Beyond Concept Bottleneck Models: How to Make Black Boxes Intervenable?

0

Sign in to get full access
Overview
- This paper introduces a new approach to making "black box" machine learning models more interpretable and intervenable.
- The authors propose a method called "Concept Intervention" that allows users to directly manipulate the internal representations of a model to achieve desired outputs.
- This builds on previous work on "Concept Bottleneck Models" which aim to make models more transparent by grounding them in human-understandable concepts.
- The key idea is to give users the ability to directly intervene on and edit the model's internal representation of important concepts, rather than just observing them.
Plain English Explanation
Machine learning models are often criticized as "black boxes" - complex systems whose inner workings are difficult for humans to understand. This can make it challenging to trust and reliably use these models, especially in high-stakes applications.
The authors of this paper have developed a new approach to address this issue. Their key insight is that if we can ground a model's internal representations in human-understandable "concepts", then we should be able to directly manipulate and edit those concepts to achieve desired model outputs. This builds on previous work on Concept Bottleneck Models, which aimed to make models more transparent by explicitly modeling key concepts.
The authors' "Concept Intervention" method allows users to directly edit a model's internal representations of important concepts, effectively "opening up the black box" and making the model more intervenable and controllable. For example, if the model has learned a concept of "dog", the user could directly adjust the strength of that concept to change the model's predictions.
This approach has the potential to make complex machine learning models more interpretable, trustworthy, and useful, especially in sensitive domains like healthcare or finance. By giving users more direct control over the model's inner workings, it may help address some of the key challenges around the "black box" nature of modern AI systems.
Technical Explanation
The core technical contribution of this paper is a new method called "Concept Intervention" that allows users to directly manipulate a model's internal representations of important concepts.
The authors build on the idea of Concept Bottleneck Models, which aim to ground a model's internal representations in human-understandable concepts. However, in previous work, users could only observe these concepts, not actively edit them.
In contrast, the "Concept Intervention" method gives users the ability to directly intervene on and adjust the strength of key concepts within the model. This is achieved through a specialized neural network architecture that separates the model's "concept" representations from its final predictive layer.
The authors demonstrate the effectiveness of this approach through a series of experiments on both synthetic and real-world datasets. They show that users are able to successfully edit the model's internal concept representations to achieve desired outputs, without significantly degrading overall model performance.
Additionally, the authors explore techniques for improving the efficacy of these interventions and incrementally updating the model to adapt to user edits, as well as making the concept representations more "editable" in the first place.
Critical Analysis
One key limitation of this work is that it still requires the model to have a pre-defined set of human-understandable concepts, which may not always be easy to identify or specify. The authors acknowledge this challenge and suggest that future work could explore methods for automatically discovering and defining these concepts.
Additionally, while the authors demonstrate the effectiveness of their approach on several datasets, it remains to be seen how well it would scale to larger, more complex models and real-world applications. Significant engineering challenges may arise when trying to deploy this technique in high-stakes, mission-critical systems.
Another potential concern is the risk of users unintentionally or maliciously editing the model in ways that lead to undesirable or harmful outcomes. The authors do not address this issue in depth, and it would be important to consider safeguards and best practices for responsible use of this technology.
Overall, this paper presents a promising step towards making black box machine learning models more interpretable and controllable. By giving users the ability to directly manipulate a model's internal representations, it has the potential to improve trust, transparency, and reliability in AI systems. However, further research and careful consideration of the technology's implications will be necessary to fully realize its benefits.
Conclusion
This paper introduces a novel approach called "Concept Intervention" that allows users to directly manipulate the internal representations of machine learning models, making them more interpretable and intervenable.
By building on the concept of "Concept Bottleneck Models", the authors have developed a way for users to edit the strength of key concepts within a model, effectively "opening up the black box" and giving them more control over the model's outputs.
This has significant implications for improving the trust, transparency, and reliability of complex AI systems, especially in high-stakes domains like healthcare and finance. While the approach still has some limitations and challenges to overcome, it represents an important step forward in making machine learning models more accessible and controllable for end users.
As AI systems become increasingly prevalent in our lives, techniques like Concept Intervention will be crucial for ensuring these technologies are deployed responsibly and in alignment with human values and needs. This paper lays the groundwork for further research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Concept Bottleneck Models: How to Make Black Boxes Intervenable?
Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Moritz Vandenhirtz, Julia E. Vogt
Recently, interpretable machine learning has re-explored concept bottleneck models (CBM). An advantage of this model class is the user's ability to intervene on predicted concept values, affecting the downstream output. In this work, we introduce a method to perform such concept-based interventions on pretrained neural networks, which are not interpretable by design, only given a small validation set with concept labels. Furthermore, we formalise the notion of intervenability as a measure of the effectiveness of concept-based interventions and leverage this definition to fine-tune black boxes. Empirically, we explore the intervenability of black-box classifiers on synthetic tabular and natural image benchmarks. We focus on backbone architectures of varying complexity, from simple, fully connected neural nets to Stable Diffusion. We demonstrate that the proposed fine-tuning improves intervention effectiveness and often yields better-calibrated predictions. To showcase the practical utility of our techniques, we apply them to deep chest X-ray classifiers and show that fine-tuned black boxes are more intervenable than CBMs. Lastly, we establish that our methods are still effective under vision-language-model-based concept annotations, alleviating the need for a human-annotated validation set.
Read more5/28/2024

