Benchmarking Pre-trained Large Language Models' Potential Across Urdu NLP tasks
2405.15453
0
0

Abstract
Large Language Models (LLMs) pre-trained on multilingual data have revolutionized natural language processing research, by transitioning from languages and task specific model pipelines to a single model adapted on a variety of tasks. However majority of existing multilingual NLP benchmarks for LLMs provide evaluation data in only few languages with little linguistic diversity. In addition these benchmarks lack quality assessment against the respective state-of the art models. This study presents an in-depth examination of prominent LLMs; GPT-3.5-turbo, Llama2-7B-Chat, Bloomz 7B1 and Bloomz 3B, across 14 tasks using 15 Urdu datasets, in a zero-shot setting, and their performance against state-of-the-art (SOTA) models, has been compared and analysed. Our experiments show that SOTA models surpass all the encoder-decoder pre-trained language models in all Urdu NLP tasks with zero-shot learning. Our results further show that LLMs with fewer parameters, but more language specific data in the base model perform better than larger computational models, but low language data.
Create account to get full access
Overview
- This paper benchmarks the performance of pre-trained large language models (LLMs) on a variety of Urdu natural language processing (NLP) tasks.
- The researchers evaluate the capabilities of several well-known LLMs, including BERT, RoBERTa, and XLM-R, across different Urdu NLP tasks such as text classification, named entity recognition, and question answering.
- The goal is to understand the potential and limitations of these pre-trained models for Urdu language understanding and to provide insights for further research and development of Urdu NLP systems.
Plain English Explanation
The researchers in this study wanted to test how well some popular large language models (LLMs) could handle tasks in the Urdu language. LLMs are powerful AI systems that have been trained on huge amounts of text data and can understand and generate human-like language.
The researchers looked at how well models like BERT, RoBERTa, and XLM-R performed on Urdu text classification, named entity recognition, and question answering. These are common natural language processing (NLP) tasks that involve understanding the meaning and structure of language.
The main goal was to see if these pre-trained LLMs, which were mostly trained on English data, could still be useful for processing Urdu, which is quite different from English. The researchers wanted to identify the strengths and limitations of using these LLMs for Urdu NLP, to help guide future research and development of Urdu language AI systems.
Technical Explanation
The researchers benchmarked the performance of several pre-trained large language models on a variety of Urdu NLP tasks. Specifically, they evaluated BERT, RoBERTa, and XLM-R - three prominent LLMs that have shown strong results across many languages.
For the benchmarking, the researchers used standard Urdu NLP datasets covering text classification, named entity recognition, and question answering. They fine-tuned the pre-trained LLMs on these Urdu task datasets and measured their performance relative to task-specific baselines.
The results showed that the LLMs generally performed well on the Urdu tasks, often outperforming task-specific baselines. However, there were also some limitations - the models struggled more with tasks requiring deeper language understanding, such as zero-shot and few-shot learning. The researchers also found that the models had difficulty handling Urdu's complex grammar and script compared to their performance on simpler languages like English.
Overall, the findings suggest that pre-trained LLMs can be a valuable starting point for developing Urdu NLP systems, but further research is needed to address the language-specific challenges and enhance their performance on more advanced Urdu tasks. The researchers highlight the need for more Urdu language data and model fine-tuning techniques tailored to the unique characteristics of the Urdu language.
Critical Analysis
The paper provides a comprehensive evaluation of pre-trained LLMs on a range of Urdu NLP tasks, offering valuable insights into their potential and limitations. However, it is important to note a few caveats and areas for further research:
Firstly, the study is limited to a relatively small number of LLMs, and there may be other models or approaches that could perform better on Urdu NLP. As the field of large language models continues to evolve, it would be important to expand the benchmarking to a wider range of models and techniques.
Additionally, the researchers acknowledge that their datasets and baselines may not fully capture the complexity and diversity of Urdu language use in real-world applications. More extensive and representative datasets, as well as a deeper understanding of Urdu linguistic features, could lead to more robust and accurate evaluations.
Finally, the paper does not delve into the potential ethical and societal implications of using LLMs for Urdu NLP tasks. As these models become more widely adopted, it will be crucial to consider issues such as bias, fairness, and the impact on marginalized Urdu-speaking communities.
Overall, this paper represents an important step in understanding the potential of pre-trained LLMs for Urdu language processing, but further research and development, as well as a more holistic consideration of the societal implications, will be essential for realizing the full benefits of these technologies for Urdu-speaking populations.
Conclusion
This study provides a comprehensive evaluation of the performance of pre-trained large language models on a variety of Urdu natural language processing tasks. The researchers found that models like BERT, RoBERTa, and XLM-R can be a valuable starting point for Urdu NLP, often outperforming task-specific baselines. However, the models also faced some limitations in handling the complexities of the Urdu language, particularly in more advanced tasks like zero-shot and few-shot learning.
