Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models
2311.16254
0
0
🤿
Abstract
Large-scale vision-and-language models, such as CLIP, are typically trained on web-scale data, which can introduce inappropriate content and lead to the development of unsafe and biased behavior. This, in turn, hampers their applicability in sensitive and trustworthy contexts and could raise significant concerns in their adoption. Our research introduces a novel approach to enhancing the safety of vision-and-language models by diminishing their sensitivity to NSFW (not safe for work) inputs. In particular, our methodology seeks to sever toxic linguistic and visual concepts, unlearning the linkage between unsafe linguistic or visual items and unsafe regions of the embedding space. We show how this can be done by fine-tuning a CLIP model on synthetic data obtained from a large language model trained to convert between safe and unsafe sentences, and a text-to-image generator. We conduct extensive experiments on the resulting embedding space for cross-modal retrieval, text-to-image, and image-to-text generation, where we show that our model can be remarkably employed with pre-trained generative models. Our source code and trained models are available at: https://github.com/aimagelab/safe-clip.
Create account to get full access
Overview
- Large-scale vision-and-language models, such as CLIP, are often trained on web-scale data, which can include inappropriate content and lead to unsafe and biased behavior.
- This can limit the applicability of these models in sensitive and trustworthy contexts.
- The research introduces a novel approach to enhance the safety of vision-and-language models by reducing their sensitivity to NSFW (not safe for work) inputs.
Plain English Explanation
Vision-and-language models are a type of artificial intelligence that can understand and generate both images and text. These models are often trained on vast amounts of data from the internet, which can sometimes include inappropriate or harmful content.
This can be a problem because it can cause the models to develop unsafe or biased behaviors, making them less suitable for use in sensitive or trustworthy applications. For example, a vision-and-language model trained on web data might learn to associate certain visual or textual cues with unsafe or unethical content, and then start producing that kind of content itself.
To address this issue, the researchers have developed a new approach to make these models safer and more trustworthy. Their key idea is to "unlearn" the connection between unsafe content and the model's internal representations, so that it becomes less sensitive to that kind of input.
They do this by fine-tuning the model on synthetic data that has been specifically designed to sever the links between unsafe linguistic and visual concepts and the model's embedding space (the way it represents and understands information). This helps the model become less likely to generate or be influenced by unsafe content.
The researchers show that this approach can be used to enhance the safety of vision-and-language models while still allowing them to be used with pre-trained generative models (models that can create new content) for tasks like text-to-image generation. Their work provides a promising strategy for making these powerful AI systems more trustworthy and applicable in sensitive contexts.
Technical Explanation
The researchers introduce a novel approach to enhance the safety of vision-and-language models, such as CLIP, by reducing their sensitivity to NSFW (not safe for work) inputs. Their methodology seeks to sever the linkage between unsafe linguistic and visual concepts and the unsafe regions of the model's embedding space.
To achieve this, the researchers fine-tune a CLIP model on synthetic data obtained from two key components:
- A large language model trained to convert between safe and unsafe sentences [Demystifying CLIP: Data].
- A text-to-image generator [Fooling Contrastive Language-Image Pre-trained Models, Scaling Down CLIP: A Comprehensive Analysis of Data and Architecture].
By fine-tuning the CLIP model on this synthetic data, the researchers are able to sever the toxic linguistic and visual concepts, effectively "unlearning" the association between unsafe content and the model's internal representations.
The researchers conduct extensive experiments on the resulting embedding space, evaluating its performance on cross-modal retrieval, text-to-image, and image-to-text generation tasks. They demonstrate that their "SafeGen" model can be remarkably employed with pre-trained generative models, while significantly reducing the model's sensitivity to NSFW inputs.
Critical Analysis
The researchers acknowledge several caveats and limitations in their work. First, they note that their approach relies on the availability of a large language model trained to convert between safe and unsafe sentences, which may not be readily available in all contexts.
Additionally, the researchers mention that their evaluation is primarily focused on the technical performance of the model, and does not deeply address the broader societal implications of deploying such systems. There may be concerns around the potential for unintended biases or edge cases that could arise, even with the safety enhancements.
Further research is needed to fully understand the robustness and generalizability of the SafeGen approach, as well as to explore additional strategies for enhancing the trustworthiness and safety of vision-and-language models more broadly. [Pay Attention to Your Neighbours: Training-free]
Conclusion
The researchers have introduced a novel approach to improve the safety of vision-and-language models, such as CLIP, by diminishing their sensitivity to NSFW inputs. Their SafeGen model is able to sever the linkage between unsafe linguistic and visual concepts and the model's embedding space, making it less likely to generate or be influenced by harmful content.
