LLM as a Scorer: The Impact of Output Order on Dialogue Evaluation
2406.02863
0
0
Abstract
This research investigates the effect of prompt design on dialogue evaluation using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for dialogue evaluation remains challenging due to model sensitivity and subjectivity in dialogue assessments. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a reason-first approach yielding more comprehensive evaluations. This insight is crucial for enhancing the accuracy and consistency of LLM-based evaluations.
Create account to get full access
Overview
- The paper examines the impact of output order on dialogue evaluation using large language models (LLMs) as scorers.
- It investigates how the order in which dialogue responses are presented to an LLM can influence the model's assessment of their quality.
- The research aims to understand the potential biases introduced by the order of dialogue outputs when using LLMs for automated dialogue evaluation.
Plain English Explanation
When using large language models to evaluate the quality of dialogues, the order in which the dialogue responses are presented to the model can impact the model's assessment. This paper explores how the output order can introduce biases and affect the reliability of dialogue evaluation using LLMs.
Imagine you're grading a set of essays, and the order in which you read them can influence your perception of their quality. Similarly, the order of dialogue responses presented to an LLM can sway its evaluation, leading to potentially inaccurate or biased assessments. The researchers aimed to understand and quantify this effect, which is an important consideration when using LLMs for automated dialogue evaluation.
Technical Explanation
The paper investigates the impact of output order on dialogue evaluation using LLMs as scorers. The researchers designed an experiment to assess how the order in which dialogue responses are presented to an LLM can influence the model's assessment of their quality.
The experiment involved several steps:
- Collecting a dataset of human-generated dialogue responses for a given task.
- Creating different orderings of the dialogue responses, such as random, ascending, and descending order.
- Presenting the dialogue responses in these different orders to a pre-trained LLM and having it score the quality of each response.
- Analyzing the differences in the LLM's scores across the various ordering conditions to understand the impact of output order on the evaluation.
The findings suggest that the order in which dialogue responses are presented to the LLM can significantly influence its assessment of the responses' quality. The researchers observed systematic biases in the LLM's scores, with higher scores being assigned to responses presented in ascending order and lower scores for responses in descending order.
These results highlight the importance of considering the potential biases introduced by output order when using LLMs for automated dialogue evaluation. The order of data presented to an LLM can impact its performance and the reliability of the evaluation, which is an important factor to account for in practical applications.
Critical Analysis
The paper acknowledges several limitations and areas for further research. For instance, the experiment was conducted using a single pre-trained LLM, and it would be valuable to explore the generalizability of the findings across different LLM architectures and dialogue domains.
Additionally, the paper does not delve into the underlying mechanisms or cognitive biases that might be driving the observed order effects. Further research could investigate the cognitive processes and biases within LLMs that lead to these order-dependent evaluation biases.
The authors also note that the magnitude of the order effects may vary depending on the specific dialogue task and the quality of the responses. It would be worthwhile to explore the interplay between output order, response quality, and the LLM's evaluation in more depth.
Conclusion
This study highlights the importance of considering the impact of output order when using LLMs for automated dialogue evaluation. The findings suggest that the order in which dialogue responses are presented to an LLM can introduce systematic biases in the model's assessment of their quality.
These insights have important implications for the design and interpretation of LLM-based dialogue evaluation systems, as the reliability and fairness of the evaluation can be influenced by the order of the outputs. Researchers and practitioners should be mindful of these order effects when developing and deploying LLM-based dialogue evaluation tools.
