Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition
2406.09388
0
0

Abstract
Vision and language models (VLMs) such as CLIP have showcased remarkable zero-shot recognition abilities yet face challenges in visio-linguistic compositionality, particularly in linguistic comprehension and fine-grained image-text alignment. This paper explores the intricate relationship between compositionality and recognition -- two pivotal aspects of VLM capability. We conduct a comprehensive evaluation of existing VLMs, covering both pre-training approaches aimed at recognition and the fine-tuning methods designed to improve compositionality. Our evaluation employs 12 benchmarks for compositionality, along with 21 zero-shot classification and two retrieval benchmarks for recognition. In our analysis from 274 CLIP model checkpoints, we reveal patterns and trade-offs that emerge between compositional understanding and recognition accuracy. Ultimately, this necessitates strategic efforts towards developing models that improve both capabilities, as well as the meticulous formulation of benchmarks for compositionality. We open our evaluation framework at https://github.com/ytaek-oh/vl_compo.
Create account to get full access
Overview
- This paper explores the spectrum of visio-linguistic compositionality and recognition, examining how well models can understand and reason about the relationships between visual and textual information.
- The authors develop an evaluation toolkit to assess a model's ability to recognize and compose various types of visio-linguistic concepts, ranging from simple object-attribute pairs to more complex relational and contextual understanding.
- The paper provides insights into the strengths and limitations of current vision-language models, highlighting areas for future research and development.
Plain English Explanation
The paper investigates how well AI models can understand the connections between visual and textual information. The researchers created a set of tests to evaluate a model's ability to recognize and combine different types of visio-linguistic concepts, from basic object-attribute pairs to more complex relationships and contextual understanding.
By assessing models across this spectrum, the paper sheds light on the current capabilities and limitations of vision-language AI systems. This can help guide future research and development efforts to improve these models' understanding of the interplay between visual and linguistic information.
For example, a model might excel at identifying individual objects and their attributes, but struggle with recognizing more nuanced interactions or the broader context of a scene. The evaluation toolkit provides a way to pinpoint these strengths and weaknesses, informing strategies to build more robust and comprehensive visio-linguistic understanding.
Technical Explanation
The paper presents an evaluation toolkit to assess the spectrum of visio-linguistic compositionality and recognition in AI models. The toolkit includes a range of tasks, from simple object-attribute identification to more complex relational and contextual understanding.
By testing models on this diverse set of visio-linguistic concepts, the authors are able to contrast intra-modal ranking and cross-modal retrieval performance, providing insights into the models' underlying capabilities. This diagnostic approach helps diagnose the compositional knowledge of vision-language systems.
The authors also explore the potential for iterated learning to improve compositional understanding, as well as the benefits of ComCLIP, a training-free approach to compositional image-text matching.
Critical Analysis
The paper provides a comprehensive evaluation toolkit that can help identify the strengths and weaknesses of current vision-language models. However, the authors acknowledge that the toolkit is not exhaustive and may miss certain aspects of visio-linguistic understanding.
Additionally, the paper focuses primarily on evaluating models' performance on the provided tasks, without delving deeper into the underlying reasons for their successes or failures. Further research could explore the architectural choices, training data, and other factors that contribute to a model's compositional capabilities.
The authors also note that their evaluation is limited to static images and text, and does not consider the challenges of dynamic, real-world environments. Expanding the toolkit to include more diverse and realistic scenarios could provide additional insights into the practical capabilities of vision-language systems.
Conclusion
This paper presents a valuable evaluation toolkit for assessing the spectrum of visio-linguistic compositionality and recognition in AI models. By testing a wide range of visio-linguistic concepts, the authors are able to identify the strengths and limitations of current vision-language systems, guiding future research and development efforts.
