EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker

0
Sign in to get full access
Overview
- Presents a new 3D point cloud tracking method called EasyTrack that is efficient and compact
- Uses a one-stream transformer-based architecture for single object tracking
- Leverages pre-training on large-scale 3D datasets to improve tracking performance
- Claims to outperform existing 3D tracking methods in accuracy and efficiency
Plain English Explanation
EasyTrack is a new system for tracking the movement of 3D objects, such as people or vehicles, using data from sensors like lidar. Unlike many existing 3D tracking approaches that use complex multi-stage pipelines, EasyTrack uses a simple one-stream transformer-based architecture. This means it can process the 3D point cloud data in a more efficient and compact way.
EasyTrack also takes advantage of pre-training on large-scale 3D datasets to help it learn features and patterns that are useful for tracking. This pre-training step allows EasyTrack to achieve higher accuracy compared to other 3D tracking methods, while still maintaining a lightweight and efficient design.
The key innovation in EasyTrack is its ability to perform accurate 3D tracking using a streamlined, one-shot approach, without requiring multiple specialized components. This makes it a compelling option for applications that need efficient 3D tracking, such as self-driving cars, robotics, or augmented reality.
Technical Explanation
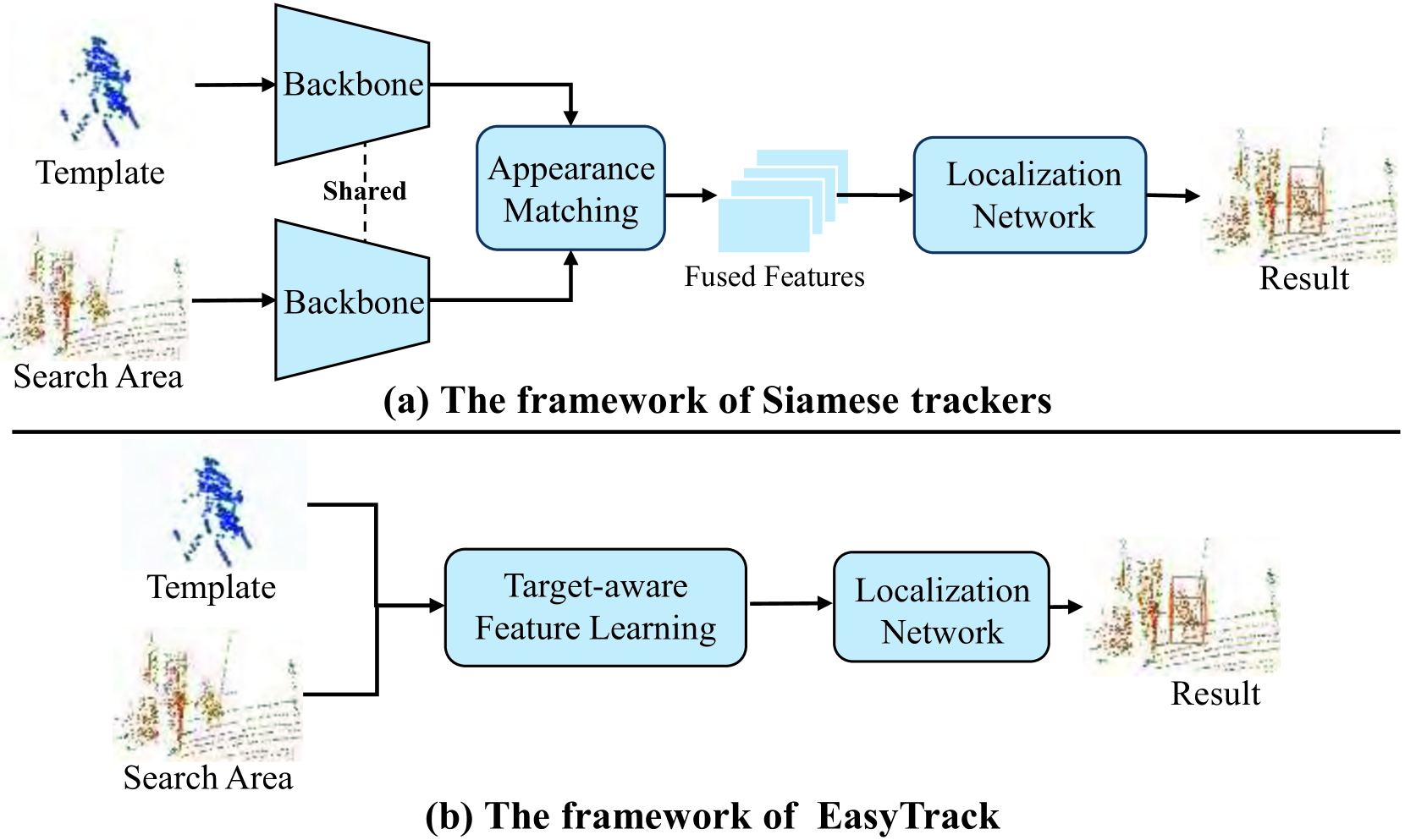
EasyTrack is a novel 3D point cloud tracking framework that uses a compact one-stream transformer-based architecture. Unlike traditional multi-stage 3D tracking pipelines, EasyTrack processes the entire 3D point cloud in a single pass using a transformer encoder-decoder model.
