Sentiment Polarity Analysis of Bangla Food Reviews Using Machine and Deep Learning Algorithms

0
Sign in to get full access
Overview
- This paper focuses on sentiment polarity analysis of Bangla food reviews using machine and deep learning algorithms.
- The researchers developed a benchmark dataset of Bangla food reviews and evaluated the performance of various machine and deep learning models in classifying the sentiment polarity of the reviews.
- The paper provides insights into the challenges and opportunities in sentiment analysis of Bangla language text data.
Plain English Explanation
In this research, the authors looked at analyzing the sentiment, or emotional tone, of online reviews written in the Bangla language about food. They created a dataset of Bangla food reviews and then tested how well different machine learning and deep learning models could classify whether each review had a positive, negative, or neutral sentiment.
The motivation behind this work is that understanding the sentiment of online reviews is valuable for businesses, as it can help them gauge customer satisfaction and identify areas for improvement. However, most sentiment analysis research has focused on languages like English, while less work has been done on languages like Bangla, which is spoken by over 265 million people.
By developing a benchmark dataset of Bangla food reviews and evaluating various AI models on this data, the researchers aimed to advance the state of the art in sentiment analysis for the Bangla language. Their findings provide insights into the unique challenges and opportunities in working with Bangla text data, which could inform the development of better natural language processing tools and applications for this language in the future.
Technical Explanation
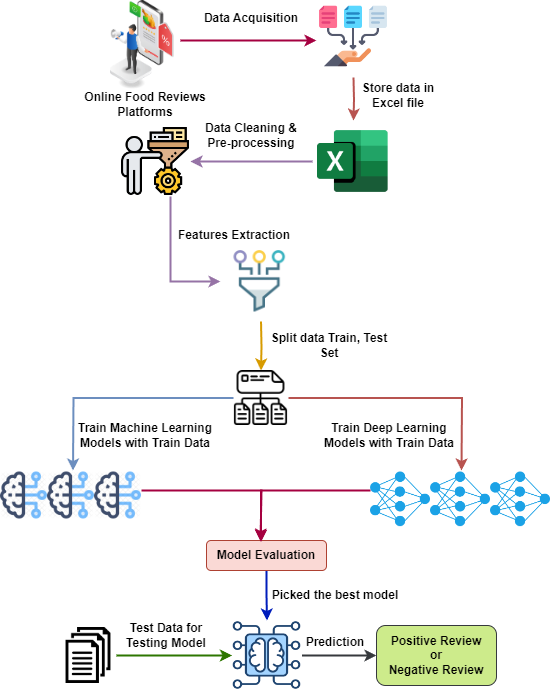
The researchers first constructed a dataset of Bangla food reviews collected from various online sources. They manually annotated the reviews with positive, negative, or neutral sentiment labels to create a ground truth benchmark.
They then evaluated the performance of several machine learning (ML) and deep learning (DL) models on the task of classifying the sentiment polarity of the Bangla reviews. The ML models included Logistic Regression, Support Vector Machines, and Random Forest Classifier, while the DL models included Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM) networks, and Bidirectional Encoder Representations from Transformers (BERT).
The experiments showed that the deep learning models, particularly the BERT-based model, outperformed the traditional machine learning approaches in accurately classifying the sentiment of the Bangla food reviews. The BERT model achieved an F1-score of 0.87, demonstrating its effectiveness in capturing the nuanced sentiment expressed in the Bangla text data.
The researchers also analyzed the challenges in sentiment analysis for Bangla, such as the language's complex grammar, use of colloquialisms, and lack of standardized spelling conventions. They discussed how these factors can impact the performance of AI models and the need for more robust natural language processing techniques tailored to the Bangla language.
Critical Analysis
The paper provides a valuable contribution to the field of sentiment analysis for low-resource languages like Bangla. The creation of a benchmark dataset of Bangla food reviews is a significant step forward, as it enables researchers to evaluate and compare the performance of different AI models on a common task and dataset.
However, the paper could have benefited from a more in-depth discussion of the limitations and potential biases in the dataset. For example, the researchers did not provide information on the demographic diversity of the review authors or the geographical distribution of the reviews, which could influence the sentiment patterns captured in the data.
Additionally, the paper focuses solely on food reviews, which may not be representative of Bangla text data in general. Expanding the dataset to cover a wider range of domains and genres could lead to a more comprehensive understanding of sentiment analysis challenges in the Bangla language.
Despite these minor limitations, the paper serves as an important step towards improving natural language processing capabilities for the Bangla language. The insights gained from this research could inform the development of more accurate and robust sentiment analysis tools, which could have significant practical applications in areas such as customer service, product reviews, and social media analytics.
Conclusion
This paper presents a study on sentiment polarity analysis of Bangla food reviews using machine and deep learning algorithms. The researchers developed a benchmark dataset and evaluated the performance of various AI models, finding that deep learning approaches, particularly BERT-based models, outperformed traditional machine learning methods.
