the-art approaches on the 3DDogs-Lab dataset. The models include posebench.fyi/papers/arxiv/benchmarking-robustness-pose-estimation-models-under and multi-person.fyi/papers/arxiv/3d-pose-estimation-from-unlabelled, which were originally designed for human pose estimation but are adapted for dogs. The authors report various performance metrics, such as 3D joint error and joint detection rates, to assess the models' accuracy and robustness.
The results show that existing 3D dog pose estimation models struggle with the diversity and complexity of the 3DDogs-Lab dataset, highlighting the need for further research and development in this area. The authors provide detailed analyses of the models' strengths and weaknesses, as well as suggestions for future improvements.
Critical Analysis
The 3DDogs-Lab dataset represents a significant advancement in dog pose estimation research, as it provides a more realistic and challenging benchmark compared to previous lab-based datasets. The in-the-wild nature of the data, with its diverse scenes and dog behaviors, is a crucial step towards developing practical 3D dog pose estimation applications.
However, the paper does not address some potential limitations of the dataset, such as the lack of camera calibration information or the potential for occlusions and other real-world challenges. Additionally, the evaluation of the pose estimation models is limited to a small number of approaches, and the authors do not provide a comprehensive comparison to other relevant work, such as multi-person.fyi/papers/arxiv/3d-pose-estimation-from-unlabelled or freeman.fyi/papers/arxiv/towards-benchmarking-3d-human-pose-estimation.
Despite these minor limitations, the 3DDogs-Lab dataset and the insights provided in this paper represent an important contribution to the field of 3D dog pose estimation. By identifying the challenges and limitations of current models, the authors pave the way for future research to address these issues and develop more robust and accurate 3D dog pose estimation solutions.
Conclusion
This paper introduces the 3DDogs-Lab dataset, which provides a more realistic and challenging benchmark for evaluating 3D dog pose estimation models. The authors demonstrate that existing approaches struggle with the diversity and complexity of the in-the-wild data, highlighting the need for further advancements in this field.
The 3DDogs-Lab dataset and the insights from this paper have the potential to spur new research and development in 3D dog pose estimation, ultimately leading to more accurate and practical applications in areas such as dogs.fyi/papers/arxiv/improving-robustness-3d-human-pose-estimation-benchmark and freeman.fyi/papers/arxiv/towards-benchmarking-3d-human-pose-estimation. By addressing the challenges identified in this work, researchers can take important steps towards delivering reliable and robust 3D dog pose estimation solutions for real-world use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking Monocular 3D Dog Pose Estimation Using In-The-Wild Motion Capture Data
Moira Shooter, Charles Malleson, Adrian Hilton
We introduce a new benchmark analysis focusing on 3D canine pose estimation from monocular in-the-wild images. A multi-modal dataset 3DDogs-Lab was captured indoors, featuring various dog breeds trotting on a walkway. It includes data from optical marker-based mocap systems, RGBD cameras, IMUs, and a pressure mat. While providing high-quality motion data, the presence of optical markers and limited background diversity make the captured video less representative of real-world conditions. To address this, we created 3DDogs-Wild, a naturalised version of the dataset where the optical markers are in-painted and the subjects are placed in diverse environments, enhancing its utility for training RGB image-based pose detectors. We show that using the 3DDogs-Wild to train the models leads to improved performance when evaluating on in-the-wild data. Additionally, we provide a thorough analysis using various pose estimation models, revealing their respective strengths and weaknesses. We believe that our findings, coupled with the datasets provided, offer valuable insights for advancing 3D animal pose estimation.
