BEVTrack: A Simple and Strong Baseline for 3D Single Object Tracking in Bird's-Eye View

0
📉
Sign in to get full access
Overview
- 3D Single Object Tracking (SOT) is a fundamental computer vision task critical for applications like autonomous driving
- Existing trackers struggle to accurately localize targets due to appearance changes, distracting objects, and sparse point cloud data
- The paper proposes BEVTrack, a simple yet effective baseline method that achieves state-of-the-art performance on benchmark datasets
Plain English Explanation
The paper discusses an important problem in computer vision called 3D Single Object Tracking (SOT). This task involves identifying and continuously following a specific object, like a car or pedestrian, as it moves through a 3D environment. It's a crucial capability for applications like self-driving cars, where accurately tracking nearby objects is essential for safe navigation.
However, 3D SOT remains a challenging problem. The appearance of the target object can change over time, making it harder to recognize. There may also be other similar-looking objects in the scene that can distract the tracker. Additionally, the data from 3D sensors like LIDAR is often very sparse, making it difficult to precisely localize the target.
To address these challenges, the researchers propose a new method called BEVTrack. BEVTrack takes a unique approach by estimating the target's motion in a Bird's-Eye View (BEV) representation of the environment. This simplifies the tracking problem and allows BEVTrack to achieve state-of-the-art performance using a straightforward network design and training process.
A key innovation is that BEVTrack constructs a "likelihood function" that adapts to the specific characteristics of each target, such as its size and motion patterns. This provides valuable prior information to improve the tracking accuracy, rather than relying on a one-size-fits-all assumption like previous methods.
Overall, BEVTrack demonstrates that a simple and efficient approach can outperform more complex tracking systems, opening up new possibilities for real-world applications like autonomous driving, road surface reconstruction, and semantic segmentation that rely on accurate 3D object tracking.
Technical Explanation
The paper proposes a novel 3D Single Object Tracking (SOT) method called BEVTrack. Unlike previous Siamese and motion-centric trackers that require complex designs and solving multiple subtasks, BEVTrack demonstrates surprising simplicity across its network architecture, training objectives, and tracking pipeline.
The key idea behind BEVTrack is to estimate the target's motion in a Bird's-Eye View (BEV) representation of the environment. This allows the tracker to focus on the target's 2D position and scale changes, which are often more reliable cues than appearance-based features, especially in cluttered scenes with distractors.
To achieve accurate regression for targets with diverse attributes (e.g., size, motion patterns), BEVTrack constructs a likelihood function that adapts to the learned underlying distributions of different targets. This is in contrast to previous methods that make fixed Laplacian or Gaussian assumptions, which may not capture the true complexity of real-world targets.
Experiments on three large-scale 3D object tracking datasets (KITTI, NuScenes, and Waymo Open Dataset) show that BEVTrack achieves state-of-the-art performance while maintaining a high inference speed of around 200 FPS. This demonstrates the effectiveness of the proposed approach and its potential for real-time applications like autonomous vehicles.
Critical Analysis
The paper presents a compelling and well-designed solution to the challenging problem of 3D Single Object Tracking. The key strengths of the BEVTrack approach are its simplicity, efficiency, and ability to outperform more complex trackers on benchmark datasets.
One potential limitation is that the paper does not extensively explore the performance of BEVTrack in more realistic, dynamic environments with occlusions, lighting changes, and interactions between multiple objects. While the tested datasets provide a good starting point, further evaluation in more complex real-world scenarios would be valuable to fully assess the tracker's capabilities and limitations.
Additionally, the paper does not delve into the interpretability of the BEVTrack model or provide detailed analysis of the learned likelihood functions and their adaptation to different target attributes. Understanding these aspects could lead to further insights and potential improvements to the core tracking algorithm.
Overall, the BEVTrack method represents a significant contribution to the field of 3D object tracking, demonstrating that a simple and efficient approach can outperform more elaborate systems. The paper's findings encourage further research into streamlined, yet effective, tracking solutions that can be deployed in safety-critical applications like autonomous driving.
Conclusion
This paper presents BEVTrack, a novel and surprisingly simple 3D Single Object Tracking (SOT) method that achieves state-of-the-art performance on popular benchmark datasets. By estimating the target's motion in a Bird's-Eye View (BEV) representation, BEVTrack avoids the complexities of traditional Siamese and motion-centric trackers while maintaining high accuracy and inference speed.
A key innovation is BEVTrack's adaptive likelihood function, which captures the underlying distributions of different target attributes to provide valuable priors for improved tracking. This approach demonstrates the potential for leveraging learned target-specific information to enhance the overall tracking performance.
