Bengali Fake Reviews: A Benchmark Dataset and Detection System
2308.01987
0
0
🔎
Abstract
The proliferation of fake reviews on various online platforms has created a major concern for both consumers and businesses. Such reviews can deceive customers and cause damage to the reputation of products or services, making it crucial to identify them. Although the detection of fake reviews has been extensively studied in English language, detecting fake reviews in non-English languages such as Bengali is still a relatively unexplored research area. This paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in Bengali. The dataset consists of 7710 non-fake and 1339 fake food-related reviews collected from social media posts. To convert non-Bengali words in a review, a unique pipeline has been proposed that translates English words to their corresponding Bengali meaning and also back transliterates Romanized Bengali to Bengali. We have conducted rigorous experimentation using multiple deep learning and pre-trained transformer language models to develop a reliable detection system. Finally, we propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator . According to the experiment results, the proposed ensemble model obtained a weighted F1-score of 0.9843 on 13390 reviews, including 1339 actual fake reviews and 5356 augmented fake reviews generated with the nlpaug library. The remaining 6695 reviews were randomly selected from the 7710 non-fake instances. The model achieved a 0.9558 weighted F1-score when the fake reviews were augmented using the bnaug library.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in the Bengali language.
- The dataset consists of 7,710 non-fake and 1,339 fake food-related reviews collected from social media posts.
- The researchers develop a unique pipeline to handle non-Bengali words in the reviews, translating English words to Bengali and back-transliterating Romanized Bengali to Bengali.
- Multiple deep learning and pre-trained transformer language models are used to develop a reliable fake review detection system.
- The researchers propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator.
- The proposed ensemble model achieves a weighted F1-score of 0.9843 on the BFRD dataset, including 1,339 actual fake reviews and 5,356 augmented fake reviews.
Plain English Explanation
Online reviews play a crucial role in helping consumers make purchasing decisions. However, the growing number of fake reviews on various platforms can mislead customers and harm the reputation of products or services. This is a significant concern for both consumers and businesses.
While detecting fake reviews in English has been extensively studied, identifying fake reviews in non-English languages, such as Bengali, is a relatively unexplored area. To address this, the researchers in this paper have created the first publicly available dataset for detecting fake reviews in Bengali, called the Bengali Fake Review Detection (BFRD) dataset.
The BFRD dataset includes 7,710 non-fake and 1,339 fake food-related reviews collected from social media posts. Since the reviews may contain non-Bengali words, the researchers developed a unique pipeline to handle them. This pipeline translates English words to their Bengali equivalents and also back-transliterates Romanized Bengali to Bengali.
Using the BFRD dataset, the researchers conducted extensive experiments with various deep learning and pre-trained transformer language models to develop a reliable fake review detection system. Ultimately, they propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator.
The proposed ensemble model achieved a very high weighted F1-score of 0.9843 on the BFRD dataset, demonstrating its effectiveness in identifying fake reviews in the Bengali language.
Technical Explanation
The researchers created the Bengali Fake Review Detection (BFRD) dataset, which consists of 7,710 non-fake and 1,339 fake food-related reviews collected from social media posts. To handle non-Bengali words in the reviews, the researchers developed a unique pipeline that translates English words to their corresponding Bengali meanings and back-transliterates Romanized Bengali to Bengali.
The researchers conducted extensive experiments using multiple deep learning and pre-trained transformer language models to develop a reliable fake review detection system. They evaluated the performance of various models, including BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator.
To further enhance the system's performance, the researchers proposed a weighted ensemble model that combines the predictions of the four pre-trained transformers. According to the experiment results, the proposed ensemble model achieved a weighted F1-score of 0.9843 on the BFRD dataset, which included 1,339 actual fake reviews and 5,356 augmented fake reviews generated using the nlpaug library. The model also achieved a 0.9558 weighted F1-score when the fake reviews were augmented using the bnaug library.