The findings of this paper offer important insights for researchers and developers working on Urdu language AI systems. They highlight the potential of leveraging pre-trained LLMs for Urdu NLP, while also underscoring the need for continued research and development to address language-specific challenges and enhance model performance. As the field of large language models continues to evolve, this work lays the groundwork for further advancements in Urdu language understanding and processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Sanchit Ahuja, Divyanshu Aggarwal, Varun Gumma, Ishaan Watts, Ashutosh Sathe, Millicent Ochieng, Rishav Hada, Prachi Jain, Maxamed Axmed, Kalika Bali, Sunayana Sitaram
0
0
There has been a surge in LLM evaluation research to understand LLM capabilities and limitations. However, much of this research has been confined to English, leaving LLM building and evaluation for non-English languages relatively unexplored. Several new LLMs have been introduced recently, necessitating their evaluation on non-English languages. This study aims to perform a thorough evaluation of the non-English capabilities of SoTA LLMs (GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma) by comparing them on the same set of multilingual datasets. Our benchmark comprises 22 datasets covering 83 languages, including low-resource African languages. We also include two multimodal datasets in the benchmark and compare the performance of LLaVA models, GPT-4-Vision and Gemini-Pro-Vision. Our experiments show that larger models such as GPT-4, Gemini-Pro and PaLM2 outperform smaller models on various tasks, notably on low-resource languages, with GPT-4 outperforming PaLM2 and Gemini-Pro on more datasets. We also perform a study on data contamination and find that several models are likely to be contaminated with multilingual evaluation benchmarks, necessitating approaches to detect and handle contamination while assessing the multilingual performance of LLMs.
4/4/2024
💬
Unraveling the Dominance of Large Language Models Over Transformer Models for Bangla Natural Language Inference: A Comprehensive Study
Fatema Tuj Johora Faria, Mukaffi Bin Moin, Asif Iftekher Fahim, Pronay Debnath, Faisal Muhammad Shah
0
0
Natural Language Inference (NLI) is a cornerstone of Natural Language Processing (NLP), providing insights into the entailment relationships between text pairings. It is a critical component of Natural Language Understanding (NLU), demonstrating the ability to extract information from spoken or written interactions. NLI is mainly concerned with determining the entailment relationship between two statements, known as the premise and hypothesis. When the premise logically implies the hypothesis, the pair is labeled entailment. If the hypothesis contradicts the premise, the pair receives the contradiction label. When there is insufficient evidence to establish a connection, the pair is described as neutral. Despite the success of Large Language Models (LLMs) in various tasks, their effectiveness in NLI remains constrained by issues like low-resource domain accuracy, model overconfidence, and difficulty in capturing human judgment disagreements. This study addresses the underexplored area of evaluating LLMs in low-resourced languages such as Bengali. Through a comprehensive evaluation, we assess the performance of prominent LLMs and state-of-the-art (SOTA) models in Bengali NLP tasks, focusing on natural language inference. Utilizing the XNLI dataset, we conduct zero-shot and few-shot evaluations, comparing LLMs like GPT-3.5 Turbo and Gemini 1.5 Pro with models such as BanglaBERT, Bangla BERT Base, DistilBERT, mBERT, and sahajBERT. Our findings reveal that while LLMs can achieve comparable or superior performance to fine-tuned SOTA models in few-shot scenarios, further research is necessary to enhance our understanding of LLMs in languages with modest resources like Bengali. This study underscores the importance of continued efforts in exploring LLM capabilities across diverse linguistic contexts.
5/8/2024

New!The Model Arena for Cross-lingual Sentiment Analysis: A Comparative Study in the Era of Large Language Models
Xiliang Zhu, Shayna Gardiner, Tere Rold'an, David Rossouw
0
0
Sentiment analysis serves as a pivotal component in Natural Language Processing (NLP). Advancements in multilingual pre-trained models such as XLM-R and mT5 have contributed to the increasing interest in cross-lingual sentiment analysis. The recent emergence in Large Language Models (LLM) has significantly advanced general NLP tasks, however, the capability of such LLMs in cross-lingual sentiment analysis has not been fully studied. This work undertakes an empirical analysis to compare the cross-lingual transfer capability of public Small Multilingual Language Models (SMLM) like XLM-R, against English-centric LLMs such as Llama-3, in the context of sentiment analysis across English, Spanish, French and Chinese. Our findings reveal that among public models, SMLMs exhibit superior zero-shot cross-lingual performance relative to LLMs. However, in few-shot cross-lingual settings, public LLMs demonstrate an enhanced adaptive potential. In addition, we observe that proprietary GPT-3.5 and GPT-4 lead in zero-shot cross-lingual capability, but are outpaced by public models in few-shot scenarios.