Overall, this paper contributes to our understanding of the potential pitfalls and limitations of using LLMs as dialogue scorers, paving the way for more robust and reliable approaches to automated dialogue evaluation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
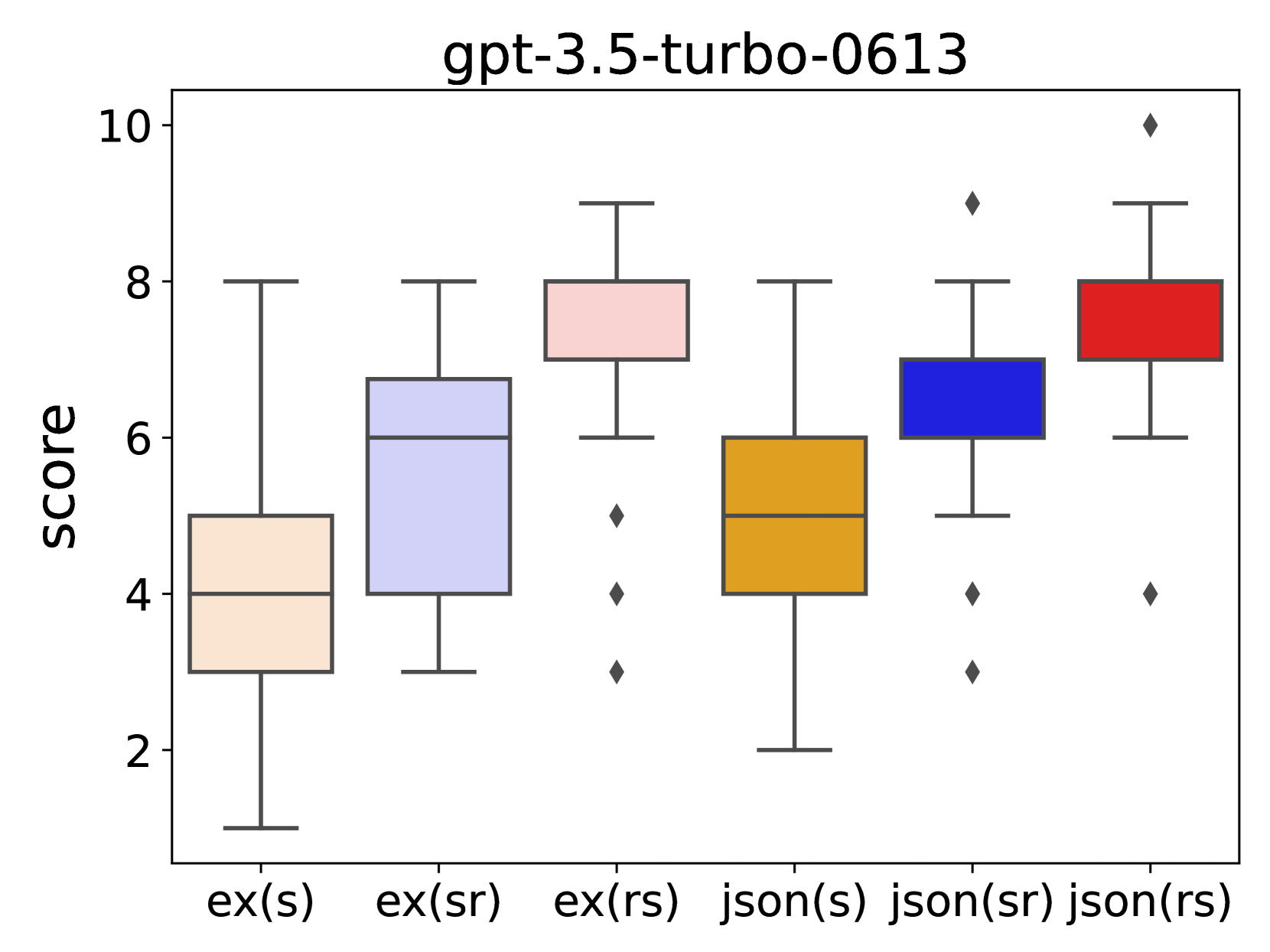
A Better LLM Evaluator for Text Generation: The Impact of Prompt Output Sequencing and Optimization
KuanChao Chu, Yi-Pei Chen, Hideki Nakayama
0
0
This research investigates prompt designs of evaluating generated texts using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for open-ended text evaluation remains challenging due to model sensitivity and subjectivity in evaluation of text generation. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a different level of rule understanding in the prompt. An additional optimization may enhance scoring alignment if sufficient data is available. This insight is crucial for improving the accuracy and consistency of LLM-based evaluations.