Critical Analysis
The researchers' work on the Bengali Fake Review Detection (BFRD) dataset and the proposed ensemble model is a significant contribution to the field of fake review detection, particularly for non-English languages like Bengali. However, the paper does not provide much information on the limitations of the dataset or the potential biases in the data collection process.
Additionally, while the ensemble model achieves impressive performance on the BFRD dataset, it would be valuable to test the model's generalization capabilities on a wider range of Bengali review data, including reviews from different domains beyond food-related content. This would help assess the model's robustness and potential for real-world deployment.
The paper also does not discuss the computational resources required to train and deploy the ensemble model, which could be a crucial factor in the model's practical feasibility, especially for resource-constrained environments. Further research on the trade-offs between model complexity, performance, and deployment feasibility would be valuable.
Overall, the researchers have made a significant contribution to the field of fake review detection in non-English languages, and their work serves as a strong foundation for future research in this area. However, additional research is needed to address the limitations and explore the practical implications of the proposed approach.
Conclusion
This paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in the Bengali language. The researchers developed a unique pipeline to handle non-Bengali words in the reviews and used multiple deep learning and pre-trained transformer language models to create a reliable fake review detection system.
The proposed weighted ensemble model, which combines four pre-trained transformers, achieved impressive performance on the BFRD dataset, with a weighted F1-score of 0.9843. This work represents a significant advancement in the field of fake review detection for non-English languages and lays the groundwork for further research in this area.
While the results are promising, additional work is needed to address the limitations of the dataset and model, as well as to explore the practical implications of the proposed approach. Nonetheless, the researchers' contribution in this paper is a valuable step towards combating the growing problem of fake reviews on online platforms, ultimately benefiting both consumers and businesses.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Tackling Fake News in Bengali: Unraveling the Impact of Summarization vs. Augmentation on Pre-trained Language Models
Arman Sakif Chowdhury, G. M. Shahariar, Ahammed Tarik Aziz, Syed Mohibul Alam, Md. Azad Sheikh, Tanveer Ahmed Belal
0
0
With the rise of social media and online news sources, fake news has become a significant issue globally. However, the detection of fake news in low resource languages like Bengali has received limited attention in research. In this paper, we propose a methodology consisting of four distinct approaches to classify fake news articles in Bengali using summarization and augmentation techniques with five pre-trained language models. Our approach includes translating English news articles and using augmentation techniques to curb the deficit of fake news articles. Our research also focused on summarizing the news to tackle the token length limitation of BERT based models. Through extensive experimentation and rigorous evaluation, we show the effectiveness of summarization and augmentation in the case of Bengali fake news detection. We evaluated our models using three separate test datasets. The BanglaBERT Base model, when combined with augmentation techniques, achieved an impressive accuracy of 96% on the first test dataset. On the second test dataset, the BanglaBERT model, trained with summarized augmented news articles achieved 97% accuracy. Lastly, the mBERT Base model achieved an accuracy of 86% on the third test dataset which was reserved for generalization performance evaluation. The datasets and implementations are available at https://github.com/arman-sakif/Bengali-Fake-News-Detection
5/16/2024
🔎
Enhancing Bangla Fake News Detection Using Bidirectional Gated Recurrent Units and Deep Learning Techniques
Utsha Roy, Mst. Sazia Tahosin, Md. Mahedi Hassan, Taminul Islam, Fahim Imtiaz, Md Rezwane Sadik, Yassine Maleh, Rejwan Bin Sulaiman, Md. Simul Hasan Talukder
0
0
The rise of fake news has made the need for effective detection methods, including in languages other than English, increasingly important. The study aims to address the challenges of Bangla which is considered a less important language. To this end, a complete dataset containing about 50,000 news items is proposed. Several deep learning models have been tested on this dataset, including the bidirectional gated recurrent unit (GRU), the long short-term memory (LSTM), the 1D convolutional neural network (CNN), and hybrid architectures. For this research, we assessed the efficacy of the model utilizing a range of useful measures, including recall, precision, F1 score, and accuracy. This was done by employing a big application. We carry out comprehensive trials to show the effectiveness of these models in identifying bogus news in Bangla, with the Bidirectional GRU model having a stunning accuracy of 99.16%. Our analysis highlights the importance of dataset balance and the need for continual improvement efforts to a substantial degree. This study makes a major contribution to the creation of Bangla fake news detecting systems with limited resources, thereby setting the stage for future improvements in the detection process.