The study provides valuable insights into the challenges and opportunities in sentiment analysis for the Bangla language, which could inform the development of more advanced natural language processing tools and applications. As more datasets and models become available for low-resource languages like Bangla, there is great potential to improve our understanding of how to effectively analyze and interpret sentiment in diverse linguistic contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sentiment Polarity Analysis of Bangla Food Reviews Using Machine and Deep Learning Algorithms
Al Amin, Anik Sarkar, Md Mahamodul Islam, Asif Ahammad Miazee, Md Robiul Islam, Md Mahmudul Hoque
The Internet has become an essential tool for people in the modern world. Humans, like all living organisms, have essential requirements for survival. These include access to atmospheric oxygen, potable water, protective shelter, and sustenance. The constant flux of the world is making our existence less complicated. A significant portion of the population utilizes online food ordering services to have meals delivered to their residences. Although there are numerous methods for ordering food, customers sometimes experience disappointment with the food they receive. Our endeavor was to establish a model that could determine if food is of good or poor quality. We compiled an extensive dataset of over 1484 online reviews from prominent food ordering platforms, including Food Panda and HungryNaki. Leveraging the collected data, a rigorous assessment of various deep learning and machine learning techniques was performed to determine the most accurate approach for predicting food quality. Out of all the algorithms evaluated, logistic regression emerged as the most accurate, achieving an impressive 90.91% accuracy. The review offers valuable insights that will guide the user in deciding whether or not to order the food.
Read more5/14/2024
🔎
0
Bengali Fake Reviews: A Benchmark Dataset and Detection System
G. M. Shahariar, Md. Tanvir Rouf Shawon, Faisal Muhammad Shah, Mohammad Shafiul Alam, Md. Shahriar Mahbub
The proliferation of fake reviews on various online platforms has created a major concern for both consumers and businesses. Such reviews can deceive customers and cause damage to the reputation of products or services, making it crucial to identify them. Although the detection of fake reviews has been extensively studied in English language, detecting fake reviews in non-English languages such as Bengali is still a relatively unexplored research area. This paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in Bengali. The dataset consists of 7710 non-fake and 1339 fake food-related reviews collected from social media posts. To convert non-Bengali words in a review, a unique pipeline has been proposed that translates English words to their corresponding Bengali meaning and also back transliterates Romanized Bengali to Bengali. We have conducted rigorous experimentation using multiple deep learning and pre-trained transformer language models to develop a reliable detection system. Finally, we propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator . According to the experiment results, the proposed ensemble model obtained a weighted F1-score of 0.9843 on 13390 reviews, including 1339 actual fake reviews and 5356 augmented fake reviews generated with the nlpaug library. The remaining 6695 reviews were randomly selected from the 7710 non-fake instances. The model achieved a 0.9558 weighted F1-score when the fake reviews were augmented using the bnaug library.
Read more5/7/2024
💬
0
Sentiment Analysis of Lithuanian Online Reviews Using Large Language Models
Brigita Vileikyt.e, Mantas Lukov{s}eviv{c}ius, Lukas Stankeviv{c}ius
Sentiment analysis is a widely researched area within Natural Language Processing (NLP), attracting significant interest due to the advent of automated solutions. Despite this, the task remains challenging because of the inherent complexity of languages and the subjective nature of sentiments. It is even more challenging for less-studied and less-resourced languages such as Lithuanian. Our review of existing Lithuanian NLP research reveals that traditional machine learning methods and classification algorithms have limited effectiveness for the task. In this work, we address sentiment analysis of Lithuanian five-star-based online reviews from multiple domains that we collect and clean. We apply transformer models to this task for the first time, exploring the capabilities of pre-trained multilingual Large Language Models (LLMs), specifically focusing on fine-tuning BERT and T5 models. Given the inherent difficulty of the task, the fine-tuned models perform quite well, especially when the sentiments themselves are less ambiguous: 80.74% and 89.61% testing recognition accuracy of the most popular one- and five-star reviews respectively. They significantly outperform current commercial state-of-the-art general-purpose LLM GPT-4. We openly share our fine-tuned LLMs online.
Read more7/30/2024
⚙️
0
Zero- and Few-Shot Prompting with LLMs: A Comparative Study with Fine-tuned Models for Bangla Sentiment Analysis
Md. Arid Hasan, Shudipta Das, Afiyat Anjum, Firoj Alam, Anika Anjum, Avijit Sarker, Sheak Rashed Haider Noori
The rapid expansion of the digital world has propelled sentiment analysis into a critical tool across diverse sectors such as marketing, politics, customer service, and healthcare. While there have been significant advancements in sentiment analysis for widely spoken languages, low-resource languages, such as Bangla, remain largely under-researched due to resource constraints. Furthermore, the recent unprecedented performance of Large Language Models (LLMs) in various applications highlights the need to evaluate them in the context of low-resource languages. In this study, we present a sizeable manually annotated dataset encompassing 33,606 Bangla news tweets and Facebook comments. We also investigate zero- and few-shot in-context learning with several language models, including Flan-T5, GPT-4, and Bloomz, offering a comparative analysis against fine-tuned models. Our findings suggest that monolingual transformer-based models consistently outperform other models, even in zero and few-shot scenarios. To foster continued exploration, we intend to make this dataset and our research tools publicly available to the broader research community.
Read more4/8/2024