BEND: Benchmarking DNA Language Models on biologically meaningful tasks

0
💬
Sign in to get full access
Overview
- The paper discusses the challenge of experimentally annotating the various functional, non-coding, and regulatory elements encoded in genomic DNA sequences.
- It presents BEND, a Benchmark for DNA language models that features a collection of realistic and biologically meaningful downstream tasks defined on the human genome.
- The paper evaluates how well current DNA language models perform on these tasks and finds that while they can approach the performance of expert methods on some tasks, they only capture limited information about long-range features.
Plain English Explanation
The human genome, or the complete set of genetic instructions that govern the processes in our cells, is a complex and vast amount of information. While scientists have been able to sequence, or read, the genome, understanding the various functional, regulatory, and non-coding elements encoded in the DNA sequence remains a significant challenge. This is because experimentally annotating, or identifying and categorizing, these elements is both expensive and difficult.
To address this, researchers have been exploring the use of unsupervised language modeling techniques, similar to those used for analyzing protein sequences, to learn from the patterns in genomic DNA data. However, the evaluation of these DNA language models has been inconsistent, and might not fully capture the unique challenges of genome annotation, such as the length, scale, and sparsity of the data.
In this study, the researchers introduce BEND, a benchmark for evaluating DNA language models on a collection of realistic and biologically meaningful tasks. They find that while current DNA language models can perform well on some tasks, they are limited in their ability to capture long-range features and relationships within the genome.
Technical Explanation
The researchers present BEND, a Benchmark for DNA language models, which features a collection of realistic and biologically meaningful downstream tasks defined on the human genome. These tasks are designed to better capture the fundamental challenges of genome annotation, including the length, scale, and sparsity of the data.
The researchers evaluate several current DNA language models on the BEND tasks and find that while these models can approach the performance of expert methods on some tasks, they only capture limited information about long-range features within the genome. This suggests that current DNA language models, while promising, still have room for improvement in accurately modeling the complex and hierarchical structure of genomic data.
The BEND benchmark is available on GitHub, allowing for further research and development of more advanced DNA language models that can better handle the unique characteristics of genomic data.
Critical Analysis
The researchers acknowledge that while BEND provides a more comprehensive evaluation of DNA language models, it still may not fully capture all the nuances and challenges of genome annotation. For example, the tasks in BEND are defined on the human genome, which has its own unique properties and characteristics. Applying BEND to other genomes, such as those of other organisms, may reveal additional insights and limitations of current DNA language models.
Additionally, the researchers note that the performance of DNA language models on the BEND tasks is still limited in their ability to capture long-range features and relationships within the genome. This suggests that further research is needed to develop more sophisticated models that can better account for the hierarchical and complex nature of genomic data.
It would also be valuable to see the researchers discuss potential ways to address these limitations, such as exploring architectural modifications, incorporating domain-specific knowledge, or leveraging multimodal approaches that combine genomic data with other relevant biological information, as demonstrated in projects like MolBind.
Conclusion
The paper introduces BEND, a benchmark for evaluating DNA language models on realistic and biologically meaningful tasks. The results suggest that while current DNA language models can perform well on some tasks, they are limited in their ability to capture the full complexity and long-range features of genomic data.
The development of BEND represents an important step towards more comprehensive and rigorous evaluation of DNA language models, which are a promising approach for improving our understanding of the genome and its intricate regulatory mechanisms. Further research and innovation in this area could lead to significant advancements in genome annotation and, ultimately, in our understanding of cellular processes and the development of new therapeutic interventions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
BEND: Benchmarking DNA Language Models on biologically meaningful tasks
Frederikke Isa Marin, Felix Teufel, Marc Horlacher, Dennis Madsen, Dennis Pultz, Ole Winther, Wouter Boomsma
The genome sequence contains the blueprint for governing cellular processes. While the availability of genomes has vastly increased over the last decades, experimental annotation of the various functional, non-coding and regulatory elements encoded in the DNA sequence remains both expensive and challenging. This has sparked interest in unsupervised language modeling of genomic DNA, a paradigm that has seen great success for protein sequence data. Although various DNA language models have been proposed, evaluation tasks often differ between individual works, and might not fully recapitulate the fundamental challenges of genome annotation, including the length, scale and sparsity of the data. In this study, we introduce BEND, a Benchmark for DNA language models, featuring a collection of realistic and biologically meaningful downstream tasks defined on the human genome. We find that embeddings from current DNA LMs can approach performance of expert methods on some tasks, but only capture limited information about long-range features. BEND is available at https://github.com/frederikkemarin/BEND.