0
AnyCBMs: How to Turn Any Black Box into a Concept Bottleneck Model
Gabriele Dominici, Pietro Barbiero, Francesco Giannini, Martin Gjoreski, Marc Langhenirich
Interpretable deep learning aims at developing neural architectures whose decision-making processes could be understood by their users. Among these techniqes, Concept Bottleneck Models enhance the interpretability of neural networks by integrating a layer of human-understandable concepts. These models, however, necessitate training a new model from the beginning, consuming significant resources and failing to utilize already trained large models. To address this issue, we introduce AnyCBM, a method that transforms any existing trained model into a Concept Bottleneck Model with minimal impact on computational resources. We provide both theoretical and experimental insights showing the effectiveness of AnyCBMs in terms of classification performances and effectivenss of concept-based interventions on downstream tasks.
Read more5/28/2024
🔄
0
Learning to Intervene on Concept Bottlenecks
David Steinmann, Wolfgang Stammer, Felix Friedrich, Kristian Kersting
While deep learning models often lack interpretability, concept bottleneck models (CBMs) provide inherent explanations via their concept representations. Moreover, they allow users to perform interventional interactions on these concepts by updating the concept values and thus correcting the predictive output of the model. Up to this point, these interventions were typically applied to the model just once and then discarded. To rectify this, we present concept bottleneck memory models (CB2Ms), which keep a memory of past interventions. Specifically, CB2Ms leverage a two-fold memory to generalize interventions to appropriate novel situations, enabling the model to identify errors and reapply previous interventions. This way, a CB2M learns to automatically improve model performance from a few initially obtained interventions. If no prior human interventions are available, a CB2M can detect potential mistakes of the CBM bottleneck and request targeted interventions. Our experimental evaluations on challenging scenarios like handling distribution shifts and confounded data demonstrate that CB2Ms are able to successfully generalize interventions to unseen data and can indeed identify wrongly inferred concepts. Hence, CB2Ms are a valuable tool for users to provide interactive feedback on CBMs, by guiding a user's interaction and requiring fewer interventions.
Read more6/5/2024
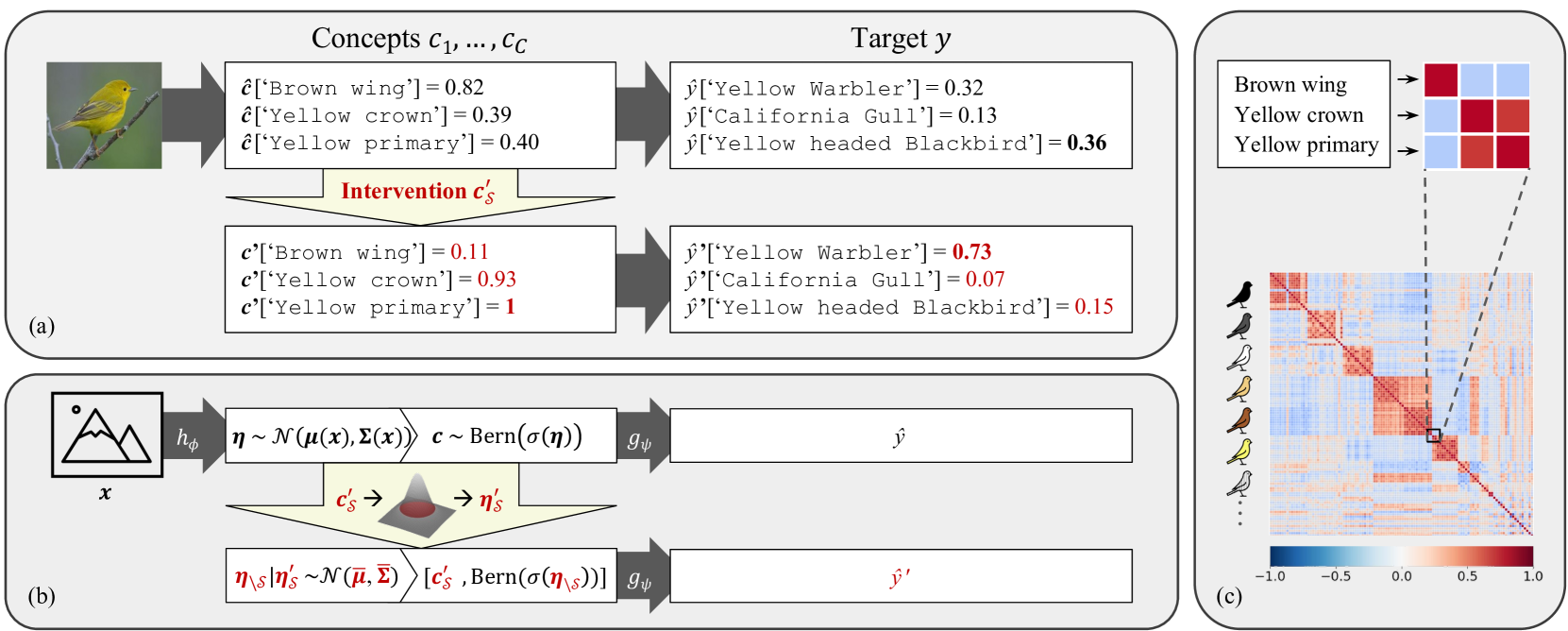
0
Stochastic Concept Bottleneck Models
Moritz Vandenhirtz, Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Julia E. Vogt
Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Read more6/28/2024