To improve tracking performance, the authors leverage pre-training on large-scale 3D datasets, similar to approaches used in 2D object detection and 3D scene flow estimation. This pre-training step allows EasyTrack to learn powerful representations of 3D shapes and motion, which can then be fine-tuned for the specific task of 3D tracking.
The compact one-stream design of EasyTrack is enabled by the use of a transformer architecture, which can efficiently capture both local and global dependencies in the 3D point cloud data. This is in contrast to other 3D tracking methods that often rely on more complex multi-branch neural network architectures.
Critical Analysis
The authors of the EasyTrack paper make a compelling case for their one-stream 3D tracking framework, demonstrating its efficiency and accuracy advantages over existing methods. However, the paper does not extensively explore the limitations or potential drawbacks of the approach.
One area that could merit further investigation is the scalability of EasyTrack to handle multiple, potentially occluded objects in a scene. The paper focuses on single-object tracking, and it's unclear how well the method would generalize to more complex multi-object tracking scenarios.
Additionally, the pre-training strategy used by EasyTrack, while effective, may require access to large-scale 3D datasets, which could limit its applicability in certain real-world scenarios where such data is scarce. Exploring alternative pre-training or data augmentation techniques could help address this potential limitation.
Overall, the EasyTrack paper presents a promising direction for efficient and accurate 3D point cloud tracking, but further research is needed to fully understand its capabilities and limitations across a broader range of tracking challenges.
Conclusion
The EasyTrack framework introduced in this paper represents a compelling advance in the field of 3D point cloud tracking. By leveraging a compact one-stream transformer-based architecture and pre-training on large-scale 3D datasets, EasyTrack is able to achieve state-of-the-art tracking performance while maintaining an efficient and lightweight design.
The key innovations of EasyTrack, such as its ability to process the entire 3D point cloud in a single pass and its use of transformer-based modeling, have the potential to enable new applications and use cases for 3D tracking technology, particularly in domains where computational efficiency and real-time performance are critical, such as autonomous vehicles, robotics, and augmented reality.
As the research in 3D perception and tracking continues to evolve, the EasyTrack approach and its underlying principles may inspire further developments and advancements in this important field of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker
Baojie Fan, Wuyang Zhou, Kai Wang, Shijun Zhou, Fengyu Xu, Jiandong Tian
Most of 3D single object trackers (SOT) in point clouds follow the two-stream multi-stage 3D Siamese or motion tracking paradigms, which process the template and search area point clouds with two parallel branches, built on supervised point cloud backbones. In this work, beyond typical 3D Siamese or motion tracking, we propose a neat and compact one-stream transformer 3D SOT paradigm from the novel perspective, termed as textbf{EasyTrack}, which consists of three special designs: 1) A 3D point clouds tracking feature pre-training module is developed to exploit the masked autoencoding for learning 3D point clouds tracking representations. 2) A unified 3D tracking feature learning and fusion network is proposed to simultaneously learns target-aware 3D features, and extensively captures mutual correlation through the flexible self-attention mechanism. 3) A target location network in the dense bird's eye view (BEV) feature space is constructed for target classification and regression. Moreover, we develop an enhanced version named EasyTrack++, which designs the center points interaction (CPI) strategy to reduce the ambiguous targets caused by the noise point cloud background information. The proposed EasyTrack and EasyTrack++ set a new state-of-the-art performance ($textbf{18%}$, $textbf{40%}$ and $textbf{3%}$ success gains) in KITTI, NuScenes, and Waymo while runing at textbf{52.6fps} with few parameters (textbf{1.3M}). The code will be available at https://github.com/KnightApple427/Easytrack.