Read more4/10/2024

0
A Benchmark Dataset for Multimodal Prediction of Enzymatic Function Coupling DNA Sequences and Natural Language
Yuchen Zhang, Ratish Kumar Chandrakant Jha, Soumya Bharadwaj, Vatsal Sanjaykumar Thakkar, Adrienne Hoarfrost, Jin Sun
Predicting gene function from its DNA sequence is a fundamental challenge in biology. Many deep learning models have been proposed to embed DNA sequences and predict their enzymatic function, leveraging information in public databases linking DNA sequences to an enzymatic function label. However, much of the scientific community's knowledge of biological function is not represented in these categorical labels, and is instead captured in unstructured text descriptions of mechanisms, reactions, and enzyme behavior. These descriptions are often captured alongside DNA sequences in biological databases, albeit in an unstructured manner. Deep learning of models predicting enzymatic function are likely to benefit from incorporating this multi-modal data encoding scientific knowledge of biological function. There is, however, no dataset designed for machine learning algorithms to leverage this multi-modal information. Here we propose a novel dataset and benchmark suite that enables the exploration and development of large multi-modal neural network models on gene DNA sequences and natural language descriptions of gene function. We present baseline performance on benchmarks for both unsupervised and supervised tasks that demonstrate the difficulty of this modeling objective, while demonstrating the potential benefit of incorporating multi-modal data types in function prediction compared to DNA sequences alone. Our dataset is at: https://hoarfrost-lab.github.io/BioTalk/.
Read more7/24/2024
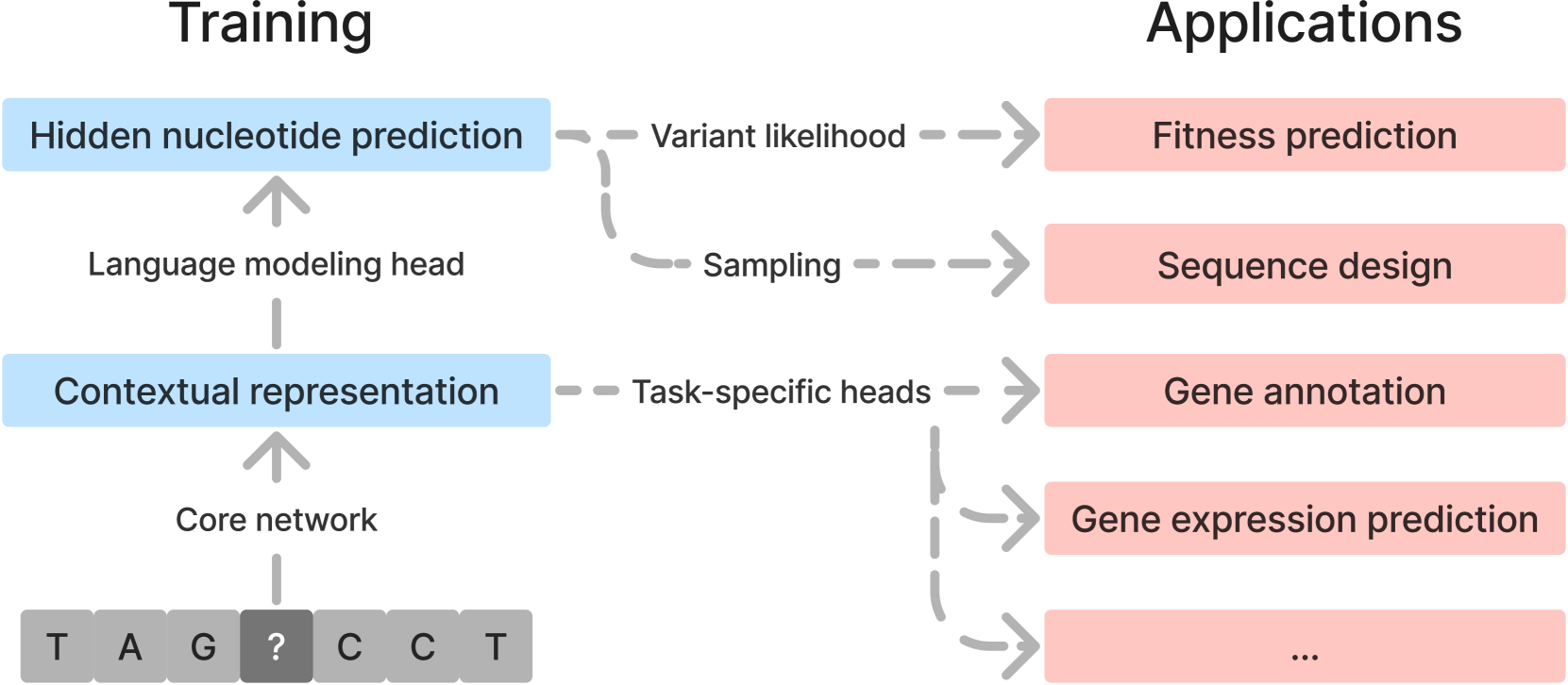
0
Genomic Language Models: Opportunities and Challenges
Gonzalo Benegas, Chengzhong Ye, Carlos Albors, Jianan Canal Li, Yun S. Song
Large language models (LLMs) are having transformative impacts across a wide range of scientific fields, particularly in the biomedical sciences. Just as the goal of Natural Language Processing is to understand sequences of words, a major objective in biology is to understand biological sequences. Genomic Language Models (gLMs), which are LLMs trained on DNA sequences, have the potential to significantly advance our understanding of genomes and how DNA elements