BetaZero: Belief-State Planning for Long-Horizon POMDPs using Learned Approximations

0
🌿
Sign in to get full access
Overview
- The paper discusses how real-world planning problems, such as autonomous driving and sustainable energy applications, can be modeled as partially observable Markov decision processes (POMDPs).
- To solve high-dimensional POMDPs in practice, state-of-the-art methods use online planning with problem-specific heuristics to reduce planning horizons and make the problems tractable.
- The paper proposes a new algorithm, called BetaZero, that learns offline approximations to replace heuristics and enable online decision-making in long-horizon POMDP problems.
Plain English Explanation
Many real-world problems, like autonomous driving and carbon storage, can be modeled as partially observable Markov decision processes (POMDPs). This means that the agent (e.g., a self-driving car or a robot) doesn't have complete information about the environment, but has to make decisions based on the limited information it can observe.
To solve these complex POMDP problems in practice, researchers have been using online planning methods that combine Monte Carlo tree search with problem-specific heuristics. This helps reduce the planning horizon and make the problems more manageable.
The key insight from the paper is to take a different approach: instead of relying on hand-crafted heuristics, the authors propose BetaZero, a system that learns these approximations offline. This allows the agent to make better decisions in long-horizon POMDP problems, like mineral exploration, without being constrained by the limitations of heuristics.
Technical Explanation
The paper proposes a new algorithm called BetaZero that combines online Monte Carlo tree search with offline neural network approximations of the optimal policy and value function. This approach enables efficient decision-making in high-dimensional POMDP problems.
To address the challenges of partially observable domains, such as stochastic transitions, limited search budgets, and belief representation, the authors make several key contributions:
- Q-weighted visit counts policy: The authors train the neural network approximations against a novel policy that prioritizes actions based on a combination of their Q-values and visit counts during the search, ensuring the network learns from all the available information.
- Belief representation: The authors develop a compact representation of the belief state (the agent's understanding of the current state of the environment) that can be efficiently used as input to the neural network.
- Empirical evaluation: The authors test BetaZero on various POMDP benchmarks and a real-world problem of critical mineral exploration, showing that it outperforms state-of-the-art POMDP solvers.
Critical Analysis
The paper presents a compelling approach to solving high-dimensional POMDP problems, which are prevalent in many real-world applications. The authors acknowledge several limitations and areas for future research:
- Generalization to diverse POMDP domains: While BetaZero demonstrates strong performance on the tested benchmarks, the authors note that the method may not generalize equally well to all POMDP domains, which can vary significantly in their structure and complexity.
- Scalability for very large POMDPs: The authors mention that the offline training of the neural network approximations can be computationally expensive for extremely large POMDP problems, which may limit the scalability of the approach.
- Interpretability of the learned approximations: The paper does not discuss the interpretability of the learned neural network approximations, which could be an important consideration for real-world applications where transparency and explainability are crucial.
Further research could explore ways to address these limitations, such as investigating techniques to improve the generalization of the method, optimizing the offline training process, and developing methods to enhance the interpretability of the learned approximations.
Conclusion
The paper presents a novel algorithm, BetaZero, that combines online Monte Carlo tree search with offline neural network approximations to solve high-dimensional POMDP problems. This approach addresses the limitations of traditional methods that rely on hand-crafted heuristics, enabling more efficient decision-making in long-horizon problems across a variety of domains, including autonomous driving, sustainable energy applications, and critical mineral exploration.