The insights from this work can inform the design of more robust and comprehensive vision-language models, ultimately leading to AI systems with a deeper understanding of the connections between visual and textual information. This has the potential to enable more natural and intuitive human-AI interaction, as well as to support a range of applications, from image captioning to multimodal reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
0
0
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
4/26/2024
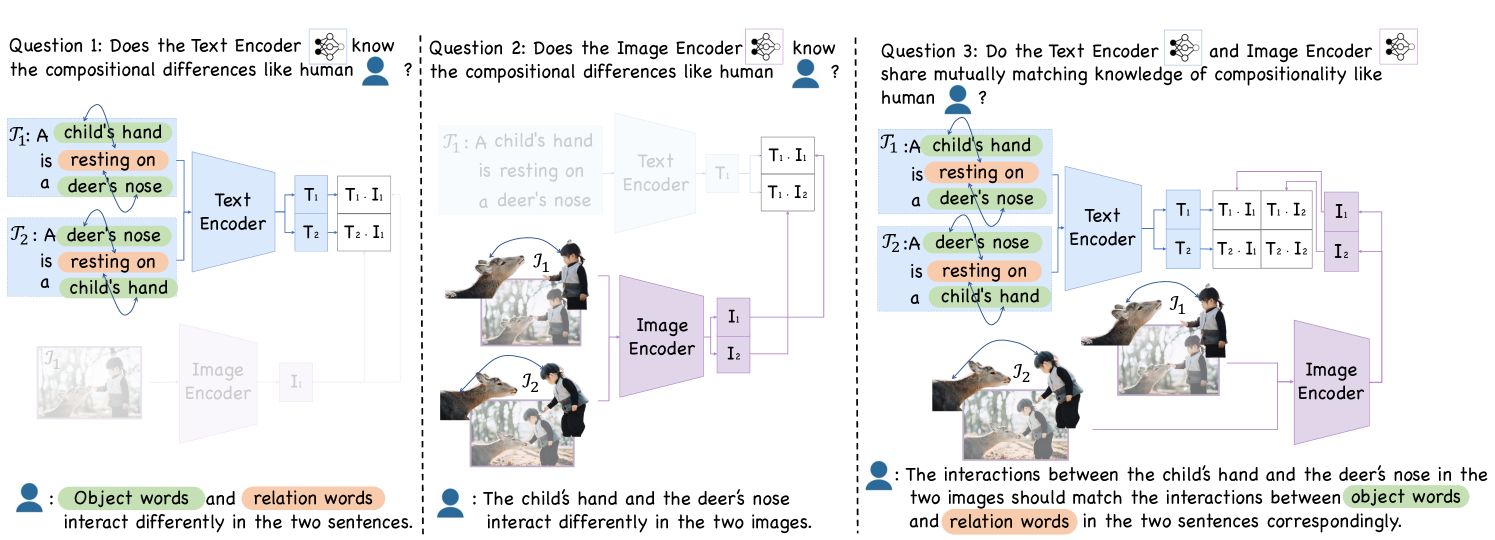
Diagnosing the Compositional Knowledge of Vision Language Models from a Game-Theoretic View
Jin Wang, Shichao Dong, Yapeng Zhu, Kelu Yao, Weidong Zhao, Chao Li, Ping Luo
0
0
Compositional reasoning capabilities are usually considered as fundamental skills to characterize human perception. Recent studies show that current Vision Language Models (VLMs) surprisingly lack sufficient knowledge with respect to such capabilities. To this end, we propose to thoroughly diagnose the composition representations encoded by VLMs, systematically revealing the potential cause for this weakness. Specifically, we propose evaluation methods from a novel game-theoretic view to assess the vulnerability of VLMs on different aspects of compositional understanding, e.g., relations and attributes. Extensive experimental results demonstrate and validate several insights to understand the incapabilities of VLMs on compositional reasoning, which provide useful and reliable guidance for future studies. The deliverables will be updated at https://vlms-compositionality-gametheory.github.io/.