at various scales interact to give rise to complex functions. In this review, we showcase this potential by highlighting key applications of gLMs, including fitness prediction, sequence design, and transfer learning. Despite notable recent progress, however, developing effective and efficient gLMs presents numerous challenges, especially for species with large, complex genomes. We discuss major considerations for developing and evaluating gLMs.
Read more7/17/2024

0
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Jon M. Laurent, Joseph D. Janizek, Michael Ruzo, Michaela M. Hinks, Michael J. Hammerling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D. White, Samuel G. Rodriques
There is widespread optimism that frontier Large Language Models (LLMs) and LLM-augmented systems have the potential to rapidly accelerate scientific discovery across disciplines. Today, many benchmarks exist to measure LLM knowledge and reasoning on textbook-style science questions, but few if any benchmarks are designed to evaluate language model performance on practical tasks required for scientific research, such as literature search, protocol planning, and data analysis. As a step toward building such benchmarks, we introduce the Language Agent Biology Benchmark (LAB-Bench), a broad dataset of over 2,400 multiple choice questions for evaluating AI systems on a range of practical biology research capabilities, including recall and reasoning over literature, interpretation of figures, access and navigation of databases, and comprehension and manipulation of DNA and protein sequences. Importantly, in contrast to previous scientific benchmarks, we expect that an AI system that can achieve consistently high scores on the more difficult LAB-Bench tasks would serve as a useful assistant for researchers in areas such as literature search and molecular cloning. As an initial assessment of the emergent scientific task capabilities of frontier language models, we measure performance of several against our benchmark and report results compared to human expert biology researchers. We will continue to update and expand LAB-Bench over time, and expect it to serve as a useful tool in the development of automated research systems going forward. A public subset of LAB-Bench is available for use at the following URL: https://huggingface.co/datasets/futurehouse/lab-bench
Read more7/18/2024