This work represents an important step towards developing more trustworthy and applicable AI systems for sensitive contexts. By enhancing the safety of these powerful vision-and-language models, the researchers are helping to pave the way for their wider adoption in a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
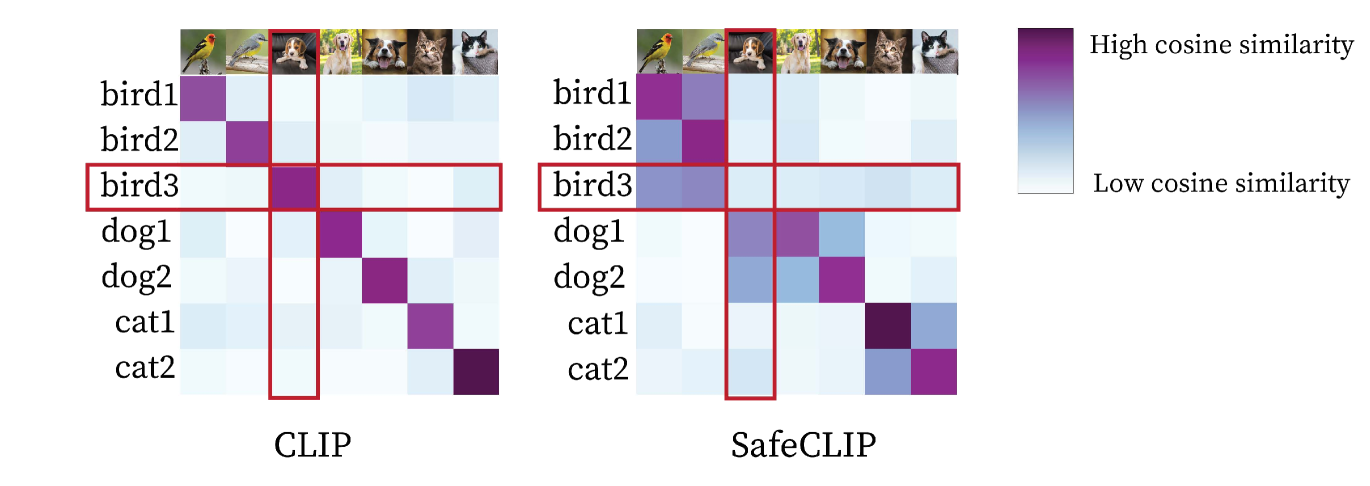
Better Safe than Sorry: Pre-training CLIP against Targeted Data Poisoning and Backdoor Attacks
Wenhan Yang, Jingdong Gao, Baharan Mirzasoleiman
0
0
Contrastive Language-Image Pre-training (CLIP) on large image-caption datasets has achieved remarkable success in zero-shot classification and enabled transferability to new domains. However, CLIP is extremely more vulnerable to targeted data poisoning and backdoor attacks, compared to supervised learning. Perhaps surprisingly, poisoning 0.0001% of CLIP pre-training data is enough to make targeted data poisoning attacks successful. This is four orders of magnitude smaller than what is required to poison supervised models. Despite this vulnerability, existing methods are very limited in defending CLIP models during pre-training. In this work, we propose a strong defense, SAFECLIP, to safely pre-train CLIP against targeted data poisoning and backdoor attacks. SAFECLIP warms up the model by applying unimodal contrastive learning (CL) on image and text modalities separately. Then, it divides the data into safe and risky sets, by applying a Gaussian Mixture Model to the cosine similarity of image-caption pair representations. SAFECLIP pre-trains the model by applying the CLIP loss to the safe set and applying unimodal CL to image and text modalities of the risky set separately. By gradually increasing the size of the safe set during pre-training, SAFECLIP effectively breaks targeted data poisoning and backdoor attacks without harming the CLIP performance. Our extensive experiments on CC3M, Visual Genome, and MSCOCO demonstrate that SAFECLIP significantly reduces the success rate of targeted data poisoning attacks from 93.75% to 0% and that of various backdoor attacks from up to 100% to 0%, without harming CLIP's performance.
6/12/2024

SafeGen: Mitigating Unsafe Content Generation in Text-to-Image Models
Xinfeng Li, Yuchen Yang, Jiangyi Deng, Chen Yan, Yanjiao Chen, Xiaoyu Ji, Wenyuan Xu
0
0
Text-to-image (T2I) models, such as Stable Diffusion, have exhibited remarkable performance in generating high-quality images from text descriptions in recent years. However, text-to-image models may be tricked into generating not-safe-for-work (NSFW) content, particularly in sexual scenarios. Existing countermeasures mostly focus on filtering inappropriate inputs and outputs, or suppressing improper text embeddings, which can block explicit NSFW-related content (e.g., naked or sexy) but may still be vulnerable to adversarial prompts inputs that appear innocent but are ill-intended. In this paper, we present SafeGen, a framework to mitigate unsafe content generation by text-to-image models in a text-agnostic manner. The key idea is to eliminate unsafe visual representations from the model regardless of the text input. In this way, the text-to-image model is resistant to adversarial prompts since unsafe visual representations are obstructed from within. Extensive experiments conducted on four datasets demonstrate SafeGen's effectiveness in mitigating unsafe content generation while preserving the high-fidelity of benign images. SafeGen outperforms eight state-of-the-art baseline methods and achieves 99.1% sexual content removal performance. Furthermore, our constructed benchmark of adversarial prompts provides a basis for future development and evaluation of anti-NSFW-generation methods.