6/17/2024

Set-Based Prompting: Provably Solving the Language Model Order Dependency Problem
Reid McIlroy-Young, Katrina Brown, Conlan Olson, Linjun Zhang, Cynthia Dwork
0
0
The development of generative language models that can create long and coherent textual outputs via autoregression has lead to a proliferation of uses and a corresponding sweep of analyses as researches work to determine the limitations of this new paradigm. Unlike humans, these 'Large Language Models' (LLMs) are highly sensitive to small changes in their inputs, leading to unwanted inconsistency in their behavior. One problematic inconsistency when LLMs are used to answer multiple-choice questions or analyze multiple inputs is order dependency: the output of an LLM can (and often does) change significantly when sub-sequences are swapped, despite both orderings being semantically identical. In this paper we present Set-Based Prompting, a technique that guarantees the output of an LLM will not have order dependence on a specified set of sub-sequences. We show that this method provably eliminates order dependency, and that it can be applied to any transformer-based LLM to enable text generation that is unaffected by re-orderings. Delving into the implications of our method, we show that, despite our inputs being out of distribution, the impact on expected accuracy is small, where the expectation is over the order of uniformly chosen shuffling of the candidate responses, and usually significantly less in practice. Thus, Set-Based Prompting can be used as a 'dropped-in' method on fully trained models. Finally, we discuss how our method's success suggests that other strong guarantees can be obtained on LLM performance via modifying the input representations.