The findings in this paper have important implications for real-world applications that rely on accurate 3D object tracking, such as autonomous driving, road surface reconstruction, and semantic segmentation of urban environments. By offering a simple yet effective baseline, BEVTrack paves the way for further advancements in this critical computer vision task.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
BEVTrack: A Simple and Strong Baseline for 3D Single Object Tracking in Bird's-Eye View
Yuxiang Yang, Yingqi Deng, Jing Zhang, Jiahao Nie, Zheng-Jun Zha
3D Single Object Tracking (SOT) is a fundamental task of computer vision, proving essential for applications like autonomous driving. It remains challenging to localize the target from surroundings due to appearance variations, distractors, and the high sparsity of point clouds. To address these issues, prior Siamese and motion-centric trackers both require elaborate designs and solving multiple subtasks. In this paper, we propose BEVTrack, a simple yet effective baseline method. By estimating the target motion in Bird's-Eye View (BEV) to perform tracking, BEVTrack demonstrates surprising simplicity from various aspects, i.e., network designs, training objectives, and tracking pipeline, while achieving superior performance. Besides, to achieve accurate regression for targets with diverse attributes (e.g., sizes and motion patterns), BEVTrack constructs the likelihood function with the learned underlying distributions adapted to different targets, rather than making a fixed Laplacian or Gaussian assumption as in previous works. This provides valuable priors for tracking and thus further boosts performance. While only using a single regression loss with a plain convolutional architecture, BEVTrack achieves state-of-the-art performance on three large-scale datasets, KITTI, NuScenes, and Waymo Open Dataset while maintaining a high inference speed of about 200 FPS. The code will be released at https://github.com/xmm-prio/BEVTrack.
Read more5/21/2024
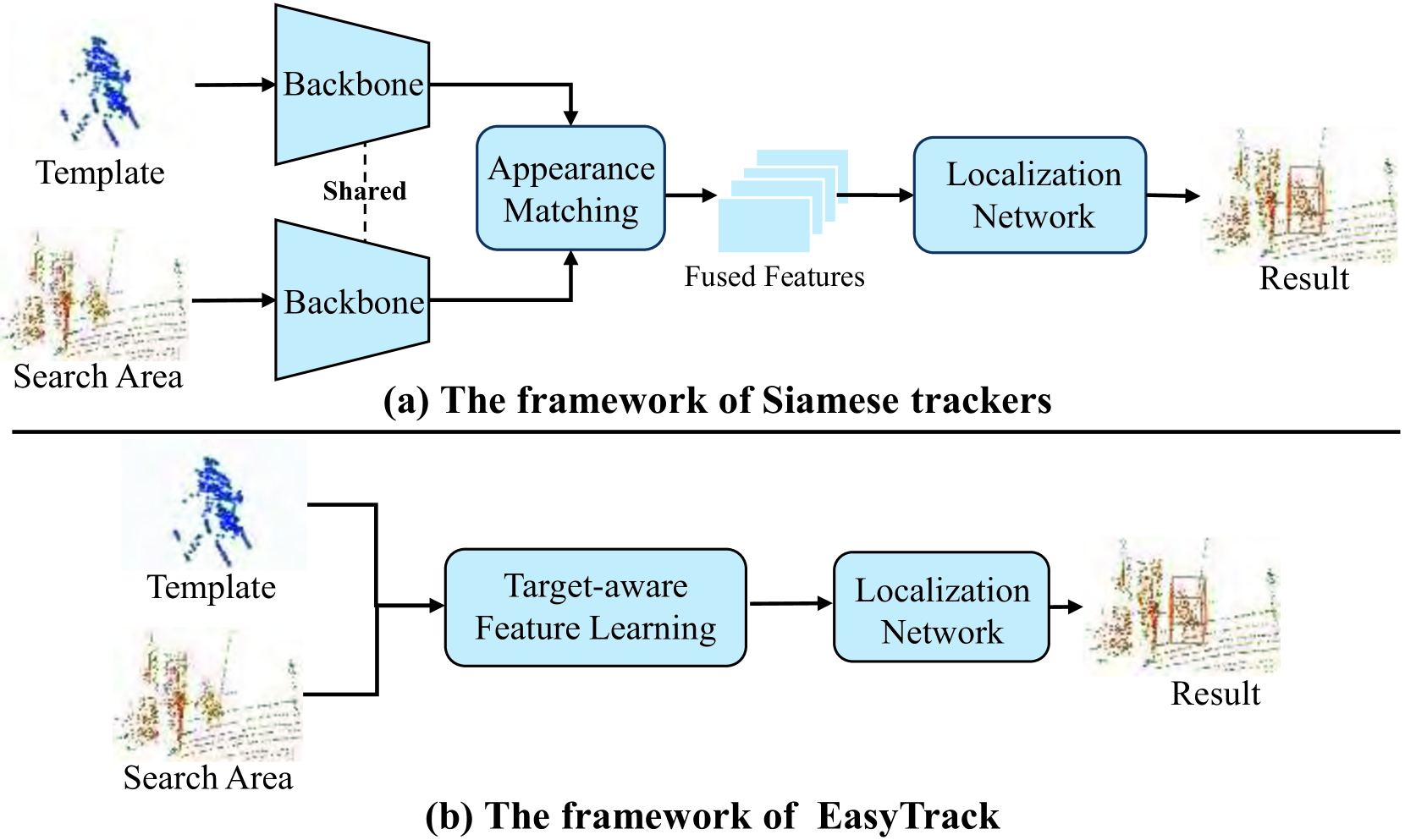
0
EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker
Baojie Fan, Wuyang Zhou, Kai Wang, Shijun Zhou, Fengyu Xu, Jiandong Tian
Most of 3D single object trackers (SOT) in point clouds follow the two-stream multi-stage 3D Siamese or motion tracking paradigms, which process the template and search area point clouds with two parallel branches, built on supervised point cloud backbones. In this work, beyond typical 3D Siamese or motion tracking, we propose a neat and compact one-stream transformer 3D SOT paradigm from the novel perspective, termed as textbf{EasyTrack}, which consists of three special designs: 1) A 3D point clouds tracking feature pre-training module is developed to exploit the masked autoencoding for learning 3D point clouds tracking representations. 2) A unified 3D tracking feature learning and fusion network is proposed to simultaneously learns target-aware 3D features, and extensively captures mutual correlation through the flexible self-attention mechanism. 3) A target location network in the dense bird's eye view (BEV) feature space is constructed for target classification and regression. Moreover, we develop an enhanced version named EasyTrack++, which designs the center points interaction (CPI) strategy to reduce the ambiguous targets caused by the noise point cloud background information. The proposed EasyTrack and EasyTrack++ set a new state-of-the-art performance ($textbf{18%}$, $textbf{40%}$ and $textbf{3%}$ success gains) in KITTI, NuScenes, and Waymo while runing at textbf{52.6fps} with few parameters (textbf{1.3M}). The code will be available at https://github.com/KnightApple427/Easytrack.