Read more4/15/2024
🌐
0
OST: Efficient One-stream Network for 3D Single Object Tracking in Point Clouds
Xiantong Zhao, Yinan Han, Shengjing Tian, Jian Liu, Xiuping Liu
Although recent Siamese network-based trackers have achieved impressive perceptual accuracy for single object tracking in LiDAR point clouds, they usually utilized heavy correlation operations to capture category-level characteristics only, and overlook the inherent merit of arbitrariness in contrast to multiple object tracking. In this work, we propose a radically novel one-stream network with the strength of the instance-level encoding, which avoids the correlation operations occurring in previous Siamese network, thus considerably reducing the computational effort. In particular, the proposed method mainly consists of a Template-aware Transformer Module (TTM) and a Multi-scale Feature Aggregation (MFA) module capable of fusing spatial and semantic information. The TTM stitches the specified template and the search region together and leverages an attention mechanism to establish the information flow, breaking the previous pattern of independent textit{extraction-and-correlation}. As a result, this module makes it possible to directly generate template-aware features that are suitable for the arbitrary and continuously changing nature of the target, enabling the model to deal with unseen categories. In addition, the MFA is proposed to make spatial and semantic information complementary to each other, which is characterized by reverse directional feature propagation that aggregates information from shallow to deep layers. Extensive experiments on KITTI and nuScenes demonstrate that our method has achieved considerable performance not only for class-specific tracking but also for class-agnostic tracking with less computation and higher efficiency.
Read more6/10/2024
0
PillarTrack: Redesigning Pillar-based Transformer Network for Single Object Tracking on Point Clouds
Weisheng Xu, Sifan Zhou, Zhihang Yuan
LiDAR-based 3D single object tracking (3D SOT) is a critical issue in robotics and autonomous driving. It aims to obtain accurate 3D BBox from the search area based on similarity or motion. However, existing 3D SOT methods usually follow the point-based pipeline, where the sampling operation inevitably leads to redundant or lost information, resulting in unexpected performance. To address these issues, we propose PillarTrack, a pillar-based 3D single object tracking framework. Firstly, we transform sparse point clouds into dense pillars to preserve the local and global geometrics. Secondly, we introduce a Pyramid-type Encoding Pillar Feature Encoder (PE-PFE) design to help the feature representation of each pillar. Thirdly, we present an efficient Transformer-based backbone from the perspective of modality differences. Finally, we construct our PillarTrack tracker based above designs. Extensive experiments on the KITTI and nuScenes dataset demonstrate the superiority of our proposed method. Notably, our method achieves state-of-the-art performance on the KITTI and nuScenes dataset and enables real-time tracking speed. We hope our work could encourage the community to rethink existing 3D SOT tracker designs.We will open source our code to the research community in https://github.com/StiphyJay/PillarTrack.
Read more4/12/2024
📉
0
BEVTrack: A Simple and Strong Baseline for 3D Single Object Tracking in Bird's-Eye View
Yuxiang Yang, Yingqi Deng, Jing Zhang, Jiahao Nie, Zheng-Jun Zha
3D Single Object Tracking (SOT) is a fundamental task of computer vision, proving essential for applications like autonomous driving. It remains challenging to localize the target from surroundings due to appearance variations, distractors, and the high sparsity of point clouds. To address these issues, prior Siamese and motion-centric trackers both require elaborate designs and solving multiple subtasks. In this paper, we propose BEVTrack, a simple yet effective baseline method. By estimating the target motion in Bird's-Eye View (BEV) to perform tracking, BEVTrack demonstrates surprising simplicity from various aspects, i.e., network designs, training objectives, and tracking pipeline, while achieving superior performance. Besides, to achieve accurate regression for targets with diverse attributes (e.g., sizes and motion patterns), BEVTrack constructs the likelihood function with the learned underlying distributions adapted to different targets, rather than making a fixed Laplacian or Gaussian assumption as in previous works. This provides valuable priors for tracking and thus further boosts performance. While only using a single regression loss with a plain convolutional architecture, BEVTrack achieves state-of-the-art performance on three large-scale datasets, KITTI, NuScenes, and Waymo Open Dataset while maintaining a high inference speed of about 200 FPS. The code will be released at https://github.com/xmm-prio/BEVTrack.
Read more5/21/2024