6/13/2024
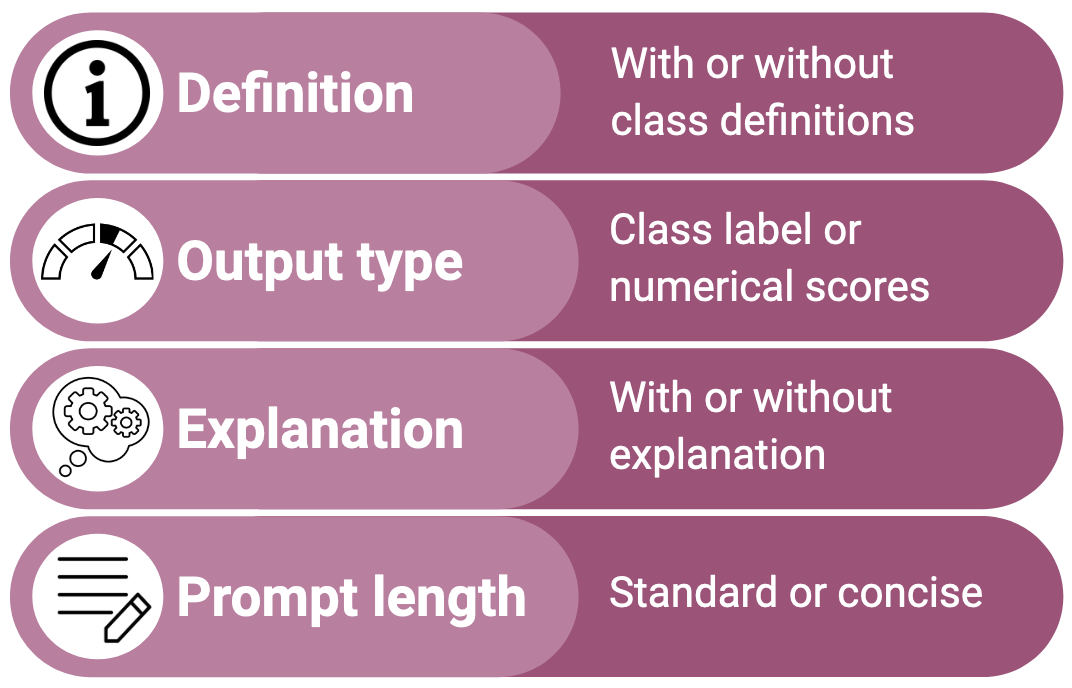
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024
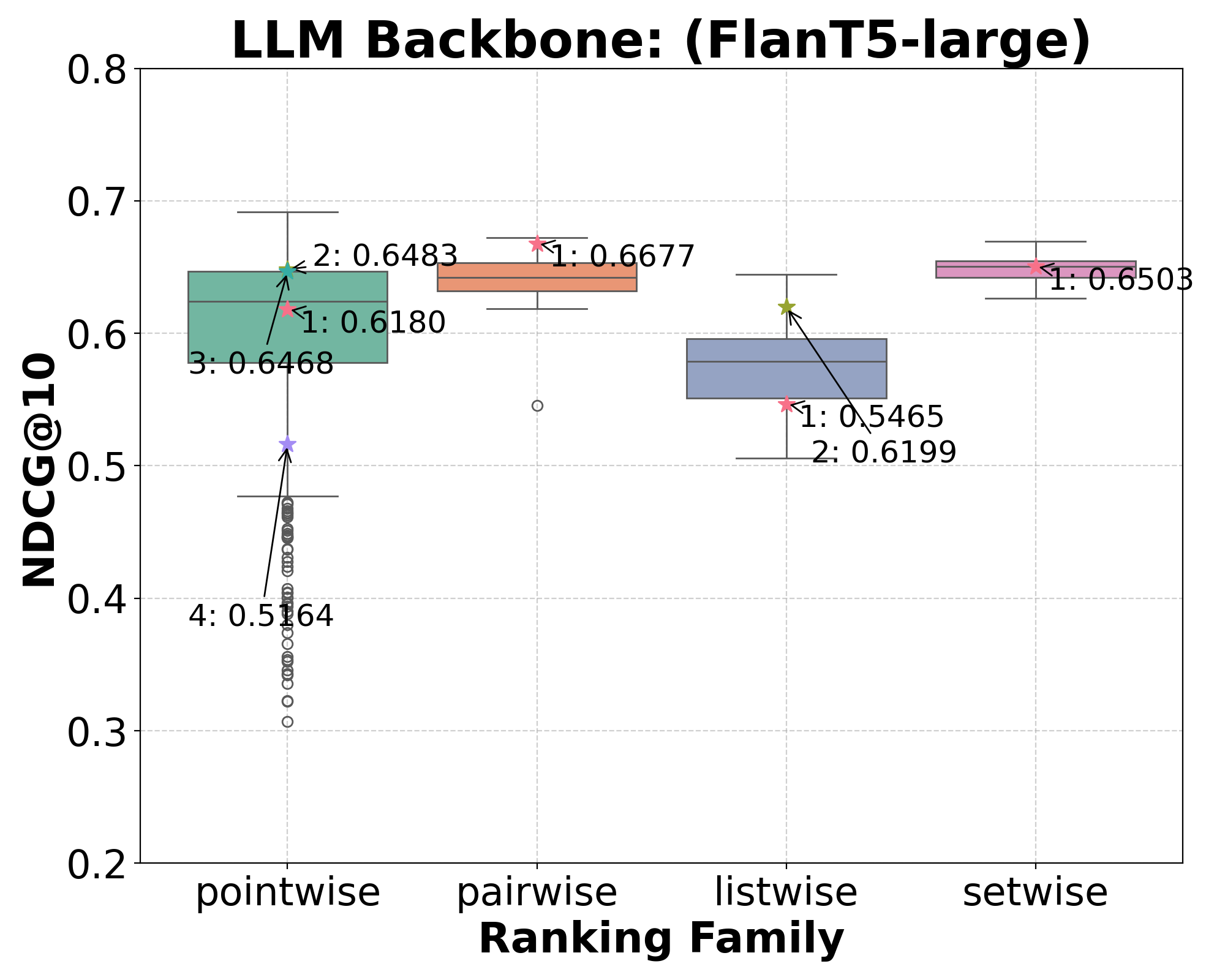
An Investigation of Prompt Variations for Zero-shot LLM-based Rankers
Shuoqi Sun, Shengyao Zhuang, Shuai Wang, Guido Zuccon
0
0
We provide a systematic understanding of the impact of specific components and wordings used in prompts on the effectiveness of rankers based on zero-shot Large Language Models (LLMs). Several zero-shot ranking methods based on LLMs have recently been proposed. Among many aspects, methods differ across (1) the ranking algorithm they implement, e.g., pointwise vs. listwise, (2) the backbone LLMs used, e.g., GPT3.5 vs. FLAN-T5, (3) the components and wording used in prompts, e.g., the use or not of role-definition (role-playing) and the actual words used to express this. It is currently unclear whether performance differences are due to the underlying ranking algorithm, or because of spurious factors such as better choice of words used in prompts. This confusion risks to undermine future research. Through our large-scale experimentation and analysis, we find that ranking algorithms do contribute to differences between methods for zero-shot LLM ranking. However, so do the LLM backbones -- but even more importantly, the choice of prompt components and wordings affect the ranking. In fact, in our experiments, we find that, at times, these latter elements have more impact on the ranker's effectiveness than the actual ranking algorithms, and that differences among ranking methods become more blurred when prompt variations are considered.
6/21/2024