Read more4/15/2024
🤷
0
Fast-BEV: A Fast and Strong Bird's-Eye View Perception Baseline
Yangguang Li, Bin Huang, Zeren Chen, Yufeng Cui, Feng Liang, Mingzhu Shen, Fenggang Liu, Enze Xie, Lu Sheng, Wanli Ouyang, Jing Shao
Recently, perception task based on Bird's-Eye View (BEV) representation has drawn more and more attention, and BEV representation is promising as the foundation for next-generation Autonomous Vehicle (AV) perception. However, most existing BEV solutions either require considerable resources to execute on-vehicle inference or suffer from modest performance. This paper proposes a simple yet effective framework, termed Fast-BEV , which is capable of performing faster BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive transformer based transformation nor depth representation. Our Fast-BEV consists of five parts, We novelly propose (1) a lightweight deployment-friendly view transformation which fast transfers 2D image feature to 3D voxel space, (2) an multi-scale image encoder which leverages multi-scale information for better performance, (3) an efficient BEV encoder which is particularly designed to speed up on-vehicle inference. We further introduce (4) a strong data augmentation strategy for both image and BEV space to avoid over-fitting, (5) a multi-frame feature fusion mechanism to leverage the temporal information. Through experiments, on 2080Ti platform, our R50 model can run 52.6 FPS with 47.3% NDS on the nuScenes validation set, exceeding the 41.3 FPS and 47.5% NDS of the BEVDepth-R50 model and 30.2 FPS and 45.7% NDS of the BEVDet4D-R50 model. Our largest model (R101@900x1600) establishes a competitive 53.5% NDS on the nuScenes validation set. We further develop a benchmark with considerable accuracy and efficiency on current popular on-vehicle chips. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
Read more7/10/2024

0
Vision-Driven 2D Supervised Fine-Tuning Framework for Bird's Eye View Perception
Lei He, Qiaoyi Wang, Honglin Sun, Qing Xu, Bolin Gao, Shengbo Eben Li, Jianqiang Wang, Keqiang Li
Visual bird's eye view (BEV) perception, due to its excellent perceptual capabilities, is progressively replacing costly LiDAR-based perception systems, especially in the realm of urban intelligent driving. However, this type of perception still relies on LiDAR data to construct ground truth databases, a process that is both cumbersome and time-consuming. Moreover, most massproduced autonomous driving systems are only equipped with surround camera sensors and lack LiDAR data for precise annotation. To tackle this challenge, we propose a fine-tuning method for BEV perception network based on visual 2D semantic perception, aimed at enhancing the model's generalization capabilities in new scene data. Considering the maturity and development of 2D perception technologies, our method significantly reduces the dependency on high-cost BEV ground truths and shows promising industrial application prospects. Extensive experiments and comparative analyses conducted on the nuScenes and Waymo public datasets demonstrate the effectiveness of our proposed method.
Read more9/10/2024