The proposed techniques, such as the Q-weighted visit counts policy and the compact belief representation, demonstrate the potential for learning-based approaches to enhance the performance of POMDP solvers. As real-world planning problems become increasingly complex, the insights from this research could have significant implications for the development of more capable and adaptable decision-making systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
BetaZero: Belief-State Planning for Long-Horizon POMDPs using Learned Approximations
Robert J. Moss, Anthony Corso, Jef Caers, Mykel J. Kochenderfer
Real-world planning problems, including autonomous driving and sustainable energy applications like carbon storage and resource exploration, have recently been modeled as partially observable Markov decision processes (POMDPs) and solved using approximate methods. To solve high-dimensional POMDPs in practice, state-of-the-art methods use online planning with problem-specific heuristics to reduce planning horizons and make the problems tractable. Algorithms that learn approximations to replace heuristics have recently found success in large-scale fully observable domains. The key insight is the combination of online Monte Carlo tree search with offline neural network approximations of the optimal policy and value function. In this work, we bring this insight to partially observable domains and propose BetaZero, a belief-state planning algorithm for high-dimensional POMDPs. BetaZero learns offline approximations that replace heuristics to enable online decision making in long-horizon problems. We address several challenges inherent in large-scale partially observable domains; namely challenges of transitioning in stochastic environments, prioritizing action branching with a limited search budget, and representing beliefs as input to the network. To formalize the use of all limited search information, we train against a novel $Q$-weighted visit counts policy. We test BetaZero on various well-established POMDP benchmarks found in the literature and a real-world problem of critical mineral exploration. Experiments show that BetaZero outperforms state-of-the-art POMDP solvers on a variety of tasks.
Read more8/1/2024

0
Learning Online Belief Prediction for Efficient POMDP Planning in Autonomous Driving
Zhiyu Huang, Chen Tang, Chen Lv, Masayoshi Tomizuka, Wei Zhan
Effective decision-making in autonomous driving relies on accurate inference of other traffic agents' future behaviors. To achieve this, we propose an online belief-update-based behavior prediction model and an efficient planner for Partially Observable Markov Decision Processes (POMDPs). We develop a Transformer-based prediction model, enhanced with a recurrent neural memory model, to dynamically update latent belief state and infer the intentions of other agents. The model can also integrate the ego vehicle's intentions to reflect closed-loop interactions among agents, and it learns from both offline data and online interactions. For planning, we employ a Monte-Carlo Tree Search (MCTS) planner with macro actions, which reduces computational complexity by searching over temporally extended action steps. Inside the MCTS planner, we use predicted long-term multi-modal trajectories to approximate future updates, which eliminates iterative belief updating and improves the running efficiency. Our approach