4/3/2024
Sentiment Polarity Analysis of Bangla Food Reviews Using Machine and Deep Learning Algorithms
Al Amin, Anik Sarkar, Md Mahamodul Islam, Asif Ahammad Miazee, Md Robiul Islam, Md Mahmudul Hoque
0
0
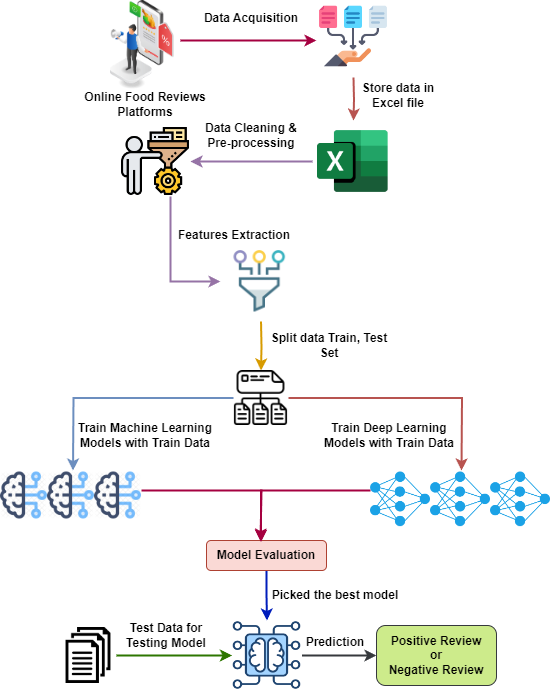
The Internet has become an essential tool for people in the modern world. Humans, like all living organisms, have essential requirements for survival. These include access to atmospheric oxygen, potable water, protective shelter, and sustenance. The constant flux of the world is making our existence less complicated. A significant portion of the population utilizes online food ordering services to have meals delivered to their residences. Although there are numerous methods for ordering food, customers sometimes experience disappointment with the food they receive. Our endeavor was to establish a model that could determine if food is of good or poor quality. We compiled an extensive dataset of over 1484 online reviews from prominent food ordering platforms, including Food Panda and HungryNaki. Leveraging the collected data, a rigorous assessment of various deep learning and machine learning techniques was performed to determine the most accurate approach for predicting food quality. Out of all the algorithms evaluated, logistic regression emerged as the most accurate, achieving an impressive 90.91% accuracy. The review offers valuable insights that will guide the user in deciding whether or not to order the food.
5/14/2024
🔎
MAiDE-up: Multilingual Deception Detection of GPT-generated Hotel Reviews
Oana Ignat, Xiaomeng Xu, Rada Mihalcea
0
0
Deceptive reviews are becoming increasingly common, especially given the increase in performance and the prevalence of LLMs. While work to date has addressed the development of models to differentiate between truthful and deceptive human reviews, much less is known about the distinction between real reviews and AI-authored fake reviews. Moreover, most of the research so far has focused primarily on English, with very little work dedicated to other languages. In this paper, we compile and make publicly available the MAiDE-up dataset, consisting of 10,000 real and 10,000 AI-generated fake hotel reviews, balanced across ten languages. Using this dataset, we conduct extensive linguistic analyses to (1) compare the AI fake hotel reviews to real hotel reviews, and (2) identify the factors that influence the deception detection model performance. We explore the effectiveness of several models for deception detection in hotel reviews across three main dimensions: sentiment, location, and language. We find that these dimensions influence how well we can detect AI-generated fake reviews.
4/22/2024