6/28/2024
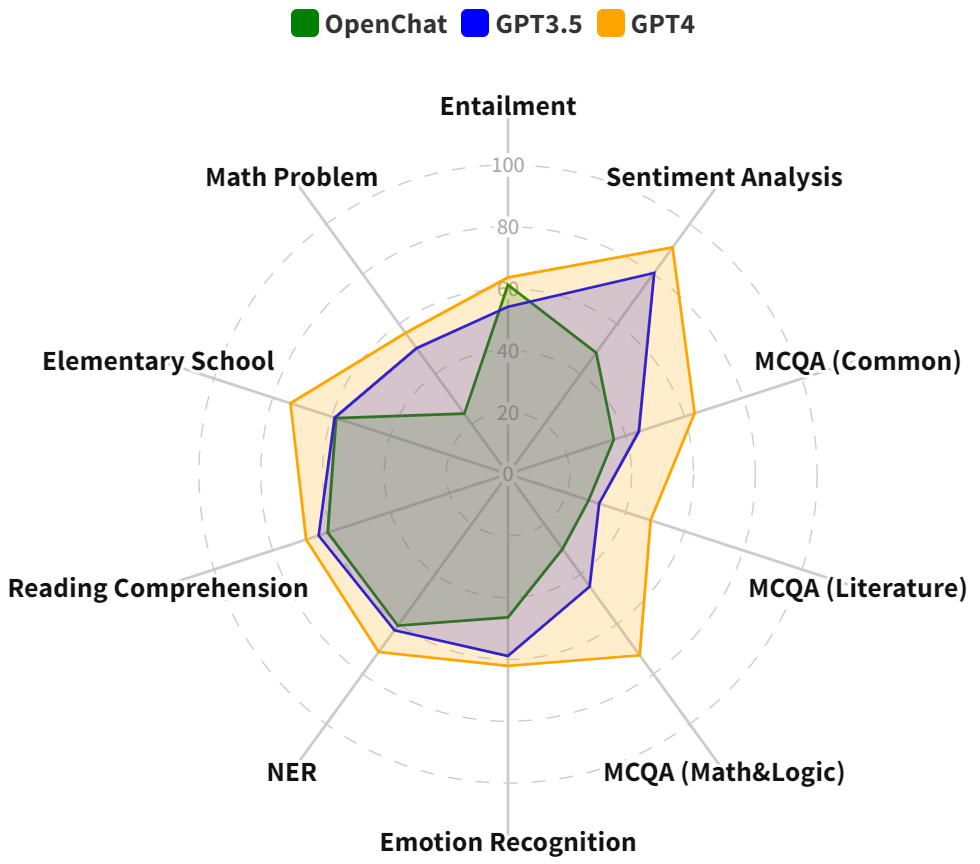
Benchmarking Large Language Models for Persian: A Preliminary Study Focusing on ChatGPT
Amirhossein Abaskohi, Sara Baruni, Mostafa Masoudi, Nesa Abbasi, Mohammad Hadi Babalou, Ali Edalat, Sepehr Kamahi, Samin Mahdizadeh Sani, Nikoo Naghavian, Danial Namazifard, Pouya Sadeghi, Yadollah Yaghoobzadeh
0
0
This paper explores the efficacy of large language models (LLMs) for Persian. While ChatGPT and consequent LLMs have shown remarkable performance in English, their efficiency for more low-resource languages remains an open question. We present the first comprehensive benchmarking study of LLMs across diverse Persian language tasks. Our primary focus is on GPT-3.5-turbo, but we also include GPT-4 and OpenChat-3.5 to provide a more holistic evaluation. Our assessment encompasses a diverse set of tasks categorized into classic, reasoning, and knowledge-based domains. To enable a thorough comparison, we evaluate LLMs against existing task-specific fine-tuned models. Given the limited availability of Persian datasets for reasoning tasks, we introduce two new benchmarks: one based on elementary school math questions and another derived from the entrance exams for 7th and 10th grades. Our findings reveal that while LLMs, especially GPT-4, excel in tasks requiring reasoning abilities and a broad understanding of general knowledge, they often lag behind smaller pre-trained models fine-tuned specifically for particular tasks. Additionally, we observe improved performance when test sets are translated to English before inputting them into GPT-3.5. These results highlight the significant potential for enhancing LLM performance in the Persian language. This is particularly noteworthy due to the unique attributes of Persian, including its distinct alphabet and writing styles.
4/4/2024