4/11/2024

Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
Christian Schlarmann, Naman Deep Singh, Francesco Croce, Matthias Hein
0
0
Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many large vision-language models (LVLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (LVLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of LVLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the down-stream LVLMs is required. The code and robust models are available at https://github.com/chs20/RobustVLM
6/6/2024
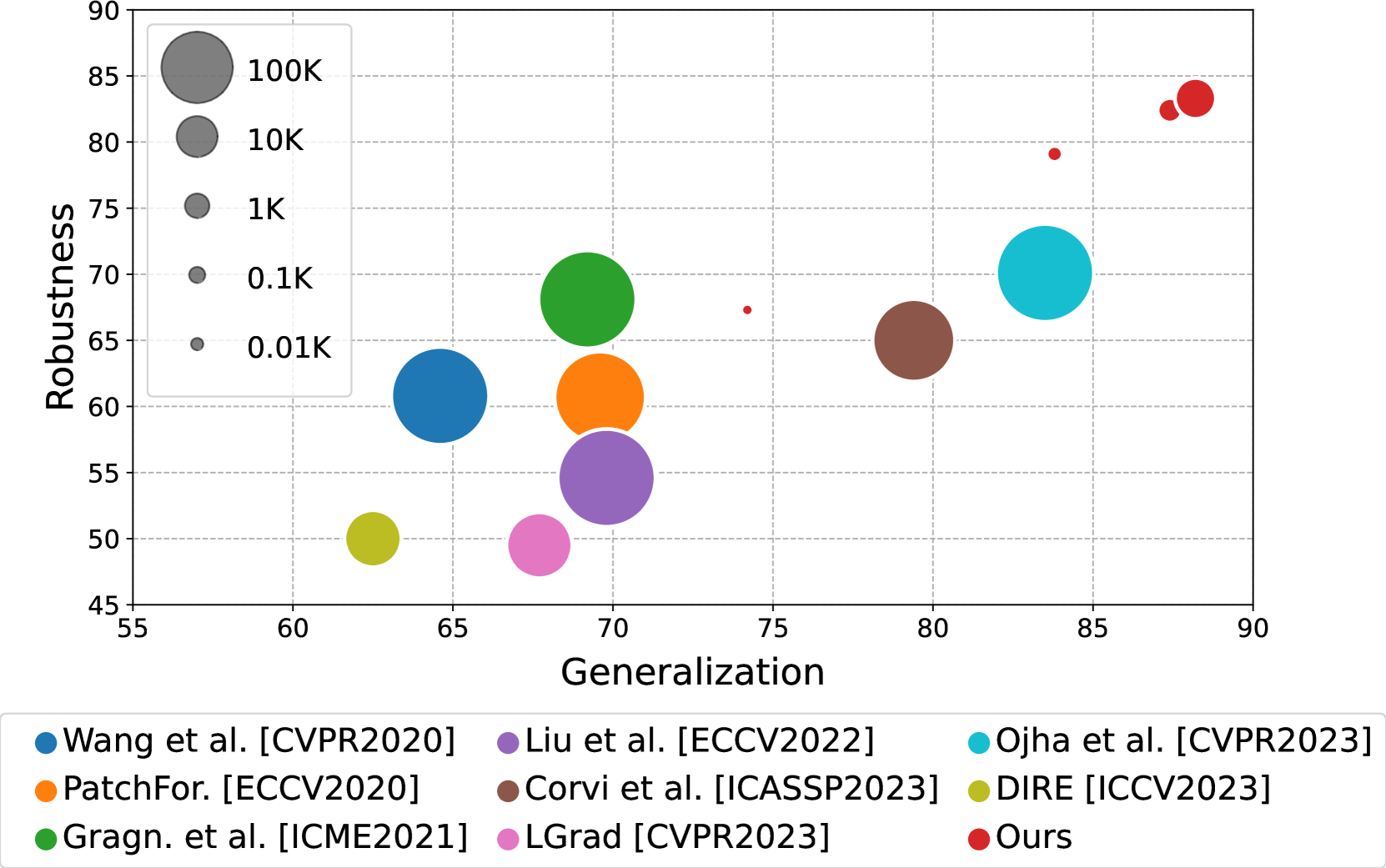
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
0
0
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
4/30/2024