also incorporates deep Q-learning (DQN) as a search prior, which significantly improves the performance of the MCTS planner. Experimental results from simulated environments validate the effectiveness of our proposed method. The online belief update model can significantly enhance the accuracy and temporal consistency of predictions, leading to improved decision-making performance. Employing DQN as a search prior in the MCTS planner considerably boosts its performance and outperforms an imitation learning-based prior. Additionally, we show that the MCTS planning with macro actions substantially outperforms the vanilla method in terms of performance and efficiency.
Read more6/19/2024
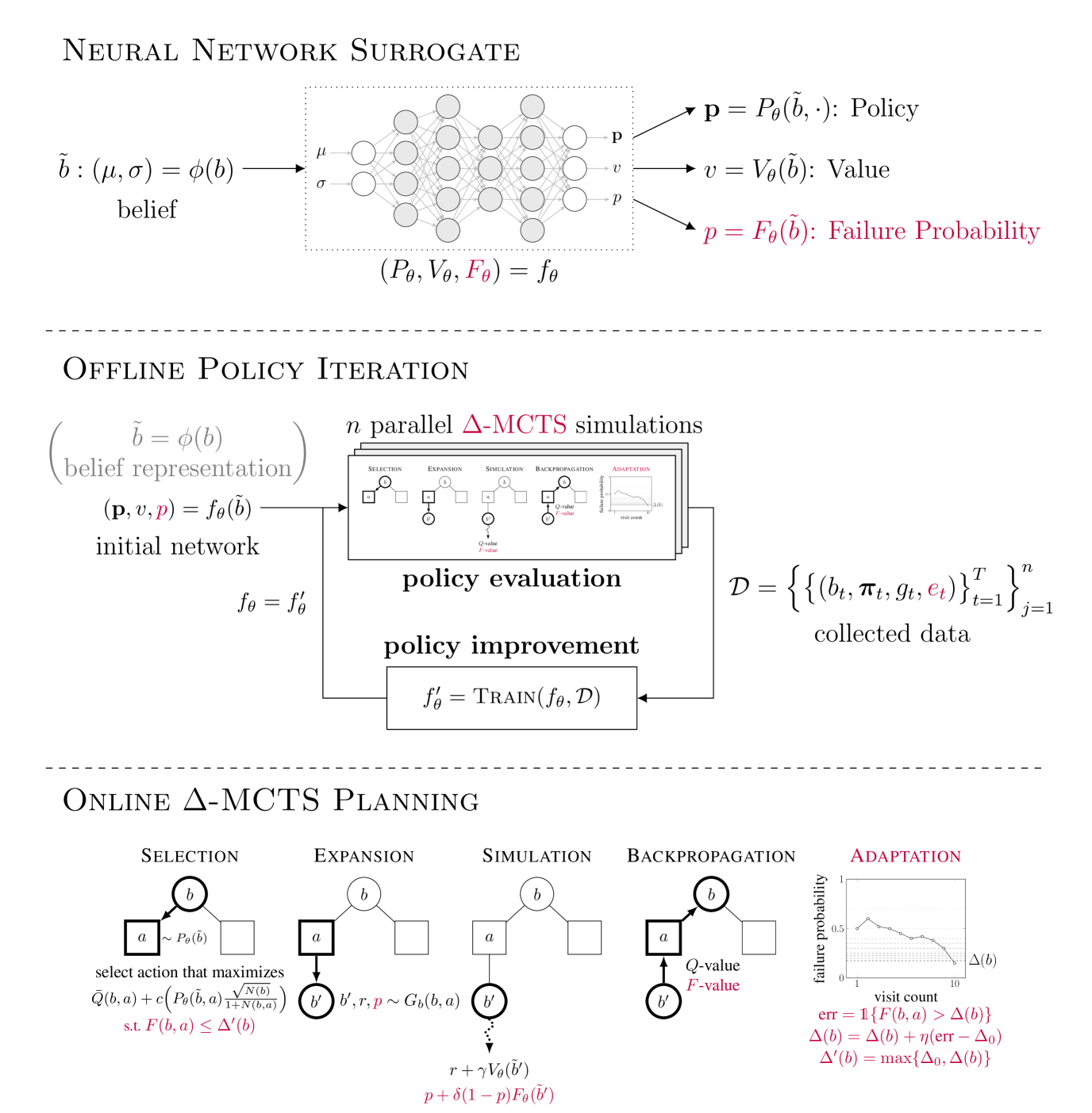
0
ConstrainedZero: Chance-Constrained POMDP Planning using Learned Probabilistic Failure Surrogates and Adaptive Safety Constraints
Robert J. Moss, Arec Jamgochian, Johannes Fischer, Anthony Corso, Mykel J. Kochenderfer
To plan safely in uncertain environments, agents must balance utility with safety constraints. Safe planning problems can be modeled as a chance-constrained partially observable Markov decision process (CC-POMDP) and solutions often use expensive rollouts or heuristics to estimate the optimal value and action-selection policy. This work introduces the ConstrainedZero policy iteration algorithm that solves CC-POMDPs in belief space by learning neural network approximations of the optimal value and policy with an additional network head that estimates the failure probability given a belief. This failure probability guides safe action selection during online Monte Carlo tree search (MCTS). To avoid overemphasizing search based on the failure estimates, we introduce $Delta$-MCTS, which uses adaptive conformal inference to update the failure threshold during planning. The approach is tested on a safety-critical POMDP benchmark, an aircraft collision avoidance system, and the sustainability problem of safe CO$_2$ storage. Results show that by separating safety constraints from the objective we can achieve a target level of safety without optimizing the balance between rewards and costs.
Read more5/2/2024
🏅
0
Provable Representation with Efficient Planning for Partial Observable Reinforcement Learning
Hongming Zhang, Tongzheng Ren, Chenjun Xiao, Dale Schuurmans, Bo Dai
In most real-world reinforcement learning applications, state information is only partially observable, which breaks the Markov decision process assumption and leads to inferior performance for algorithms that conflate observations with state. Partially Observable Markov Decision Processes (POMDPs), on the other hand, provide a general framework that allows for partial observability to be accounted for in learning, exploration and planning, but presents significant computational and statistical challenges. To address these difficulties, we develop a representation-based perspective that leads to a coherent framework and tractable algorithmic approach for practical reinforcement learning from partial observations. We provide a theoretical analysis for justifying the statistical efficiency of the proposed algorithm, and also empirically demonstrate the proposed algorithm can surpass state-of-the-art performance with partial observations across various benchmarks, advancing reliable reinforcement learning towards more practical applications.
Read more6/12/2024