5/28/2024
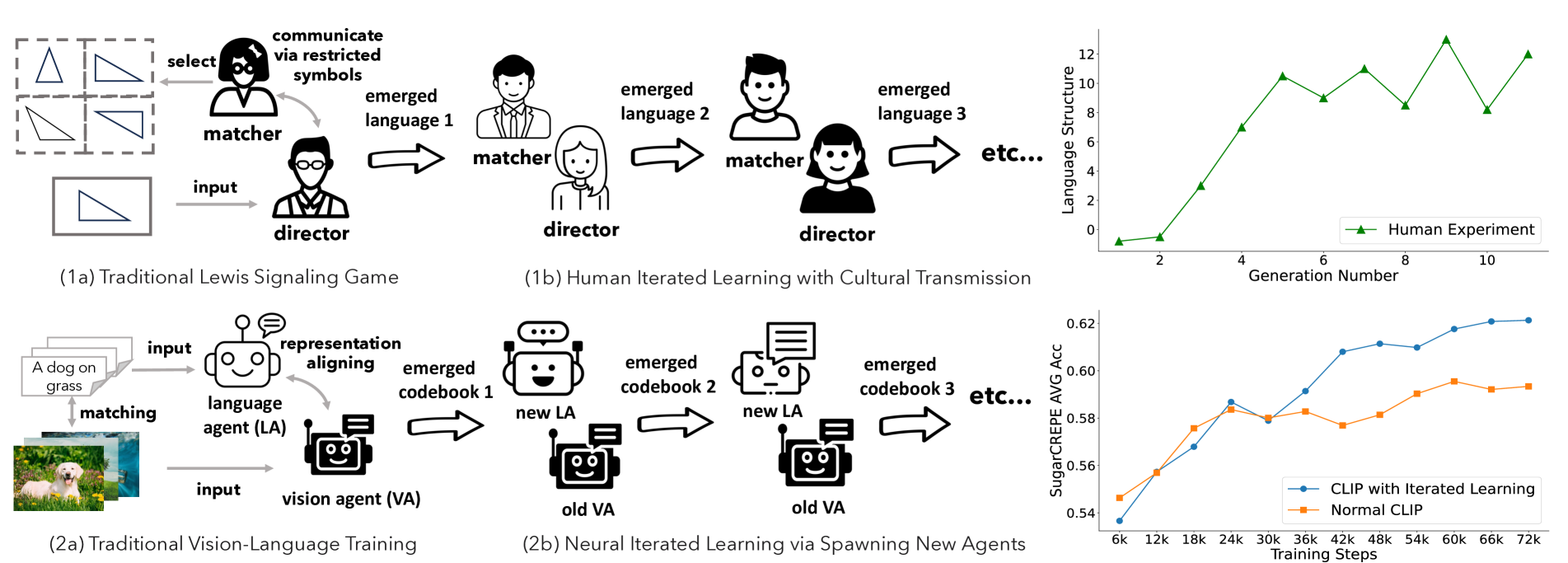
Iterated Learning Improves Compositionality in Large Vision-Language Models
Chenhao Zheng, Jieyu Zhang, Aniruddha Kembhavi, Ranjay Krishna
0
0
A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, recent investigations find that most-if not all-our state-of-the-art vision-language models struggle at compositionality. They are unable to distinguish between images of a girl in white facing a man in black and a girl in black facing a man in white. Moreover, prior work suggests that compositionality doesn't arise with scale: larger model sizes or training data don't help. This paper develops a new iterated training algorithm that incentivizes compositionality. We draw on decades of cognitive science research that identifies cultural transmission-the need to teach a new generation-as a necessary inductive prior that incentivizes humans to develop compositional languages. Specifically, we reframe vision-language contrastive learning as the Lewis Signaling Game between a vision agent and a language agent, and operationalize cultural transmission by iteratively resetting one of the agent's weights during training. After every iteration, this training paradigm induces representations that become easier to learn, a property of compositional languages: e.g. our model trained on CC3M and CC12M improves standard CLIP by 4.7%, 4.0% respectfully in the SugarCrepe benchmark.
4/3/2024

Benchmarking Zero-Shot Recognition with Vision-Language Models: Challenges on Granularity and Specificity
Zhenlin Xu, Yi Zhu, Tiffany Deng, Abhay Mittal, Yanbei Chen, Manchen Wang, Paolo Favaro, Joseph Tighe, Davide Modolo
0
0
This paper presents novel benchmarks for evaluating vision-language models (VLMs) in zero-shot recognition, focusing on granularity and specificity. Although VLMs excel in tasks like image captioning, they face challenges in open-world settings. Our benchmarks test VLMs' consistency in understanding concepts across semantic granularity levels and their response to varying text specificity. Findings show that VLMs favor moderately fine-grained concepts and struggle with specificity, often misjudging texts that differ from their training data. Extensive evaluations reveal limitations in current VLMs, particularly in distinguishing between correct and subtly incorrect descriptions. While fine-tuning offers some improvements, it doesn't fully address these issues, highlighting the need for VLMs with enhanced generalization capabilities for real-world applications. This study provides insights into VLM limitations and suggests directions for developing more robust models.
6/19/2024