Read more6/21/2024
0
PoseBench: Benchmarking the Robustness of Pose Estimation Models under Corruptions
Sihan Ma, Jing Zhang, Qiong Cao, Dacheng Tao
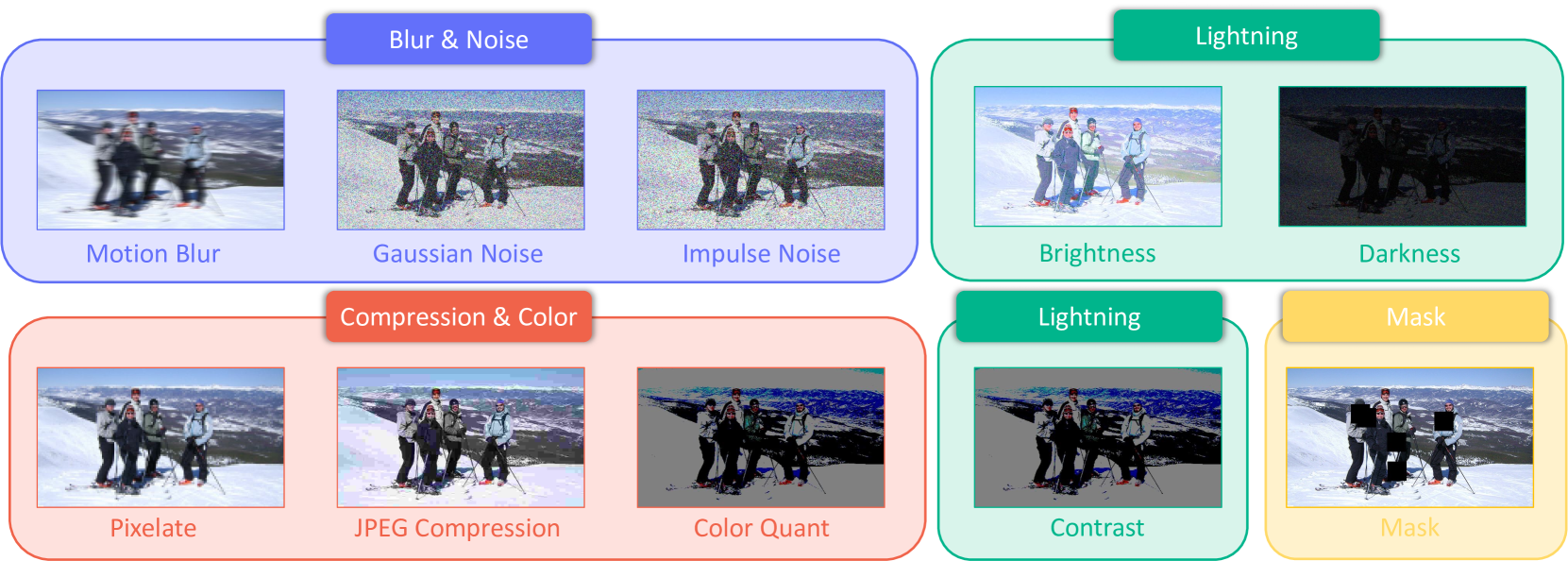
Pose estimation aims to accurately identify anatomical keypoints in humans and animals using monocular images, which is crucial for various applications such as human-machine interaction, embodied AI, and autonomous driving. While current models show promising results, they are typically trained and tested on clean data, potentially overlooking the corruption during real-world deployment and thus posing safety risks in practical scenarios. To address this issue, we introduce PoseBench, a comprehensive benchmark designed to evaluate the robustness of pose estimation models against real-world corruption. We evaluated 60 representative models, including top-down, bottom-up, heatmap-based, regression-based, and classification-based methods, across three datasets for human and animal pose estimation. Our evaluation involves 10 types of corruption in four categories: 1) blur and noise, 2) compression and color loss, 3) severe lighting, and 4) masks. Our findings reveal that state-of-the-art models are vulnerable to common real-world corruptions and exhibit distinct behaviors when tackling human and animal pose estimation tasks. To improve model robustness, we delve into various design considerations, including input resolution, pre-training datasets, backbone capacity, post-processing, and data augmentations. We hope that our benchmark will serve as a foundation for advancing research in robust pose estimation. The benchmark and source code will be released at https://xymsh.github.io/PoseBench
Read more9/17/2024
🔍
0
Improving the Robustness of 3D Human Pose Estimation: A Benchmark and Learning from Noisy Input
Trung-Hieu Hoang, Mona Zehni, Huy Phan, Duc Minh Vo, Minh N. Do
Despite the promising performance of current 3D human pose estimation techniques, understanding and enhancing their generalization on challenging in-the-wild videos remain an open problem. In this work, we focus on the robustness of 2D-to-3D pose lifters. To this end, we develop two benchmark datasets, namely Human3.6M-C and HumanEva-I-C, to examine the robustness of video-based 3D pose lifters to a wide range of common video corruptions including temporary occlusion, motion blur, and pixel-level noise. We observe the poor generalization of state-of-the-art 3D pose lifters in the presence of corruption and establish two techniques to tackle this issue. First, we introduce Temporal Additive Gaussian Noise (TAGN) as a simple yet effective 2D input pose data augmentation. Additionally, to incorporate the confidence scores output by the 2D pose detectors, we design a confidence-aware convolution (CA-Conv) block. Extensively tested on corrupted videos, the proposed strategies consistently boost the robustness of 3D pose lifters and serve as new baselines for future research.
Read more4/17/2024
📊
0
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
Read more4/10/2024